RoboFlamingo
1.0.0
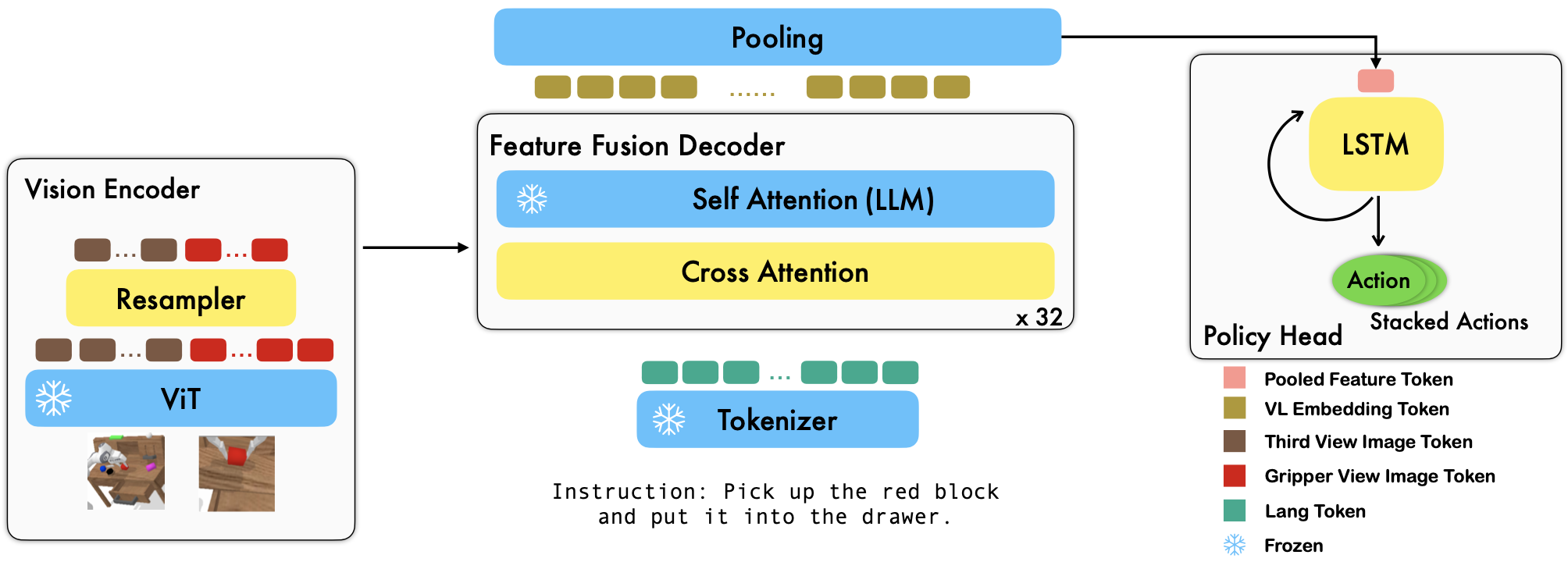
RoboFlamingo — это предварительно обученная среда обучения робототехнике на основе VLM, которая изучает широкий спектр навыков роботов с языковым управлением путем точной настройки автономных наборов имитационных данных в свободной форме. Превысив современные показатели с большим отрывом от теста CALVIN, мы показываем, что RoboFlamingo может быть эффективной и конкурентоспособной альтернативой для адаптации VLM к управлению роботами. Наши обширные экспериментальные результаты также позволяют сделать несколько интересных выводов относительно поведения различных предварительно обученных VLM при выполнении задач манипуляции. RoboFlamingo можно обучать или оценивать на одном сервере графического процессора (требования к памяти графического процессора зависят от размера модели), и мы считаем, что RoboFlamingo потенциально может стать экономичным и простым в использовании решением для манипулирования робототехникой, предоставляя каждому возможность способность точно настраивать собственную политику в области робототехники.
Это также официальный репозиторий кода для документа «Модели Vision-Language Foundation как эффективные имитаторы роботов».
Все наши эксперименты проводятся на одном графическом сервере с 8 графическими процессорами Nvidia A100 (80G).
