igel
v1.0.0
Восхитительный инструмент машинного обучения, который позволяет обучать/подгонять, тестировать и использовать модели без написания кода.
Примечание
Я также работаю над настольным приложением с графическим интерфейсом для igel, основываясь на запросах людей. Вы можете найти его в разделе Igel-UI.
Оглавление
Цель проекта — предоставить машинное обучение всем , как техническим, так и нетехническим пользователям.
Иногда мне нужен был инструмент, который я мог бы использовать для быстрого создания прототипа машинного обучения. Нужно ли построить какое-то доказательство концепции, создать быстрый черновик модели, чтобы доказать свою точку зрения, или использовать автоматическое машинное обучение. Я часто застреваю в написании шаблонного кода и слишком много думаю, с чего начать. Поэтому я решил создать этот инструмент.
igel построен на основе других платформ машинного обучения. Он обеспечивает простой способ использования машинного обучения без написания единой строки кода . Igel обладает широкими возможностями настройки , но только если вы этого хотите. Игель не заставляет вас что-либо настраивать. Помимо значений по умолчанию, igel может использовать функции автоматического мл, чтобы определить модель, которая будет отлично работать с вашими данными.
Все, что вам нужно, это файл yaml (или json ), в котором вам нужно описать, что вы пытаетесь сделать. Вот и все!
Игель поддерживает регрессию, классификацию и кластеризацию. Igel's поддерживает функции автоматического мл, такие как ImageClassification и TextClassification.
Igel поддерживает наиболее используемые типы наборов данных в области науки о данных. Например, ваш входной набор данных может быть файлом csv, txt, excel, json или даже html, который вы хотите получить. Если вы используете функции автоматического мл, вы даже можете передать необработанные данные в igel, и он выяснит, как с ними справиться. Подробнее об этом далее в примерах.
$ pip install -U igel Поддерживаемые модели Igel:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+Для авто ML:
Команда help очень полезна для проверки поддерживаемых команд и соответствующих аргументов/опций.
$ igel --helpВы также можете вызвать справку по подкомандам, например:
$ igel fit --helpИгель обладает широкими возможностями настройки. Если вы знаете, чего хотите, и хотите настроить свою модель вручную, ознакомьтесь со следующими разделами, которые помогут вам написать файл конфигурации yaml или json. После этого вам просто нужно сказать igel, что делать и где найти ваши данные и файл конфигурации. Вот пример:
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'Однако вы также можете использовать функции автоматического мл и позволить igel сделать все за вас. Отличным примером может служить классификация изображений. Предположим, у вас уже есть набор данных необработанных изображений, хранящийся в папке images.
