atari
1.0.0

Исследовательская площадка, построенная на базе Atari Gym от OpenAI, подготовленная для реализации различных алгоритмов обучения с подкреплением.
Он может эмулировать любую из следующих игр:
['Астерикс', 'Астероиды', 'MsPacman', 'Кабум', 'BankHeist', 'Кенгуру', 'Лыжи', 'FishingDerby', 'Крулл', 'Берзерк', 'Тутанхам', 'Заксон', ' Венчур», «Риверрейд», «Мороконожка», «Приключение», «БимРайдер», «CrazyClimber», «TimePilot», «Carnival», «Tennis», «Seaquest», «Bowling», «SpaceInvaders», «Freeway», «YarsRevenge», «RoadRunner», «JourneyEscape», «WizardOfWor», «Gopher» ', 'Побег', 'Старганнер', 'Атлантида', «DoubleDunk», «Hero», «BattleZone», «Solaris», «UpNDown», «Frostbite», «KungFuMaster», «Pooyan», «Pitfall», «MontezumaRevenge», «PrivateEye», «AirRaid», «Amidar» ', 'Роботанк', 'Атака демонов', 'Защитник', «NameThisGame», «Феникс», «Гравитар», «ElevatorAction», «Понг», «ВидеоПинбол», «Хоккей на льду», «Бокс», «Нападение», «Чужой», «Кберт», «Эндуро», «ChopperCommand» ', 'Джеймсбонд']