Предварительно обученные модели доступны на Hugging Face.
Мы поддерживаем предварительно обученные видеокодеры из пакета OpenCLIP, который включает предварительно обученные модели OpenAI. Мы также поддерживаем предварительно обученные языковые модели из пакета transformers , такие как модели MPT, RedPajama, LLaMA, OPT, GPT-Neo, GPT-J и Pythia.
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) Аргумент cross_attn_every_n_layers управляет частотой применения слоев перекрестного внимания и должен соответствовать VLM. Аргумент decoder_type управляет типом декодера. В настоящее время мы поддерживаем lstm , fc , diffusion (существуют ошибки для загрузчика данных) и GPT .
Мы сообщаем результаты по тесту CALVIN.
| Метод | Данные обучения | Тестовый сплит | 1 | 2 | 3 | 4 | 5 | Средняя длина |
|---|---|---|---|---|---|---|---|---|
| МКИЛ | ABCD (Полный) | Д | 0,373 | 0,027 | 0,002 | 0,000 | 0,000 | 0,40 |
| ХУЛК | ABCD (Полный) | Д | 0,889 | 0,733 | 0,587 | 0,475 | 0,383 | 3.06 |
| HULC (переобучен) | ABCD (Язык) | Д | 0,892 | 0,701 | 0,548 | 0,420 | 0,335 | 2,90 |
| РТ-1 (переподготовка) | ABCD (Язык) | Д | 0,844 | 0,617 | 0,438 | 0,323 | 0,227 | 2,45 |
| Наш | ABCD (Язык) | Д | 0,964 | 0,896 | 0,824 | 0,740 | 0,66 | 4.09 |
| МКИЛ | ABC (Полная версия) | Д | 0,304 | 0,013 | 0,002 | 0,000 | 0,000 | 0,31 |
| ХУЛК | ABC (Полная версия) | Д | 0,418 | 0,165 | 0,057 | 0,019 | 0,011 | 0,67 |
| РТ-1 (переподготовка) | ABC (Язык) | Д | 0,533 | 0,222 | 0,094 | 0,038 | 0,013 | 0,90 |
| Наш | ABC (Язык) | Д | 0,824 | 0,619 | 0,466 | 0,331 | 0,235 | 2,48 |
| ХУЛК | ABCD (Полный) | Д (обогащать) | 0,715 | 0,470 | 0,308 | 0,199 | 0,130 | 1,82 |
| РТ-1 (переподготовка) | ABCD (Язык) | Д (обогащать) | 0,494 | 0,222 | 0,086 | 0,036 | 0,017 | 0,86 |
| Наш | ABCD (Язык) | Д (обогащать) | 0,720 | 0,480 | 0,299 | 0,211 | 0,144 | 1,85 |
| Наши (заморозка) | ABCD (Язык) | Д (обогащать) | 0,737 | 0,530 | 0,385 | 0,275 | 0,192 | 2.12 |
Следуйте инструкциям в OpenFlamingo и CALVIN, чтобы загрузить необходимый набор данных и предварительно обученные модели VLM.
Загрузите набор данных CALVIN, выберите разделение с помощью:
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugЗагрузите выпущенные модели OpenFlamingo:
| # параметры | Языковая модель | Видеокодер | Интервал Xattn* | КОКО 4-шотовый СИДР | VQAv2 Точность 4 выстрела | Средняя длина | Веса |
|---|---|---|---|---|---|---|---|
| 3Б | анас-авадалла/mpt-1b-redpajama-200b | openai CLIP ViT-L/14 | 1 | 77,3 | 45,8 | 3,94 | Связь |
| 3Б | анас-авадалла/mpt-1b-redpajama-200b-долли | openai CLIP ViT-L/14 | 1 | 82,7 | 45,7 | 4.09 | Связь |
| 4Б | вместекомпьютер/RedPajama-INCITE-Base-3B-v1 | openai CLIP ViT-L/14 | 2 | 81,8 | 49,0 | 3,67 | Связь |
| 4Б | вместекомпьютер/RedPajama-INCITE-Instruct-3B-v1 | openai CLIP ViT-L/14 | 2 | 85,8 | 49,0 | 3,79 | Связь |
| 9Б | Анас-авадалла/mpt-7b | openai CLIP ViT-L/14 | 4 | 89,0 | 54,8 | 3,97 | Связь |
Замените ${lang_encoder_path} и ${tokenizer_path} словаря путей (например, mpt_dict ) в robot_flamingo/models/factory.py для каждого предварительно обученного VLM своими собственными путями.