Все, что вам нужно сделать, это запустить:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationВот и все! Игель прочитает изображения из каталога, обработает набор данных (преобразование в матрицы, изменение масштаба, разделение и т. д.) и начнет обучение/оптимизацию модели, которая хорошо работает с вашими данными. Как видите, это довольно просто: вам просто нужно указать путь к вашим данным и задачу, которую вы хотите выполнить.
Примечание
Эта функция требует больших вычислительных затрат, поскольку Айгелу придется пробовать множество разных моделей и сравнивать их производительность, чтобы найти «лучшую».
Вы можете запустить команду help, чтобы получить инструкции. Вы также можете запустить справку по подкомандам!
$ igel --helpПервый шаг — предоставить файл yaml (при желании вы также можете использовать json).
Вы можете сделать это вручную, создав файл .yaml (по соглашению называемый igel.yaml, но вы можете назвать его по своему усмотрению) и отредактировав его самостоятельно. Однако, если вы ленивы (а вы, вероятно, ленивы, как и я :D), вы можете использовать команду igel init, чтобы быстро начать работу, которая мгновенно создаст для вас базовый файл конфигурации.
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initПосле выполнения команды в текущем рабочем каталоге для вас будет создан файл igel.yaml. Вы можете проверить его и изменить, если хотите, иначе вы также можете создать все с нуля.
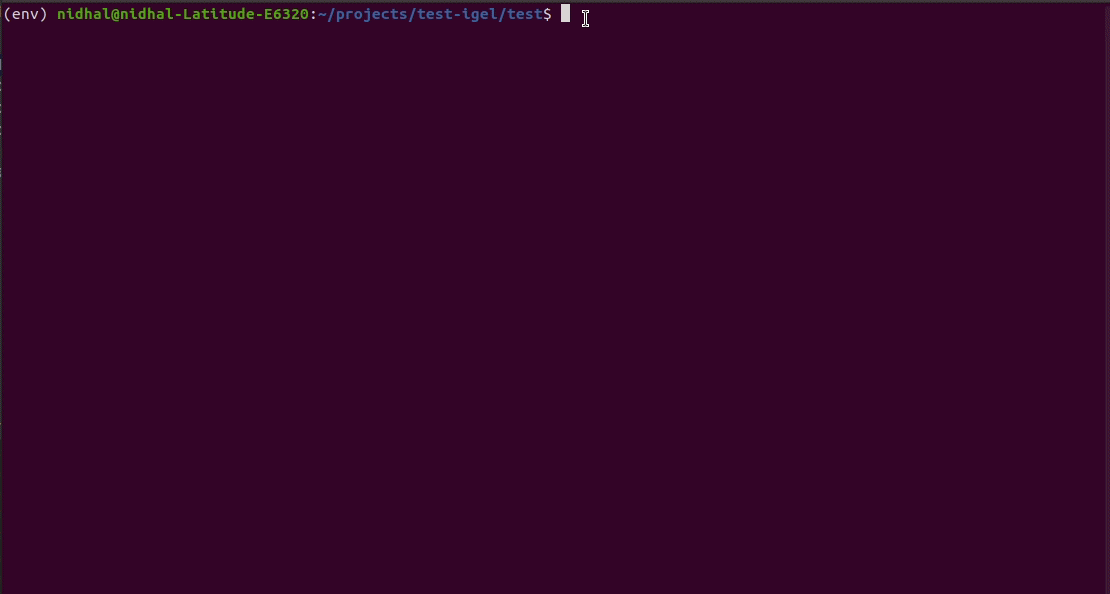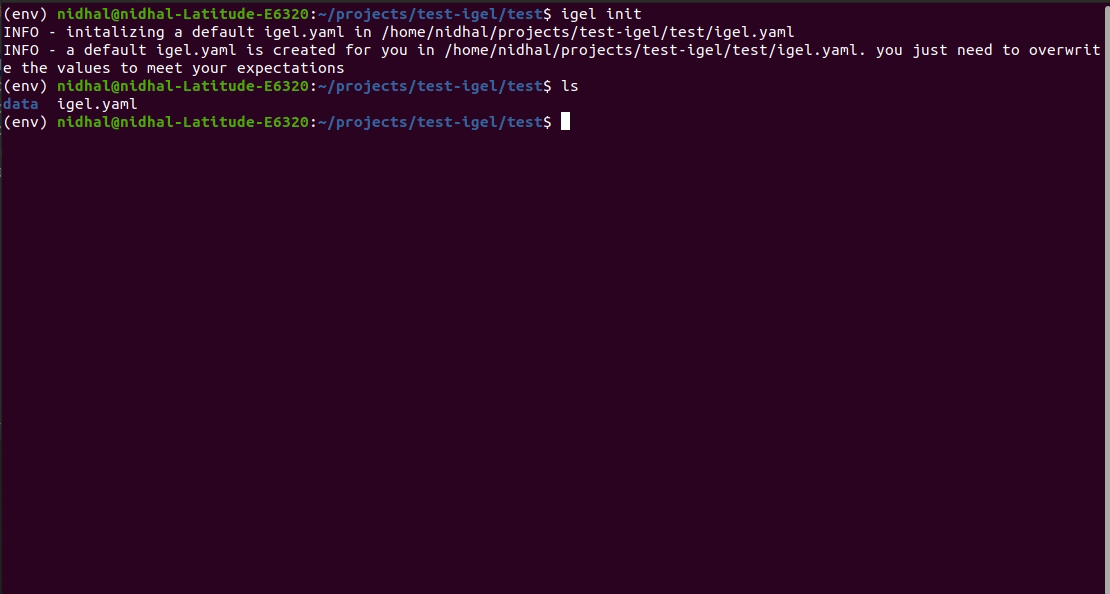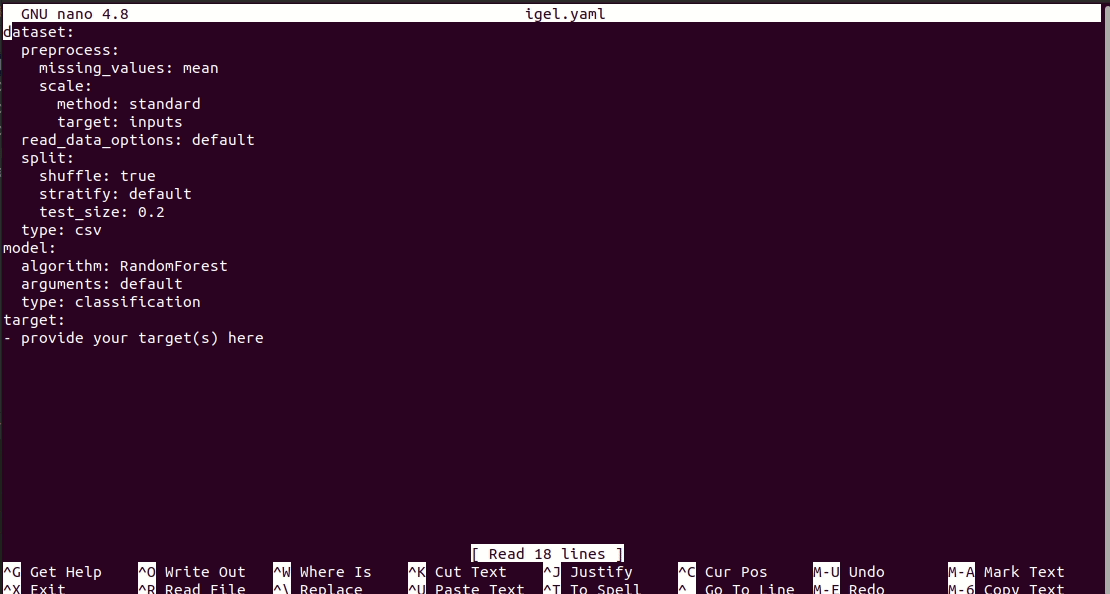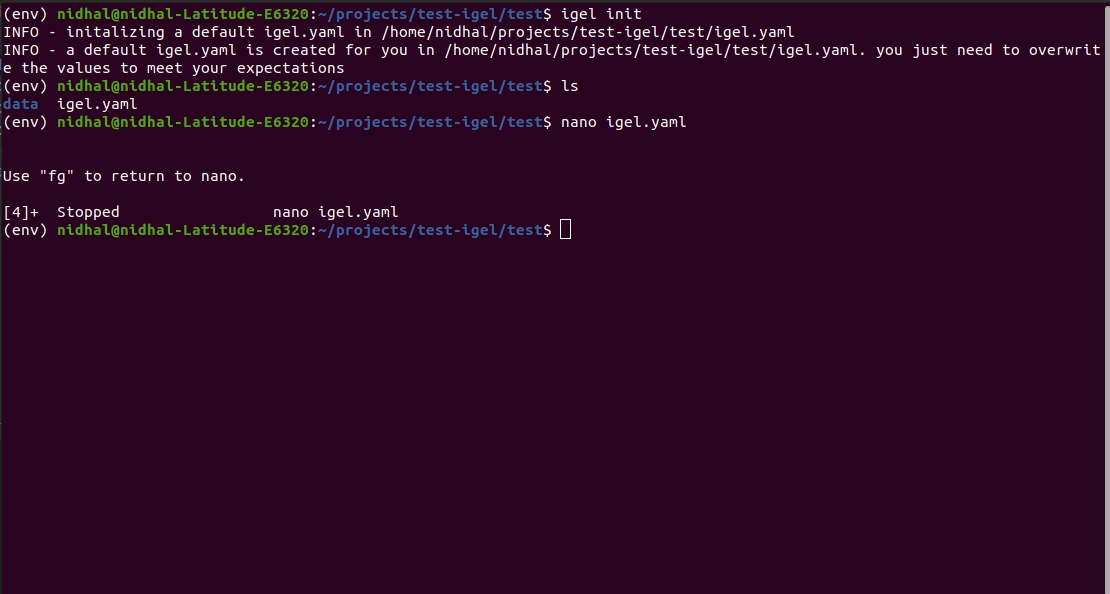
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sickВ приведенном выше примере я использую случайный лес, чтобы классифицировать, есть ли у кого-то диабет или нет, в зависимости от некоторых особенностей набора данных. В этом примере набора данных об индийском диабете я использовал знаменитый индийский диабет)
Обратите внимание, что я передал n_estimators и max_depth в качестве дополнительных аргументов модели. Если вы не предоставите аргументы, будет использовано значение по умолчанию. Вам не нужно запоминать аргументы для каждой модели. Вы всегда можете запустить igel models в своем терминале, что переведет вас в интерактивный режим, где вам будет предложено ввести модель, которую вы хотите использовать, и тип проблемы, которую вы хотите решить. Затем Игель покажет вам информацию о модели и ссылку, по которой вы можете перейти, чтобы увидеть список доступных аргументов и способы их использования.
Запустите эту команду в терминале, чтобы подогнать/обучить модель, где вы указываете путь к вашему набору данных и путь к файлу yaml.
