LongNet
0.4.8

Это реализация с открытым исходным кодом статьи LongNet: масштабирование трансформаторов до 1 000 000 000 токенов Цзяю Дина, Шуминга Ма, Ли Донга, Синсин Чжана, Шаохана Хуана, Вэньхуэй Вана, Фуру Вэй. LongNet — это вариант Transformer, предназначенный для масштабирования длины последовательности до более чем 1 миллиарда токенов без ущерба для производительности на более коротких последовательностях.
pip install longnet После установки LongNet вы можете использовать класс DilatedAttention следующим образом:
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerПолностью готовая к обучению модель трансформатора с расширенными трансформаторными блоками с Feedforward, Layernorm, SWIGLU и параллельным трансформаторным блоком.
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
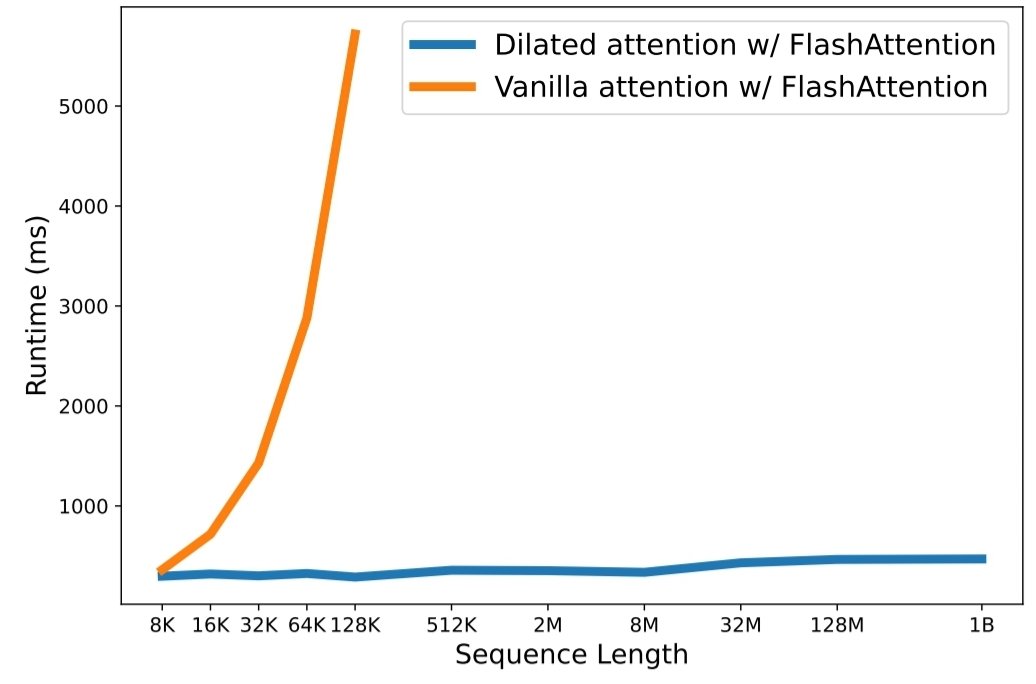
python3 train.py Масштабирование длины последовательности стало критическим узким местом в эпоху больших языковых моделей. Однако существующие методы имеют проблемы либо с вычислительной сложностью, либо с выразительностью модели, что ограничивает максимальную длину последовательности. В этой статье они представляют LongNet, вариант Transformer, который может масштабировать длину последовательности до более чем 1 миллиарда токенов, не жертвуя при этом производительностью на более коротких последовательностях. В частности, они предлагают расширенное внимание, которое экспоненциально расширяет поле внимания по мере увеличения расстояния.
LongNet имеет существенные преимущества:
Результаты экспериментов показывают, что LongNet обеспечивает высокую производительность как при моделировании длинных последовательностей, так и при решении общеязыковых задач. Их работа открывает новые возможности для моделирования очень длинных последовательностей, например, рассмотрения целого корпуса или даже всего Интернета как последовательности.
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