Ознакомьтесь с соответствующей статьей Medium: Atari — углубленное обучение с подкреплением? (Часть 1: ДДКН)
Конечная цель этого проекта — реализовать и сравнить различные подходы RL с играми Atari как общим знаменателем.
pip install -r requirements.txt .python atari.py --help . * GAMMA = 0.99
* MEMORY_SIZE = 900000
* BATCH_SIZE = 32
* TRAINING_FREQUENCY = 4
* TARGET_NETWORK_UPDATE_FREQUENCY = 40000
* MODEL_PERSISTENCE_UPDATE_FREQUENCY = 10000
* REPLAY_START_SIZE = 50000
* EXPLORATION_MAX = 1.0
* EXPLORATION_MIN = 0.1
* EXPLORATION_TEST = 0.02
* EXPLORATION_STEPS = 850000
Глубокая сверточная нейронная сеть от DeepMind
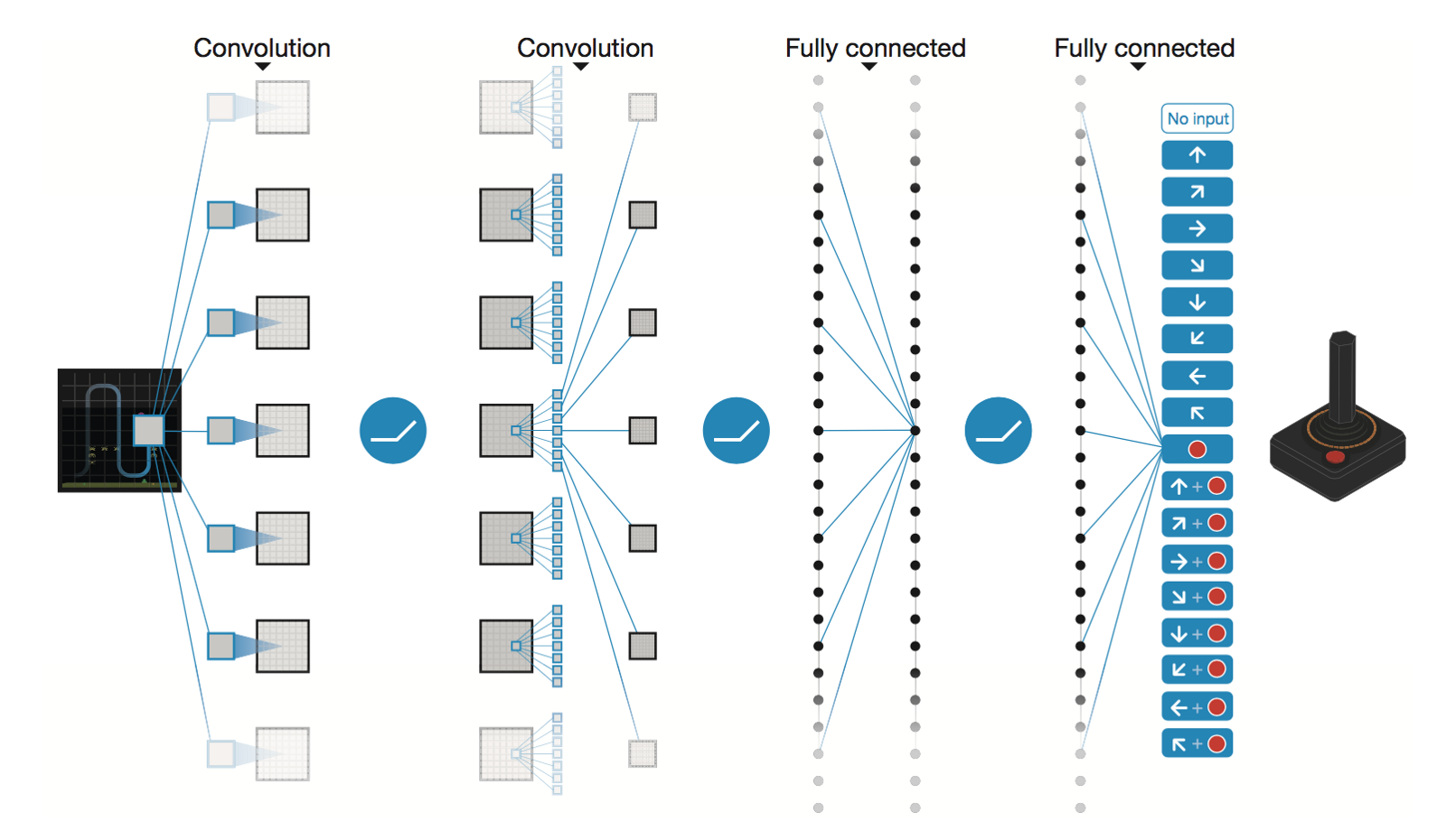
* Conv2D (None, 32, 20, 20)
* Conv2D (None, 64, 9, 9)
* Conv2D (None, 64, 7, 7)
* Flatten (None, 3136)
* Dense (None, 512)
* Dense (None, 4)
Trainable params: 1,686,180
После 5 миллионов шагов ( ~40 часов на графическом процессоре Tesla K80 или ~90 часов на четырехъядерном процессоре Intel i7 с частотой 2,9 ГГц):
