lion pytorch
0.2.3
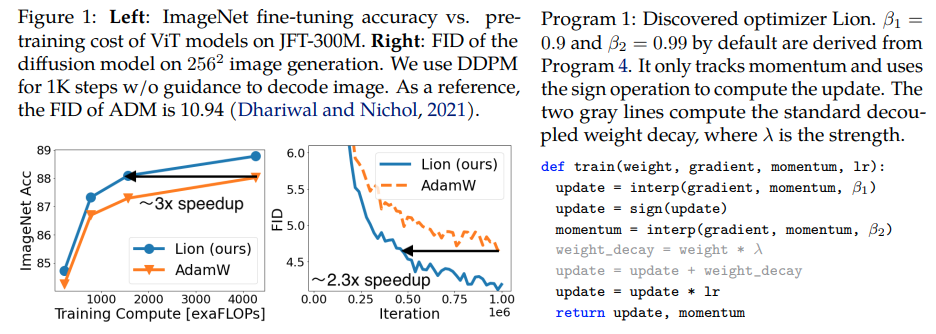
Lion, Evo L ved Sign Momentum , новый оптимизатор, обнаруженный Google Brain, который предположительно лучше , чем Adam(w) в Pytorch. Это почти прямая копия отсюда с небольшими изменениями.
Это настолько просто, что мы можем как можно скорее сделать его доступным и использовать для обучения некоторых отличных моделей, если это действительно работает?
Скорость обучения и снижение веса: авторы пишут в разделе 5. Based on our experience, a suitable learning rate for Lion is typically 3-10x smaller than that for AdamW. Since the effective weight decay is lr * λ, the value of decoupled weight decay λ used for Lion is 3-10x larger than that for AdamW in order to maintain a similar strength. Начальное значение, пиковое значение и конечное значение в графике скорости обучения должны быть изменены одновременно с тем же соотношением, что и в AdamW, как свидетельствует исследователь.
График скорости обучения: в статье авторы используют тот же график скорости обучения для Lion, что и для AdamW. Тем не менее, они наблюдают больший выигрыш при использовании графика косинусного затухания для обучения ViT по сравнению с графиком обратного квадратного корня.
β1 и β2: авторы пишут в разделе 5: The default values for β1 and β2 in AdamW are set as 0.9 and 0.999, respectively, with an ε of 1e−8, while in Lion, the default values for β1 and β2 are discovered through the program search process and set as 0.9 and 0.99, respectively. Подобно тому, как люди снижают β2 до 0,99 или меньше и увеличивают ε до 1e-6 в AdamW для улучшения стабильности, использование β1=0.95, β2=0.98 в Lion также может быть полезным для смягчения нестабильности во время тренировки, как предлагают авторы. Это подтвердил исследователь.
Обновление: кажется, работает для моего локального моделирования авторегрессионного языка enwik8.
Обновление 2: эксперименты кажутся намного хуже, чем Адам, если бы скорость обучения оставалась постоянной.
Обновление 3: разделив скорость обучения на 3, мы видим лучшие ранние результаты, чем у Адама. Возможно, Адам был свергнут с престола спустя почти десять лет.
Обновление 4: использование эмпирического правила в 10 раз меньшей скорости обучения из статьи привело к худшему результату. Так что я думаю, что это все еще требует некоторой настройки.
Подведение итогов предыдущих обновлений: как показали эксперименты, Лев с в 3 раза меньшей скоростью обучения превосходит Адама. Это все равно требует некоторой настройки, поскольку снижение скорости обучения в 10 раз приводит к худшему результату.
Обновление 5: на данный момент получены все положительные результаты моделирования языка, если все сделано правильно. Также были получены положительные результаты по значительному обучению преобразованию текста в изображение, хотя оно требует некоторой настройки. Отрицательные результаты, похоже, связаны с проблемами и архитектурами, выходящими за рамки того, что оценивалось в статье - RL, сети прямой связи, странные гибридные архитектуры с LSTM + свертки и т. д. Отрицательные анекдоты также подтверждают, что этот метод чувствителен к размеру пакета, количеству данных/увеличению. . Будет объявлено, какой оптимальный график скорости обучения и влияет ли время восстановления на результаты. Также интересно получить положительный результат при открытом клипе, который стал отрицательным по мере увеличения размера модели (но это можно решить).
Обновление 6: проблема с открытым зажимом решена автором путем установки более высокой начальной температуры.
Обновление 7: рекомендую этот оптимизатор только при больших размерах пакетов (64 или выше).
$ pip установить лев-pytorch
Альтернативно, используя conda:
$ conda установить лев-pytorch
# модель игрушкиимпортируем факел из факела import nnmodel = nn.Linear(10, 1)# импортируем Lion и создаем экземпляр с параметрами из Lion_pytorch import Lionopt = Lion(model.parameters(), lr=1e-4, Weight_decay=1e-2)# вперед и backwardsloss = model(torch.randn(10))loss.backward()# оптимизатор Stepopt.step()opt.zero_grad()
Чтобы использовать объединенное ядро для обновления параметров, сначала pip install triton -U --pre , затем
opt = Lion(model.parameters(),lr=1e-4,weight_decay=1e-2,use_triton=True # установите для этого параметра значение True, чтобы использовать ядро cuda с Triton lang (Tillet et al))
Stability.ai за щедрую поддержку работы и передовые исследования в области искусственного интеллекта с открытым исходным кодом.
@misc{https://doi.org/10.48550/arxiv.2302.06675,url = {https://arxiv.org/abs/2302.06675},author = {Чен, Сяннин и Лян, Чен и Хуан, Да и Реал, Эстебан и Ван, Кайюань и Лю, Яо и Фам, Хьеу и Донг, Сюаньи и Луонг, Тхан и Се, Чо-Джуй и Лу, Ифэн и Ле, Куок В.},title = {Символическое открытие алгоритмов оптимизации},publisher = {arXiv},year = {2023}} @article{Tillet2019TritonAI,title = {Triton: промежуточный язык и компилятор для вычислений тайловых нейронных сетей},author = {Филипп Тилле и Х. Кунг и Д. Кокс},journal = {Материалы 3-го международного семинара ACM SIGPLAN по машинам Языки изучения и программирования},year = {2019}} @misc{Schaipp2024,author = {Фабиан Шаипп},url = {https://fabian-sp.github.io/posts/2024/02/decoupling/}} @inproceedings{Liang2024CautiousOI,title = {Осторожные оптимизаторы: улучшение обучения с помощью одной строки кода},author = {Кайчжао Лян и Личжан Чен и Бо Лю и Цян Лю},year = {2024},url = {https://api .semanticscholar.org/CorpusID:274234738}} 