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
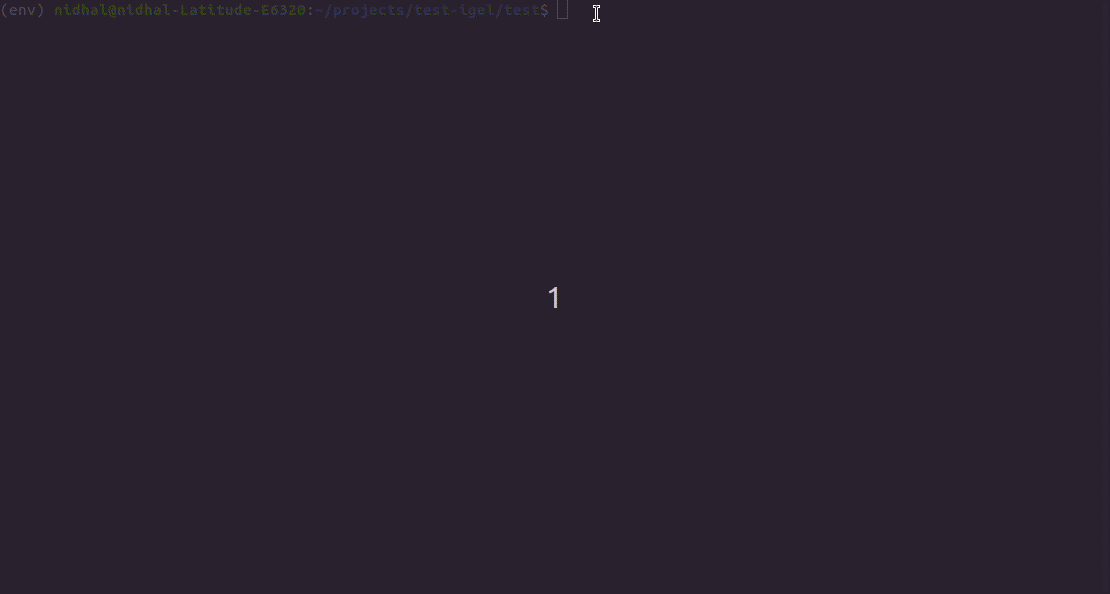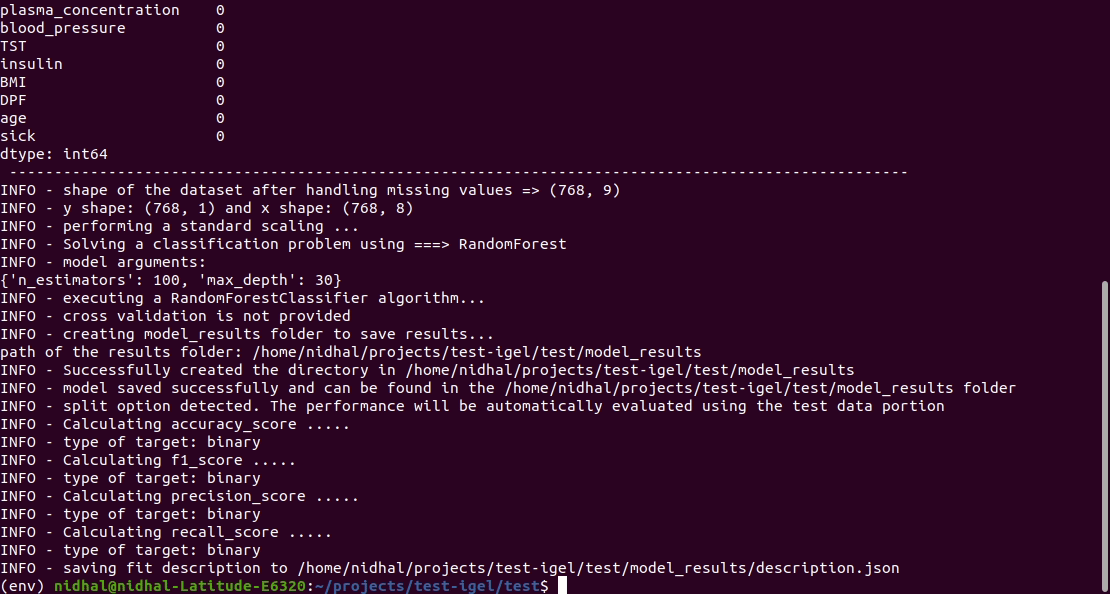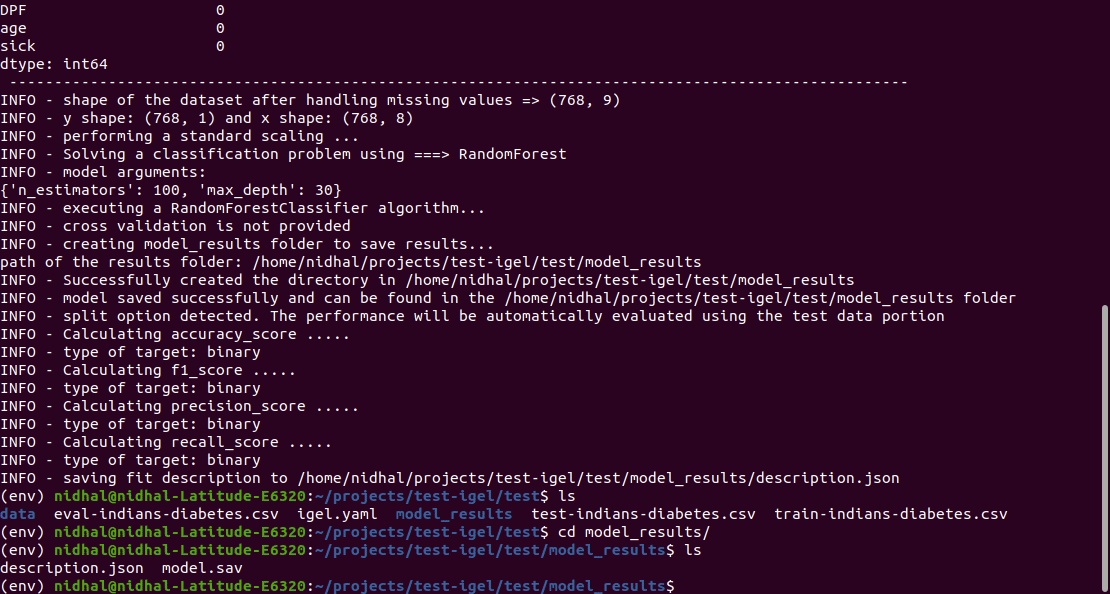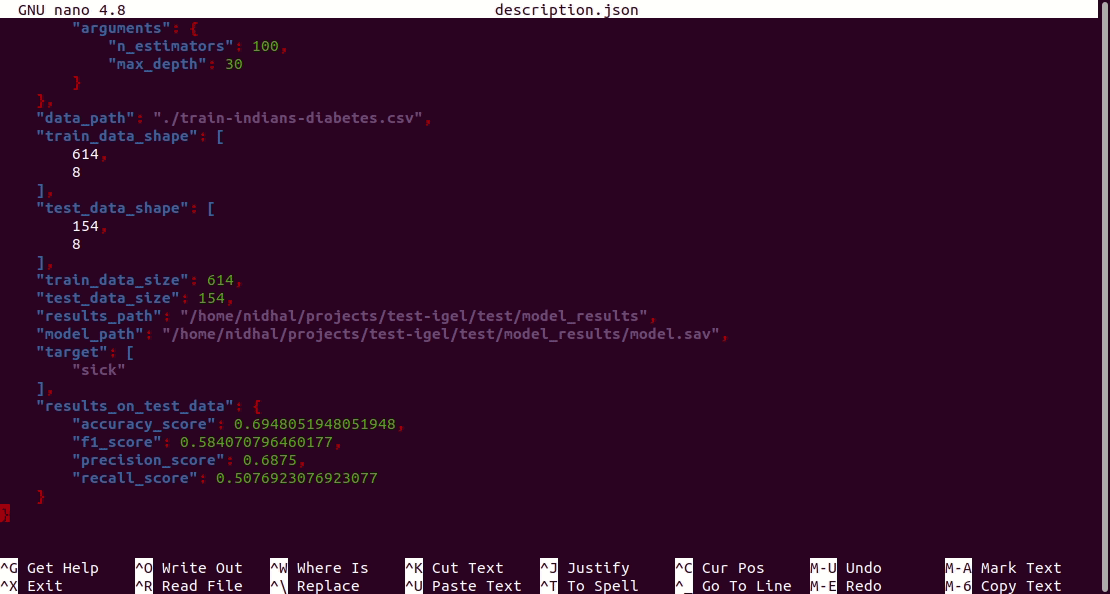
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
Затем вы можете оценить обученную/предварительно настроенную модель:
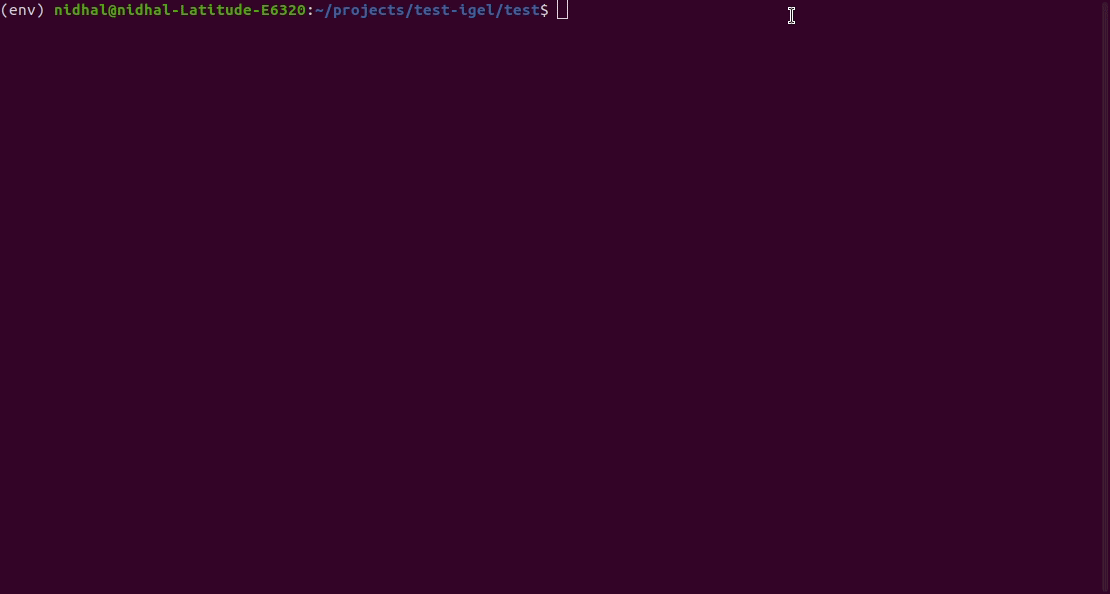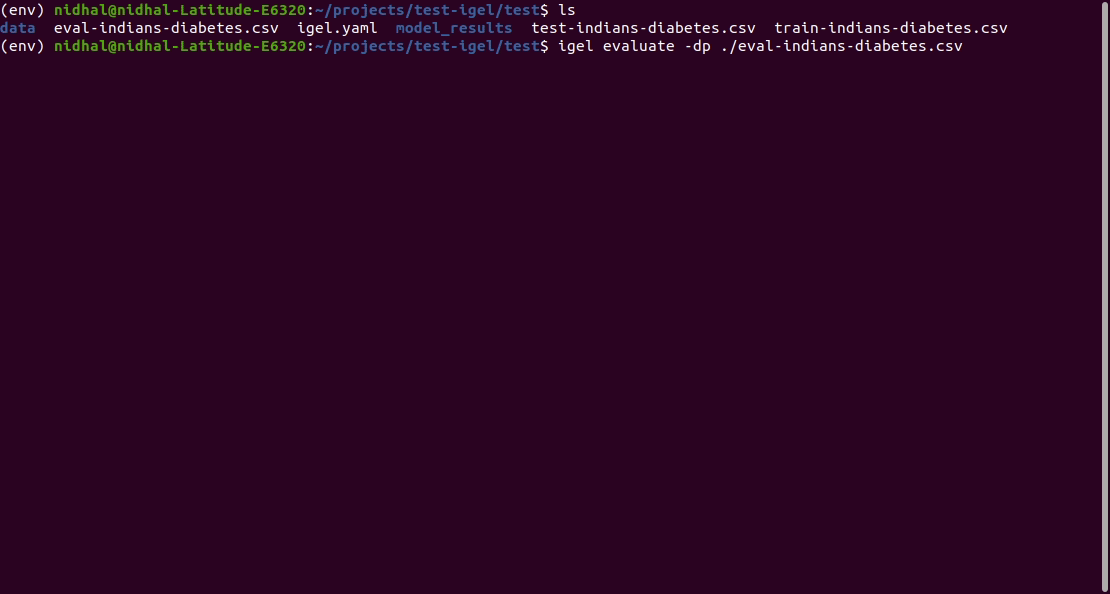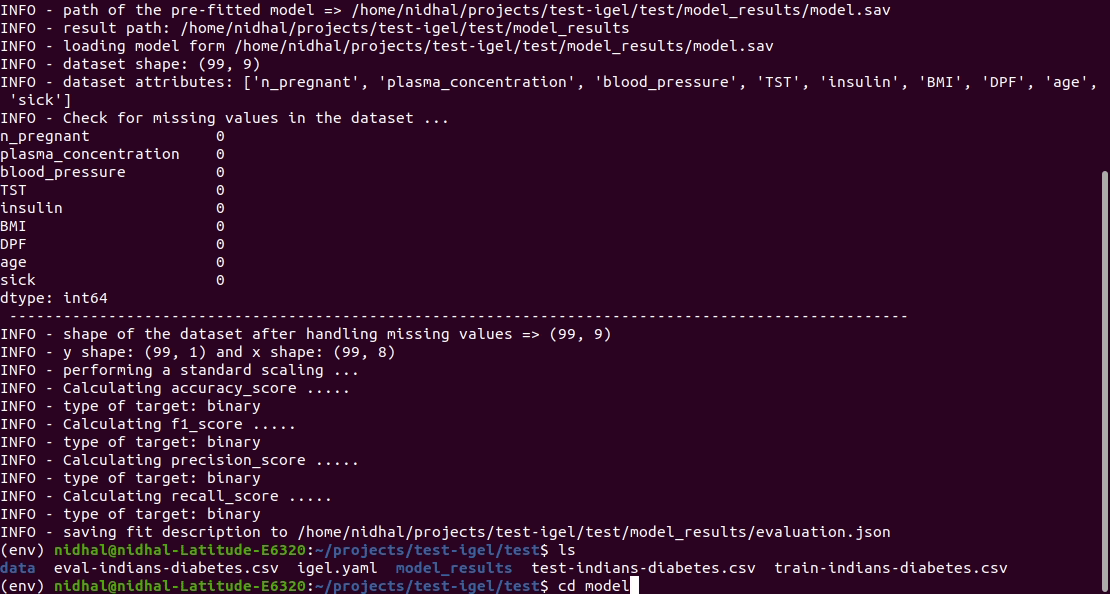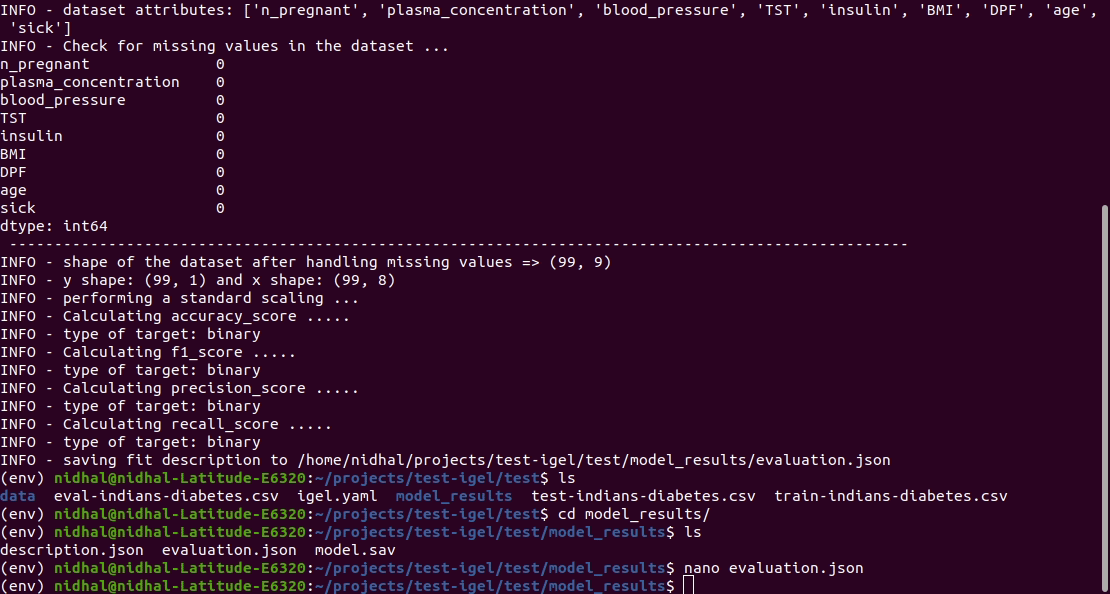
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
Наконец, вы можете использовать обученную/предварительно настроенную модель для прогнозирования, если вас устраивают результаты оценки:
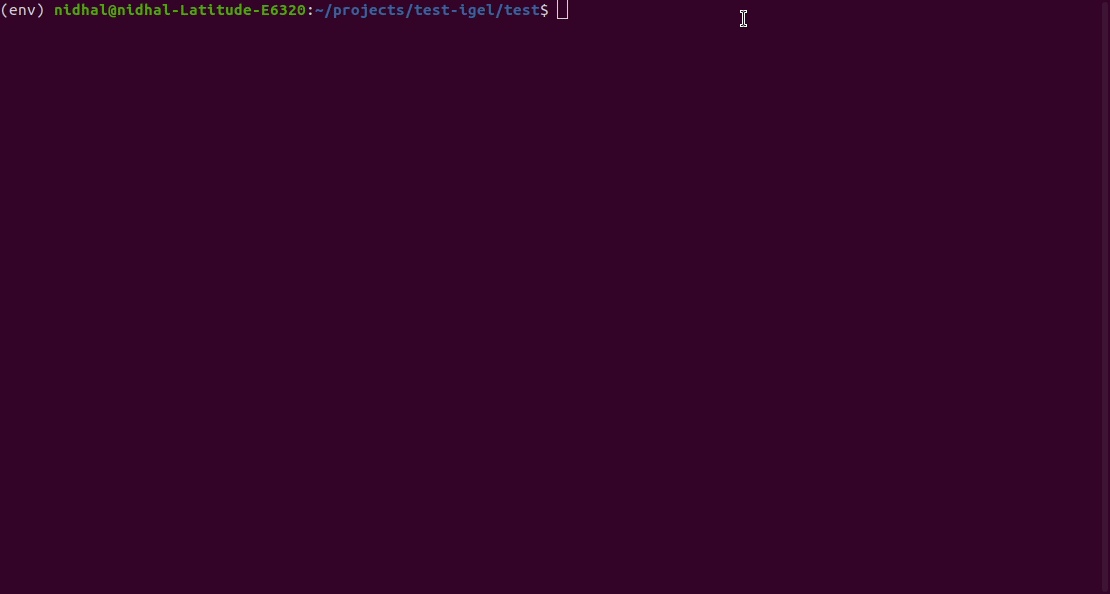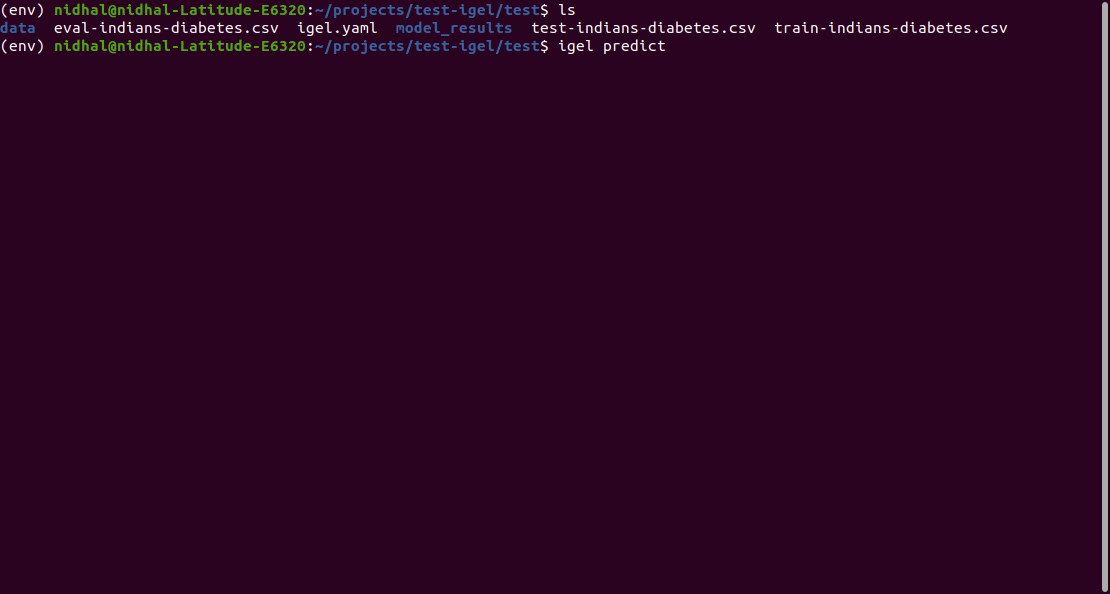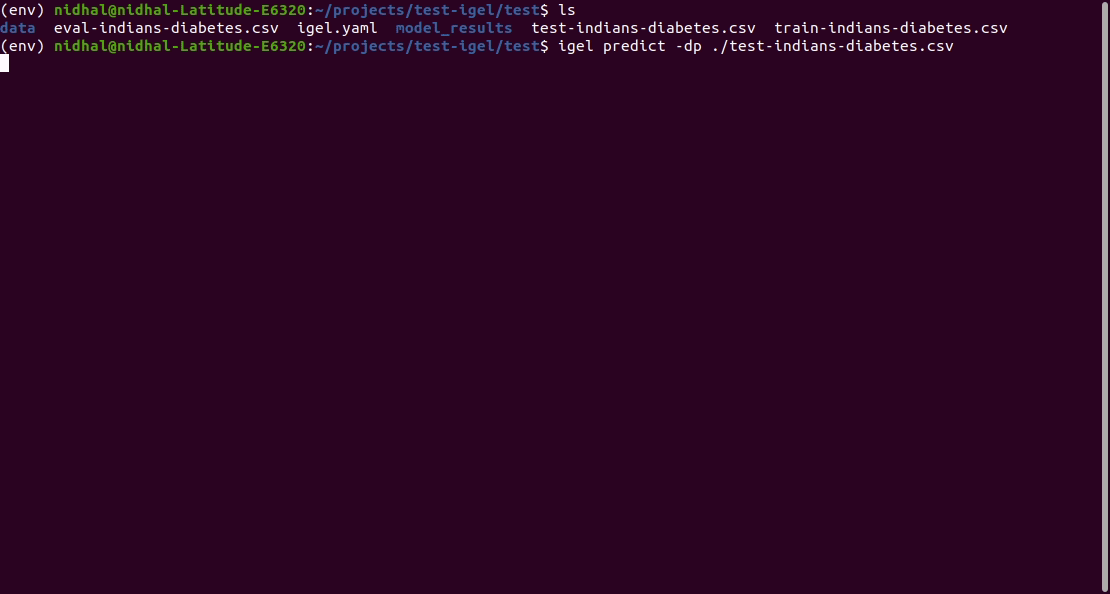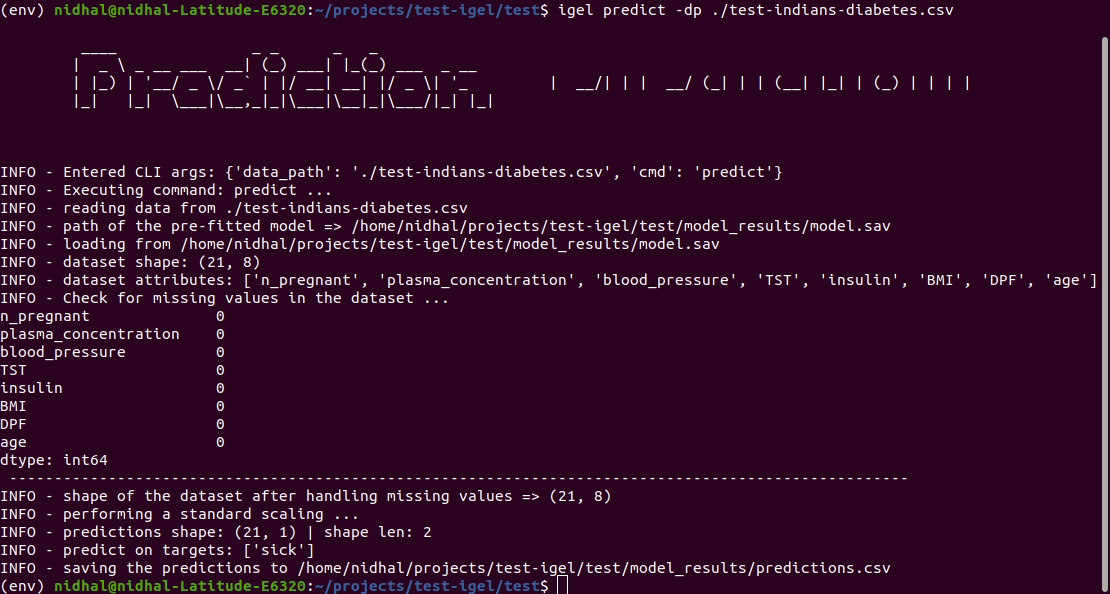
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
Вы можете комбинировать этапы обучения, оценки и прогнозирования, используя одну команду под названием «эксперимент»:
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
Вы можете экспортировать обученную/предварительно настроенную модель sklearn в ONNX:
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""Следующий шаг — использовать вашу модель в производстве. Игель также поможет вам с этой задачей, предоставив команду подачи. Запуск команды «serve» сообщит igel обслужить вашу модель. Точнее, igel автоматически создаст REST-сервер и будет обслуживать вашу модель на определенном хосте и порту, которые вы можете настроить, передав их в качестве параметров командной строки.
Самый простой способ — запустить:
$ igel serve --model_results_dir " path_to_model_results_directory "Обратите внимание, что igel требуется опция --model_results_dir или, сокращенно, -res_dir, чтобы загрузить модель и запустить сервер. По умолчанию igel будет обслуживать вашу модель на localhost:8000 , однако вы можете легко переопределить это, указав параметры хоста и порта cli.
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Игель использует FastAPI для создания REST-сервера, который представляет собой современную высокопроизводительную среду, и uvicorn для его скрытого запуска.
Этот пример был выполнен с использованием предварительно обученной модели (созданной путем запуска классификации типов больных igel init --target) и набора данных по индийскому диабету в разделе примеры/данные. Заголовки столбцов в исходном CSV-файле: «preg», «plas», «pres», «skin», «test», «mass», «pedi» и «возраст».
КУЛОН:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}Предостережения/ограничения:
Пример использования клиента Python:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}Основная цель igel — предоставить вам возможность обучать/подгонять, оценивать и использовать модели без написания кода. Вместо этого все, что вам нужно, это предоставить/описать то, что вы хотите сделать, в простом файле yaml.
По сути, вы предоставляете описание или, скорее, конфигурации в файле yaml в виде пар ключ-значение. Вот обзор всех поддерживаемых конфигураций (на данный момент):
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction Примечание
igel использует pandas под капотом для чтения и анализа данных. Следовательно, вы можете найти дополнительные параметры этих данных также в официальной документации pandas.
Подробный обзор конфигураций, которые вы можете предоставить в файле yaml (или json), приведен ниже. Обратите внимание, что вам определенно не понадобятся все значения конфигурации для набора данных. Они не являются обязательными. Как правило, igel сам выяснит, как читать ваш набор данных.
Однако вы можете помочь этому, предоставив дополнительные поля в разделе read_data_options. Например, на мой взгляд, одним из полезных значений является «sep», который определяет, как разделяются столбцы в наборе данных CSV. Обычно наборы данных CSV разделяются запятыми, что также является значением по умолчанию. Однако в вашем случае он может быть разделен точкой с запятой.
Следовательно, вы можете указать это в read_data_options. Просто добавьте sep: ";" в разделе read_data_options.