Обучение:
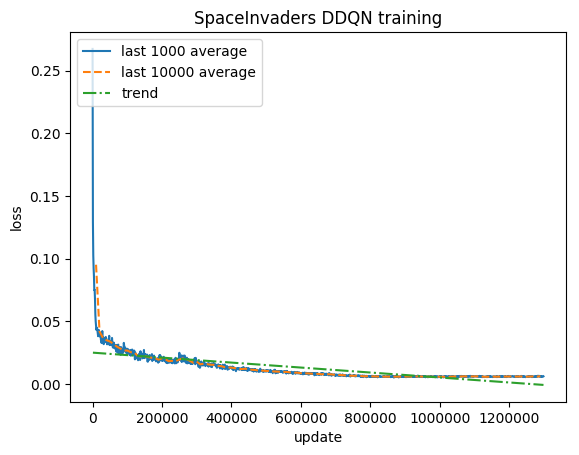
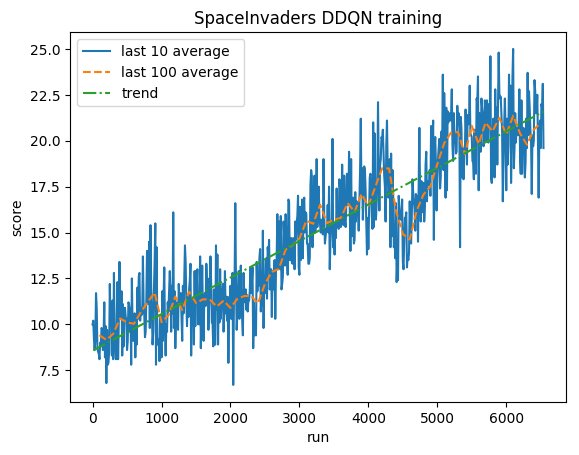
Нормализованный балл — каждая награда ограничена до (-1, 1)
Тестирование:
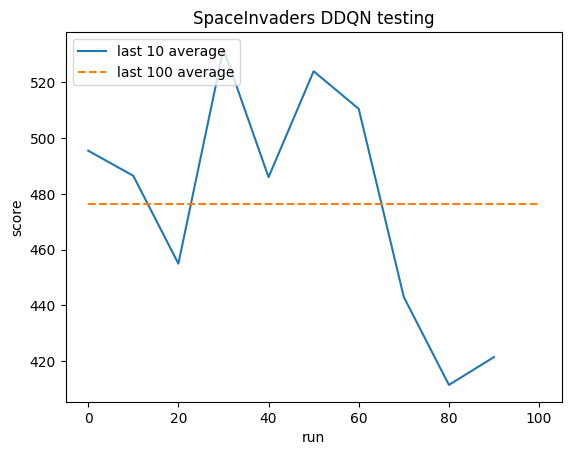
Среднее значение для человека: ~372
Среднее значение DDQN: ~479 (128%)
Обучение:
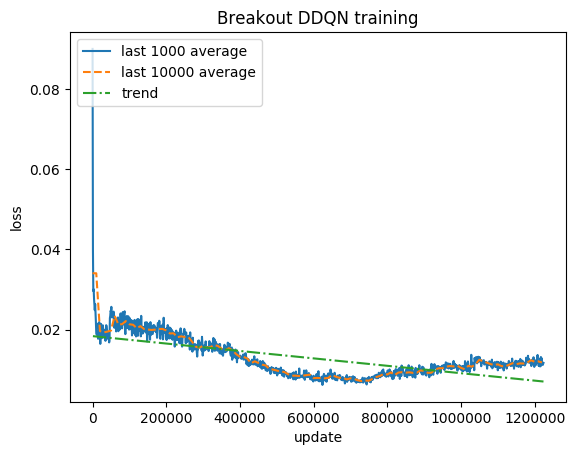
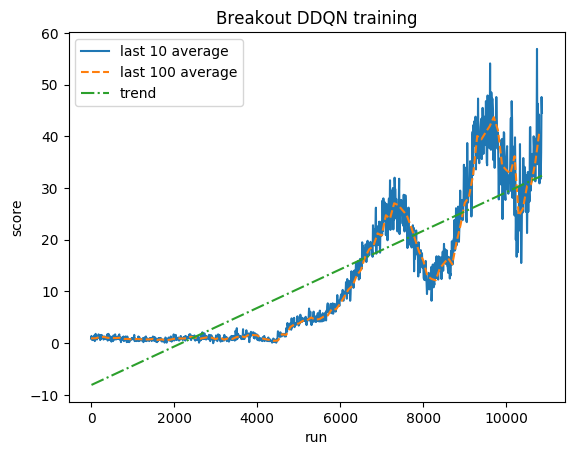
Нормализованный балл — каждая награда ограничена до (-1, 1)
Тестирование:
