mmdit
0.2.1
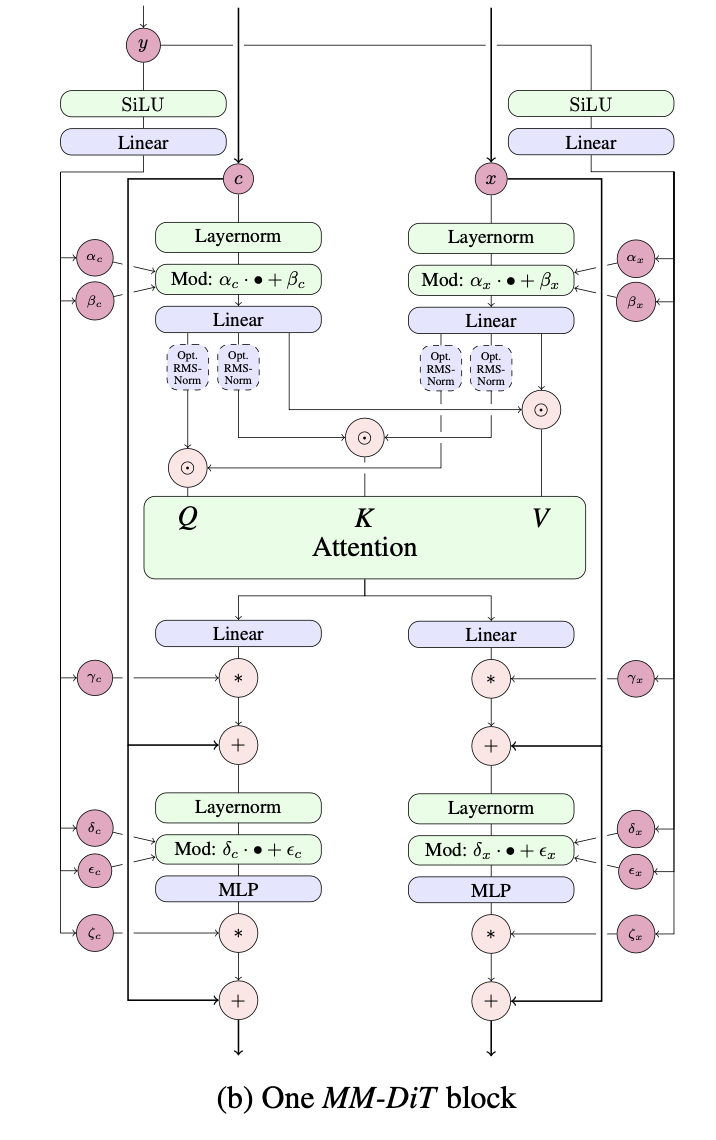
Реализация одноуровневого MMDiT, предложенная Esser et al. в Stable Diffusion 3, в Пайторче
Помимо прямого воспроизведения, также будет обобщено более двух модальностей, поскольку я могу представить себе MMDiT для изображений, аудио и текста.
Также будет предложен импровизированный вариант самообслуживания, который адаптивно выбирает веса для использования посредством обученного стробирования. Эта идея возникла из адаптивных сверток, примененных Кангом и др. для ГигаГАН.
$ pip install mmdit import torch
from mmdit import MMDiTBlock
# define mm dit block
block = MMDiTBlock (
dim_joint_attn = 512 ,
dim_cond = 256 ,
dim_text = 768 ,
dim_image = 512 ,
qk_rmsnorm = True
)
# mock inputs
time_cond = torch . randn ( 2 , 256 )
text_tokens = torch . randn ( 2 , 512 , 768 )
text_mask = torch . ones (( 2 , 512 )). bool ()
image_tokens = torch . randn ( 2 , 1024 , 512 )
# single block forward
text_tokens_next , image_tokens_next = block (
time_cond = time_cond ,
text_tokens = text_tokens ,
text_mask = text_mask ,
image_tokens = image_tokens
)Обобщенную версию можно использовать так:
import torch
from mmdit . mmdit_generalized_pytorch import MMDiT
mmdit = MMDiT (
depth = 2 ,
dim_modalities = ( 768 , 512 , 384 ),
dim_joint_attn = 512 ,
dim_cond = 256 ,
qk_rmsnorm = True
)
# mock inputs
time_cond = torch . randn ( 2 , 256 )
text_tokens = torch . randn ( 2 , 512 , 768 )
text_mask = torch . ones (( 2 , 512 )). bool ()
video_tokens = torch . randn ( 2 , 1024 , 512 )
audio_tokens = torch . randn ( 2 , 256 , 384 )
# forward
text_tokens , video_tokens , audio_tokens = mmdit (
modality_tokens = ( text_tokens , video_tokens , audio_tokens ),
modality_masks = ( text_mask , None , None ),
time_cond = time_cond ,
) @article { Esser2024ScalingRF ,
title = { Scaling Rectified Flow Transformers for High-Resolution Image Synthesis } ,
author = { Patrick Esser and Sumith Kulal and A. Blattmann and Rahim Entezari and Jonas Muller and Harry Saini and Yam Levi and Dominik Lorenz and Axel Sauer and Frederic Boesel and Dustin Podell and Tim Dockhorn and Zion English and Kyle Lacey and Alex Goodwin and Yannik Marek and Robin Rombach } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2403.03206 } ,
url = { https://api.semanticscholar.org/CorpusID:268247980 }
} @inproceedings { Darcet2023VisionTN ,
title = { Vision Transformers Need Registers } ,
author = { Timoth'ee Darcet and Maxime Oquab and Julien Mairal and Piotr Bojanowski } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:263134283 }
} @article { Zhu2024HyperConnections ,
title = { Hyper-Connections } ,
author = { Defa Zhu and Hongzhi Huang and Zihao Huang and Yutao Zeng and Yunyao Mao and Banggu Wu and Qiyang Min and Xun Zhou } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2409.19606 } ,
url = { https://api.semanticscholar.org/CorpusID:272987528 }
}

