soundstorm pytorch
0.5.0
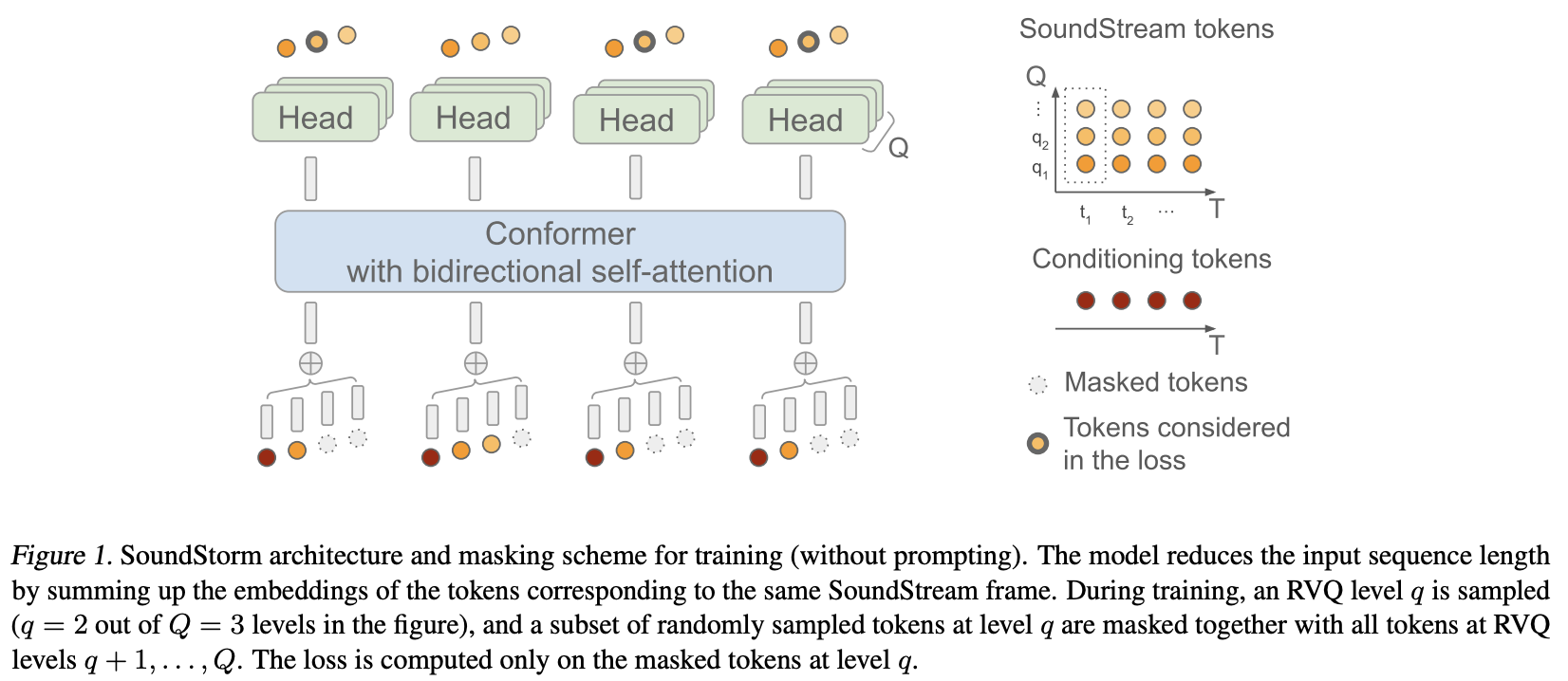
Реализация SoundStorm, эффективной параллельной генерации звука от Google Deepmind, в Pytorch.
По сути, они применили MaskGiT к остаточным векторно-квантованным кодам из Soundstream. Архитектура преобразователя, которую они выбрали, хорошо подходит для аудио-области и получила название Conformer.
Страница проекта
Стабильность и ? Huggingface за щедрую спонсорскую поддержку в работе над передовыми исследованиями в области искусственного интеллекта с открытым исходным кодом.
Лукасу Ньюману за многочисленные вклады, включая начальный обучающий код, логику акустических подсказок и поуровневое декодирование квантователя!
? Accelerate за предоставление простого и мощного решения для обучения
Эйнопсу за незаменимую абстракцию, которая делает создание нейронных сетей увлекательным, простым и воодушевляющим занятием.
Стивену Хиллису за предоставленную правильную стратегию маскировки и за проверку работоспособности репозитория!
Лукасу Ньюману за обучение небольшой работающей Soundstorm с использованием моделей из нескольких репозиториев и демонстрацию непрерывной работы. Модели включают SoundStream, Text-to-Semantic T5 и, наконец, преобразователь SoundStorm.
@Jiang-Stan за обнаружение критической ошибки в итеративной демаскировке!