| Параметр | Тип | Объяснение |
|---|---|---|
| сентябрь | ул, по умолчанию ',' | Разделитель, который нужно использовать. Если sep имеет значение None, механизм C не может автоматически обнаружить разделитель, но механизм синтаксического анализа Python может, то есть последний будет использоваться и автоматически обнаруживать разделитель с помощью встроенного инструмента анализа Python, csv.Sniffer. Кроме того, разделители длиной более 1 символа и отличные от «s+» будут интерпретироваться как регулярные выражения и также заставят использовать механизм синтаксического анализа Python. Обратите внимание, что разделители регулярных выражений склонны игнорировать данные в кавычках. Пример регулярного выражения: 'rt'. |
| разделитель | по умолчанию Нет | Псевдоним на сентябрь. |
| заголовок | int, список целых чисел, «вывод» по умолчанию | Номера строк, которые будут использоваться в качестве имен столбцов, и начало данных. Поведение по умолчанию заключается в выводе имен столбцов: если имена не передаются, поведение идентично заголовку = 0, а имена столбцов выводятся из первой строки файла. Если имена столбцов передаются явно, то поведение идентично заголовку = нет. . Явно передайте header=0, чтобы иметь возможность заменить существующие имена. Заголовок может представлять собой список целых чисел, определяющих расположение строк для мультииндекса в столбцах, например [0,1,3]. Промежуточные строки, которые не указаны, будут пропущены (например, 2 в этом примере пропускаются). Обратите внимание, что этот параметр игнорирует строки с комментариями и пустые строки, если Skip_blank_lines=True, поэтому заголовок=0 обозначает первую строку данных, а не первую строку файла. |
| имена | массивоподобный, необязательный | Список имен столбцов, которые будут использоваться. Если файл содержит строку заголовка, вам следует явно передать header=0, чтобы переопределить имена столбцов. Дубликаты в этом списке не допускаются. |
| индекс_столбец | int, str, последовательность int/str или False, по умолчанию Нет | Столбцы для использования в качестве меток строк DataFrame, заданные как имя строки или индекс столбца. Если указана последовательность int/str, используется MultiIndex. Примечание. index_col=False можно использовать, чтобы заставить pandas не использовать первый столбец в качестве индекса, например, если у вас есть некорректный файл с разделителями в конце каждой строки. |
| использование коллов | в виде списка или вызываемого, необязательно | Вернуть подмножество столбцов. Если они похожи на список, все элементы должны быть либо позиционными (т. е. целочисленными индексами в столбцах документа), либо строками, которые соответствуют именам столбцов, предоставленным пользователем в именах или выведенным из строк заголовка документа. Например, допустимым параметром usecols в виде списка будет [0, 1, 2] или ['foo', 'bar', 'baz']. Порядок элементов игнорируется, поэтому usecols=[0, 1] совпадает с [1, 0]. Чтобы создать экземпляр DataFrame из данных с сохраненным порядком элементов, используйте pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] для столбцов в ['foo', 'bar'] '] order или pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] для ['bar', 'foo'] заказ. Если вызываемая функция может быть вызвана, она будет оцениваться по именам столбцов, возвращая имена, в которых вызываемая функция оценивается как True. Примером допустимого вызываемого аргумента может быть лямбда x: x.upper() в ['AAA', 'BBB', 'DDD']. Использование этого параметра приводит к гораздо более быстрому анализу и меньшему использованию памяти. |
| сжимать | bool, по умолчанию False | Если проанализированные данные содержат только один столбец, верните серию. |
| префикс | ул, необязательно | Префикс для добавления к номерам столбцов при отсутствии заголовка, например «X» для X0, X1,… |
| mangle_dupe_cols | bool, по умолчанию True | Повторяющиеся столбцы будут обозначаться как «X», «X.1», … «X.N», а не «X»… «X». Передача False приведет к перезаписи данных, если в столбцах есть повторяющиеся имена. |
| dtype | {'c', 'python'}, необязательно | Используемый парсер. Движок C работает быстрее, а движок Python в настоящее время более функционален. |
| преобразователи | диктовка, необязательно | Диктовка функций для преобразования значений в определенных столбцах. Ключи могут быть целыми числами или метками столбцов. |
| истинные_значения | список, необязательно | Значения, которые следует считать истинными. |
| false_values | список, необязательно | Значения, которые следует считать ложными. |
| пропустить начальное пространство | bool, по умолчанию False | Пропускать пробелы после разделителя. |
| пропуски | в виде списка, int или вызываемый, необязательный | Номера строк, которые нужно пропустить (с индексом 0), или количество строк, которые нужно пропустить (int) в начале файла. Если вызываемая функция доступна для вызова, она будет оцениваться по индексам строк, возвращая True, если строку следует пропустить, и False в противном случае. Примером допустимого вызываемого аргумента может быть лямбда x: x в [0, 2]. |
| скипфутер | целое число, по умолчанию 0 | Количество строк в конце файла, которые нужно пропустить (не поддерживается с engine='c'). |
| строки | целое, необязательно | Количество строк файла для чтения. Полезно для чтения фрагментов больших файлов. |
| na_values | скаляр, строка, список или dict, необязательно | Дополнительные строки, распознаваемые как NA/NaN. Если dict пройден, конкретные значения NA для каждого столбца. По умолчанию следующие значения интерпретируются как NaN: '', '#N/A', '#N/AN/A', '#NA', '-1.#IND', '-1.#QNAN', '-NaN', '-nan', '1.#IND', '1.#QNAN', '<NA>', 'N/A', 'NA', 'NULL', 'NaN', 'n /а', «нан», «ноль». |
| Keep_default_na | bool, по умолчанию True | Следует ли включать значения NaN по умолчанию при анализе данных. В зависимости от того, передано ли значение na_values, поведение будет следующим: Если параметр Keep_default_na имеет значение True и указаны значения na_values, значение na_values добавляется к значениям NaN по умолчанию, используемым для анализа. Если параметр Keep_default_na имеет значение True и na_values не указаны, для анализа используются только значения NaN по умолчанию. Если параметр Keep_default_na имеет значение False и указаны значения na_values, для анализа используются только значения NaN, указанные в параметре na_values. Если параметр Keep_default_na имеет значение False и значения na_values не указаны, строки не будут анализироваться как NaN. Обратите внимание: если параметру na_filter присвоено значение False, параметры Keep_default_na и na_values будут игнорироваться. |
| na_filter | bool, по умолчанию True | Обнаружение маркеров отсутствующих значений (пустые строки и значения na_values). В данных без каких-либо NA передача na_filter=False может повысить производительность чтения большого файла. |
| многословный | bool, по умолчанию False | Укажите количество значений NA, помещенных в нечисловые столбцы. |
| Skip_blank_lines | bool, по умолчанию True | Если значение True, пропускайте пустые строки, а не интерпретируйте их как значения NaN. |
| parse_dates | bool или список int или имен или список списков или dict, по умолчанию False | Поведение следующее: логическое значение. Если True -> попробуйте проанализировать индекс. список целых чисел или имен. например, если [1, 2, 3] -> попробуйте проанализировать столбцы 1, 2, 3 каждый как отдельный столбец даты. список списков. например, если [[1, 3]] -> объединить столбцы 1 и 3 и проанализировать как один столбец даты. dict, например {'foo': [1, 3]} -> анализировать столбцы 1, 3 как дату и вызывать результат 'foo'. Если столбец или индекс не могут быть представлены как массив дат и времени, скажем, из-за неразбираемого значения или смесь часовых поясов, столбец или индекс будут возвращены без изменений как тип данных объекта. |
| infer_datetime_format | bool, по умолчанию False | Если включены True и parse_dates, pandas попытается определить формат строк даты и времени в столбцах, и если это возможно, переключится на более быстрый метод их анализа. В некоторых случаях это может увеличить скорость парсинга в 5-10 раз. |
| Keep_date_col | bool, по умолчанию False | Если True и parse_dates указывают объединение нескольких столбцов, сохраните исходные столбцы. |