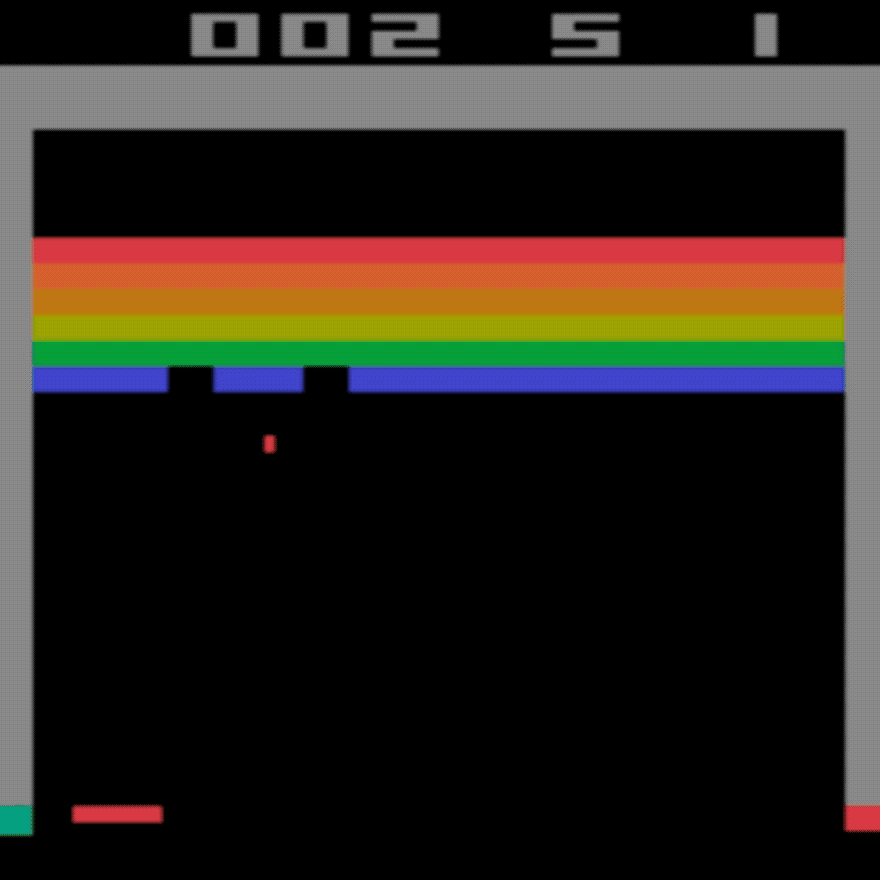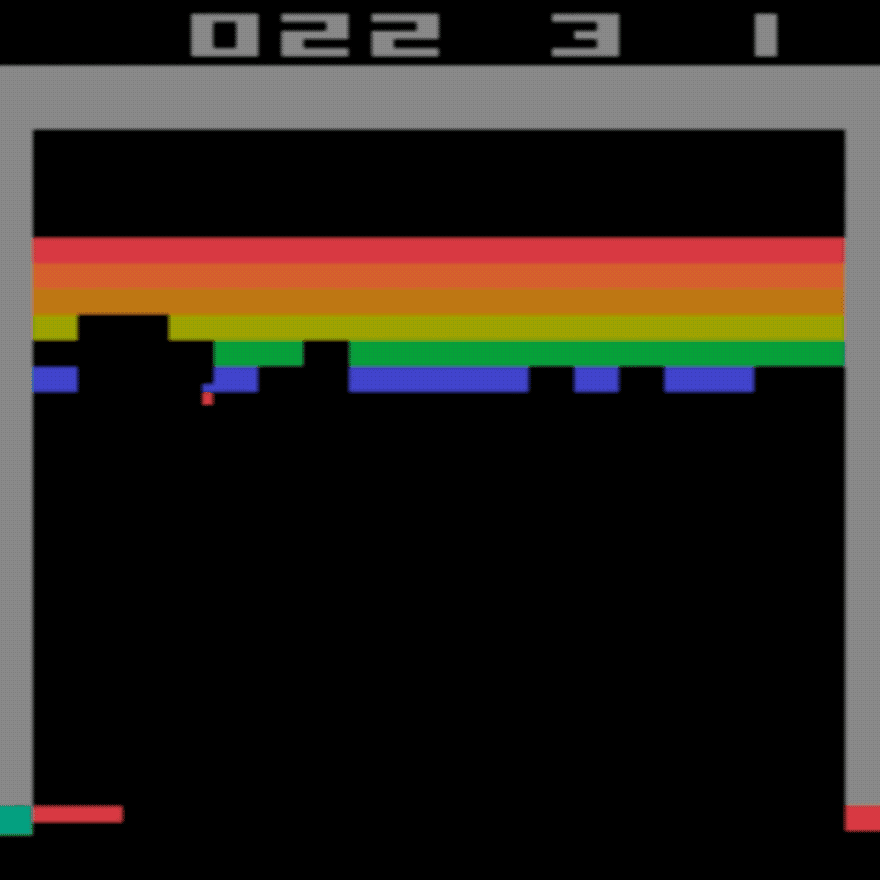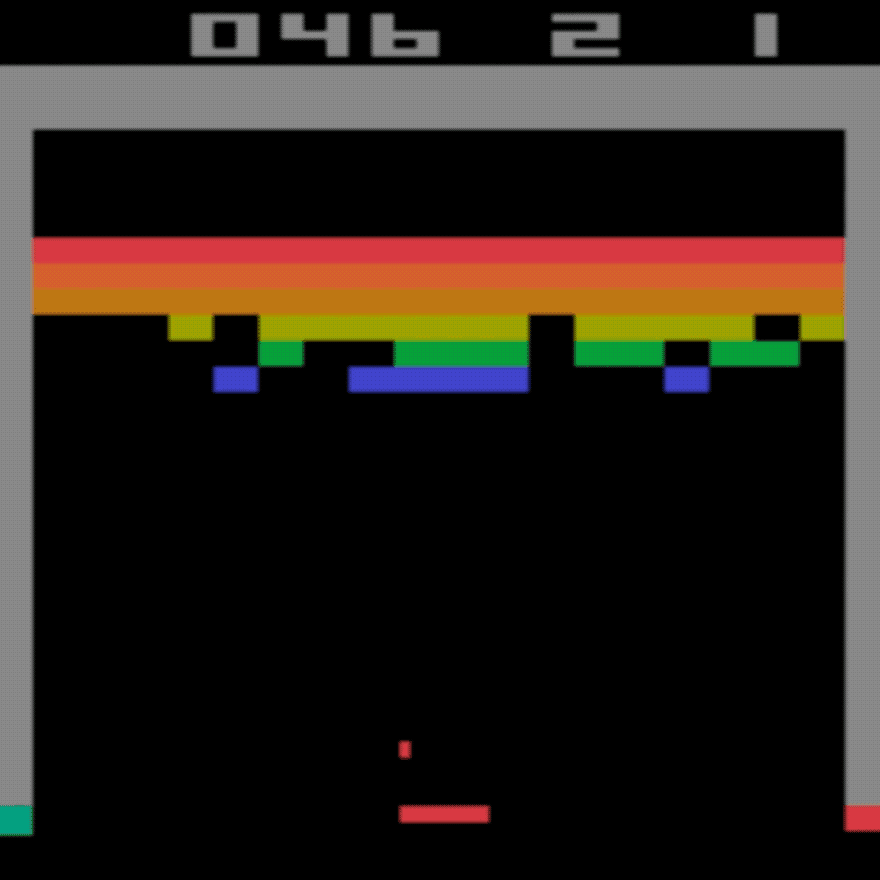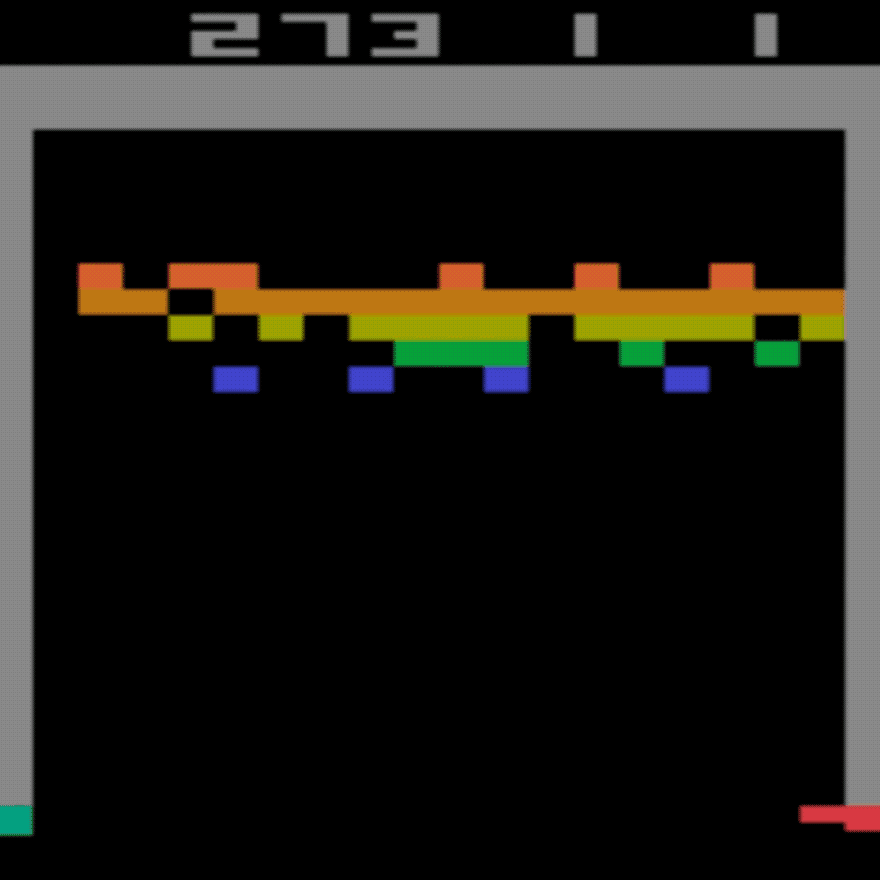
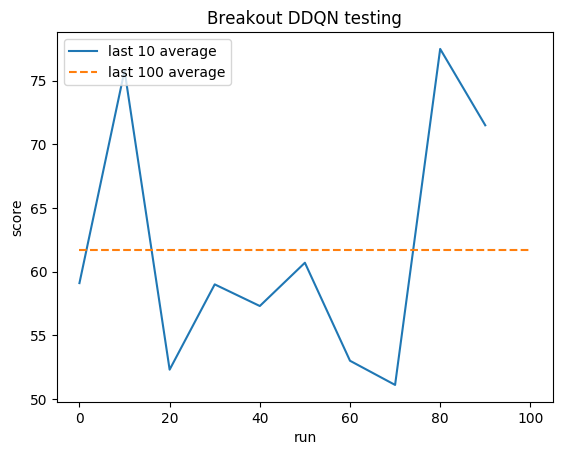
Среднее значение для человека: ~28
Среднее значение DDQN: ~62 (221%)
Обучение:
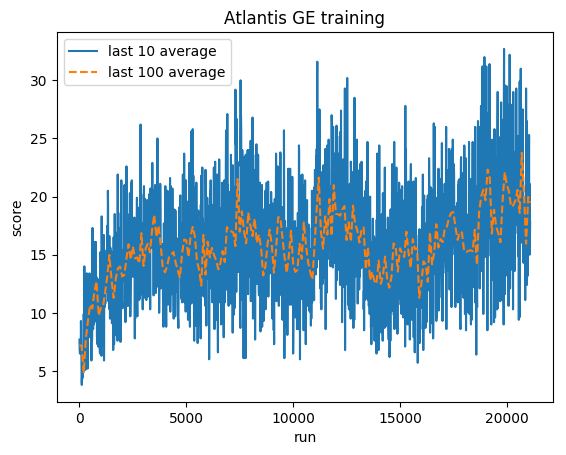
Нормализованный балл — каждая награда ограничена до (-1, 1)
Тестирование:

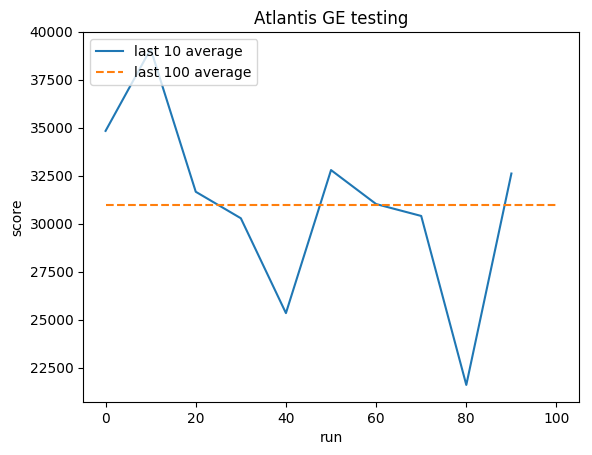
В среднем по человеку: ~29 000
Средний балл GE: 31 000 (106%)
Грег (Гжегож) Сурма
ПОРТФЕЛЬ
ГИТХАБ
БЛОГ