$ pip install soundstorm-pytorch import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
model = SoundStorm (
conformer ,
steps = 18 , # 18 steps, as in original maskgit paper
schedule = 'cosine' # currently the best schedule is cosine
)
# get your pre-encoded codebook ids from the soundstream from a lot of raw audio
codes = torch . randint ( 0 , 1024 , ( 2 , 1024 , 12 )) # (batch, seq, num residual VQ)
# do the below in a loop for a ton of data
loss , _ = model ( codes )
loss . backward ()
# model can now generate in 18 steps. ~2 seconds sounds reasonable
generated = model . generate ( 1024 , batch_size = 2 ) # (2, 1024) Чтобы напрямую тренироваться на необработанном аудио, вам необходимо передать предварительно обученный SoundStream в SoundStorm . Вы можете обучить свой собственный SoundStream на audiolm-pytorch.
import torch
from soundstorm_pytorch import SoundStorm , ConformerWrapper , Conformer , SoundStream
conformer = ConformerWrapper (
codebook_size = 1024 ,
num_quantizers = 12 ,
conformer = dict (
dim = 512 ,
depth = 2
),
)
soundstream = SoundStream (
codebook_size = 1024 ,
rq_num_quantizers = 12 ,
attn_window_size = 128 ,
attn_depth = 2
)
model = SoundStorm (
conformer ,
soundstream = soundstream # pass in the soundstream
)
# find as much audio you'd like the model to learn
audio = torch . randn ( 2 , 10080 )
# course it through the model and take a gazillion tiny steps
loss , _ = model ( audio )
loss . backward ()
# and now you can generate state-of-the-art speech
generated_audio = model . generate ( seconds = 30 , batch_size = 2 ) # generate 30 seconds of audio (it will calculate the length in seconds based off the sampling frequency and cumulative downsamples in the soundstream passed in above) Полное преобразование текста в речь будет зависеть от обученного преобразователя кодера/декодера TextToSemantic . Затем вы загрузите веса и передадите их в SoundStorm как spear_tts_text_to_semantic
Эта работа находится в стадии разработки, поскольку spear-tts-pytorch имеет завершенную только архитектуру модели, а не логику предварительного обучения + псевдомаркировки + обратного перевода.
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic (
dim = 512 ,
source_depth = 12 ,
target_depth = 12 ,
num_text_token_ids = 50000 ,
num_semantic_token_ids = 20000 ,
use_openai_tokenizer = True
)
# load the trained text-to-semantic transformer
text_to_semantic . load ( '/path/to/trained/model.pt' )
# pass it into the soundstorm
model = SoundStorm (
conformer ,
soundstream = soundstream ,
spear_tts_text_to_semantic = text_to_semantic
). cuda ()
# and now you can generate state-of-the-art speech
generated_speech = model . generate (
texts = [
'the rain in spain stays mainly in the plain' ,
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - raw waveform decoded from soundstream интегрировать звуковой поток
при генерации, длина может быть определена в секундах (учитывается частота дискретизации и т. д.)
убедитесь, что сгруппированный rvq поддерживается. concat встраивания, а не суммирование по измерению группы
просто скопируйте конформер и повторите относительное позиционное встраивание Шоу с поворотным встраиванием. никто больше не пользуется шау.
по умолчанию мигает внимание к истине
удали батчнорм, и просто используй Layernorm, но уже после взмаха (как в нормформерской бумаге)
тренажер с ускорением - спасибо @lucasnewman
разрешить обучение и генерацию последовательностей переменной длины, передавая mask в forward и generate
возможность вернуть список аудиофайлов при создании
превратите его в инструмент командной строки
добавить перекрестное внимание и адаптивное нормализованное кондиционирование слоя
@misc { borsos2023soundstorm ,
title = { SoundStorm: Efficient Parallel Audio Generation } ,
author = { Zalán Borsos and Matt Sharifi and Damien Vincent and Eugene Kharitonov and Neil Zeghidour and Marco Tagliasacchi } ,
year = { 2023 } ,
eprint = { 2305.09636 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @article { Chang2022MaskGITMG ,
title = { MaskGIT: Masked Generative Image Transformer } ,
author = { Huiwen Chang and Han Zhang and Lu Jiang and Ce Liu and William T. Freeman } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11305-11315 }
} @article { Lezama2022ImprovedMI ,
title = { Improved Masked Image Generation with Token-Critic } ,
author = { Jos{'e} Lezama and Huiwen Chang and Lu Jiang and Irfan Essa } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2209.04439 }
} @inproceedings { Nijkamp2021SCRIPTSP ,
title = { SCRIPT: Self-Critic PreTraining of Transformers } ,
author = { Erik Nijkamp and Bo Pang and Ying Nian Wu and Caiming Xiong } ,
booktitle = { North American Chapter of the Association for Computational Linguistics } ,
year = { 2021 }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { su2021roformer ,
title = { RoFormer: Enhanced Transformer with Rotary Position Embedding } ,
author = { Jianlin Su and Yu Lu and Shengfeng Pan and Bo Wen and Yunfeng Liu } ,
year = { 2021 } ,
eprint = { 2104.09864 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL }
} @inproceedings { Zhou2024ValueRL ,
title = { Value Residual Learning For Alleviating Attention Concentration In Transformers } ,
author = { Zhanchao Zhou and Tianyi Wu and Zhiyun Jiang and Zhenzhong Lan } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273532030 }
}