| date_parser | функция, опционально | Функция, используемая для преобразования последовательности строковых столбцов в массив экземпляров даты и времени. По умолчанию для преобразования используется dateutil.parser.parser. Pandas попытается вызвать date_parser тремя разными способами, переходя к следующему в случае возникновения исключения: 1) передать один или несколько массивов (как определено в parse_dates) в качестве аргументов; 2) объединить (по строкам) строковые значения из столбцов, определенных parse_dates, в один массив и передать его; и 3) вызвать date_parser один раз для каждой строки, используя одну или несколько строк (соответствующих столбцам, определенным в parse_dates) в качестве аргументов. |
| первый день | bool, по умолчанию False | Даты в формате ДД/ММ, международный и европейский формат. |
| кэш_даты | bool, по умолчанию True | Если принимает значение True, используйте кэш уникальных преобразованных дат, чтобы применить преобразование даты и времени. Может значительно ускорить анализ повторяющихся строк даты, особенно со смещением часового пояса. |
| тысячи | ул, необязательно | Разделитель тысяч. |
| десятичный | ул, по умолчанию '.' | Знак, распознаваемый как десятичная точка (например, используйте ',' для европейских данных). |
| ограничитель строки | ул (длина 1), необязательно | Символ для разбиения файла на строки. Действует только с парсером C. |
| escapechar | ул (длина 1), необязательно | Односимвольная строка, используемая для экранирования других символов. |
| комментарий | ул, необязательно | Указывает, что оставшаяся часть строки не должна анализироваться. Если найдено в начале строки, строка будет полностью проигнорирована. |
| кодирование | ул, необязательно | Кодировка, используемая для UTF при чтении/записи (например, «utf-8»). |
| диалект | str или csv.Диалект, необязательно | Если этот параметр указан, он переопределит значения (по умолчанию или нет) для следующих параметров: разделитель, двойная кавычка, escapechar, Skipinitialspace, Quotechar и кавычки. |
| low_memory | bool, по умолчанию True | Внутренняя обработка файла частями, что приводит к меньшему использованию памяти при синтаксическом анализе, но, возможно, к выводу смешанного типа. Чтобы гарантировать отсутствие смешанных типов, установите False или укажите тип с помощью параметра dtype. Обратите внимание, что весь файл считывается в один DataFrame независимо от того, |
| карта_памяти | bool, по умолчанию False | сопоставьте файловый объект непосредственно с памятью и получите доступ к данным непосредственно оттуда. Использование этой опции может повысить производительность, поскольку больше нет накладных расходов на ввод-вывод. |
В этом разделе представлено полное комплексное решение, подтверждающее возможности igel . Как объяснялось ранее, вам необходимо создать файл конфигурации yaml. Вот комплексный пример прогнозирования того, есть ли у кого-то диабет или нет, с использованием алгоритма дерева решений . Набор данных можно найти в папке примеров.
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileВот и все, теперь igel подберет для вас модель и сохранит ее в папке model_results в вашем текущем каталоге.
Оцените предварительно установленную модель. Игель загрузит предварительно настроенную модель из каталога model_results и оценит ее за вас. Вам просто нужно запустить команду оценки и указать путь к вашим данным оценки.
$ igel evaluate -dp path_to_the_evaluation_datasetВот и все! Игель оценит модель и сохранит статистику/результаты в файле Assessment.json в папке model_results.
Используйте предварительно настроенную модель для прогнозирования новых данных. Igel делает это автоматически, вам просто нужно указать путь к вашим данным, для которых вы хотите использовать прогноз.
$ igel predict -dp path_to_the_new_datasetВот и все! Игель будет использовать предварительно настроенную модель для прогнозирования и сохранит ее в файле Predictions.csv в папке model_results.
Вы также можете выполнить некоторые методы предварительной обработки или другие операции, указав их в файле yaml. Вот пример, где данные разделены на 80 % для обучения и 20 % для проверки/тестирования. Кроме того, данные перемешиваются при разделении.
Кроме того, данные предварительно обрабатываются путем замены пропущенных значений средним значением (вы также можете использовать медиану, режим и т. д.). проверьте эту ссылку для получения дополнительной информации
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sickЗатем вы можете подогнать модель, запустив команду igel, как показано в других примерах.
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileДля оценки
$ igel evaluate -dp path_to_the_evaluation_datasetДля производства
$ igel predict -dp path_to_the_new_dataset В папке примеров в репозитории вы найдете папку данных, в которой хранятся знаменитые наборы данных по индийскому диабету, радужной оболочке и наборы данных линнеруда (из sklearn). Кроме того, в каждой папке есть сквозные примеры со сценариями и файлами yaml, которые помогут вам начать работу.
В папке indian-diabetes-example содержатся два примера, которые помогут вам начать работу:
Папка iris-example содержит пример логистической регрессии , в котором некоторая предварительная обработка (одно горячее кодирование) выполняется для целевого столбца, чтобы показать вам больше возможностей igel.
Кроме того, пример с несколькими выходами содержит пример регрессии с несколькими выходами . Наконец, пример cv содержит пример использования классификатора Ridge с использованием перекрестной проверки.
В папке вы также можете найти примеры перекрестной проверки и поиска по гиперпараметрам.
Я предлагаю вам поиграть с примерами и igel cli. Однако вы также можете напрямую выполнить fit.py, Assessment.py и Predict.py, если хотите.
Сначала создайте или измените набор данных изображений, которые разбиты на подпапки на основе метки/класса изображения. Например, если у вас есть изображения собак и кошек, вам понадобятся 2 подпапки:
Предполагая, что эти две подпапки содержатся в одной родительской папке под названием images, просто передайте данные в igel:
$ igel auto-train -dp ./images --task ImageClassificationИгель возьмет на себя все: от предварительной обработки данных до оптимизации гиперпараметров. В конце лучшая модель будет сохранена в текущем рабочем каталоге.
Сначала создайте или измените набор текстовых данных, которые разбиты на подпапки на основе текстовой метки/класса. Например, если у вас есть набор текстовых данных с положительными и отрицательными отзывами, вам понадобятся 2 подпапки:
Предполагая, что эти две подпапки содержатся в одной родительской папке под названием texts, просто передайте данные в igel:
$ igel auto-train -dp ./texts --task TextClassificationИгель возьмет на себя все: от предварительной обработки данных до оптимизации гиперпараметров. В конце лучшая модель будет сохранена в текущем рабочем каталоге.
Вы также можете запустить пользовательский интерфейс igel, если вы не знакомы с терминалом. Просто установите igel на свой компьютер, как указано выше. Затем запустите эту единственную команду в своем терминале
$ igel guiЭто откроет графический интерфейс, который очень прост в использовании. Посмотрите примеры того, как выглядит графический интерфейс и как его использовать, здесь: https://github.com/nidhaloff/igel-ui.
Вы можете сначала получить изображение из Docker Hub.
$ docker pull nidhaloff/igelЗатем используйте его:
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv 'Вы можете запустить igel внутри докера, сначала создав образ:
$ docker build -t igel .А затем запустите его и прикрепите текущий каталог (не обязательно к каталогу igel) как /data (рабочий каталог) внутри контейнера:
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' Если у вас возникли какие-либо проблемы, пожалуйста, не стесняйтесь открыть вопрос. Кроме того, вы можете связаться с автором для получения дополнительной информации/вопросов.
Тебе нравится Игель? Вы всегда можете помочь развитию этого проекта:
Вы считаете этот проект полезным и хотите привнести новые идеи, новые функции, исправления ошибок, расширить документацию?
Взносы всегда приветствуются. Обязательно сначала прочтите рекомендации
Лицензия MIT
Copyright (c) 2020 – настоящее время, Нидхал Баккури