Клонировать этот репозиторий
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
Установите необходимые пакеты:
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} — путь к набору данных CALVIN;
${lm_path} — путь к предварительно обученному LLM;
${tokenizer_path} — путь к токенизатору VLM;
${openflamingo_checkpoint} — это путь к предварительно обученной модели OpenFlamingo;
${log_file} — путь к файлу журнала.
Мы также предоставляем robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bash для запуска обучения. Этот bash настраивает версию MPT-3B-IFT модели OpenFlamingo, которая содержит гиперпараметры по умолчанию для обучения модели и соответствует лучшим результатам в статье.
python eval_ckpts.py
Добавив имя и каталог контрольной точки в eval_ckpts.py , скрипт автоматически загрузит модель и оценит ее. Например, если вы хотите оценить контрольную точку по пути «путь к вашей контрольной точке», вы можете изменить переменные ckpt_dir и ckpt_names в eval_ckpts.py, и результаты оценки будут сохранены как «logs/your-checkpoint-prefix». бревно'.
Результаты, показанные ниже, показывают, что совместное обучение может сохранить большую часть возможностей магистрали VLM при выполнении задач VL, но при этом немного потерять производительность при выполнении задач робота.
использовать
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
запустить совместное обучение RoboFlamingo с CoCO, VQAV2 и CALVIN. Вам следует обновить пути CoCO и VQA в get_coco_dataset и get_vqa_dataset в robot_flamingo/data/data.py .
| Расколоть | СР 1 | СР 2 | СР 3 | СР 4 | СР 5 | Средняя длина |
|---|---|---|---|---|---|---|
| Совместный поезд | ABC->D | 82,9% | 63,6% | 45,3% | 32,1% | 23,4% |
| Тонкая настройка | ABC->D | 82,4% | 61,9% | 46,6% | 33,1% | 23,5% |
| Совместный поезд | ABCD->D | 95,7% | 85,8% | 73,7% | 64,5% | 56,1% |
| Тонкая настройка | ABCD->D | 96,4% | 89,6% | 82,4% | 74,0% | 66,2% |
| Совместный поезд | ABCD->D (обогащать) | 67,8% | 45,2% | 29,4% | 18,9% | 11,7% |
| Тонкая настройка | ABCD->D (обогащать) | 72,0% | 48,0% | 29,9% | 21,1% | 14,4% |
| кокос | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| БЛЕУ-1 | БЛЕУ-2 | БЛЕУ-3 | БЛЕУ-4 | МЕТЕОР | РУЖЕ_Л | Сидр | СПАЙС | Акк. | |
| Точная настройка (3B, нулевой выстрел) | 0,156 | 0,051 | 0,018 | 0,007 | 0,038 | 0,148 | 0,004 | 0,006 | 4.09 |
| Точная настройка (3B, 4 кадра) | 0,166 | 0,056 | 0,020 | 0,008 | 0,042 | 0,158 | 0,004 | 0,008 | 3,87 |
| Сопутствующий поезд (3B, нулевой выстрел) | 0,225 | 0,158 | 0,107 | 0,072 | 0,124 | 0,334 | 0,345 | 0,085 | 36,37 |
| Оригинальный Фламинго (80B, доработанный) | - | - | - | - | - | - | 1,381 | - | 82,0 |
Логотип создан с помощью MidJourney.
В этой работе используется код из следующих проектов и наборов данных с открытым исходным кодом:
Оригинал: https://github.com/mees/calvin Лицензия: MIT.
Оригинал: https://github.com/openai/CLIP. Лицензия: MIT.
Оригинал: https://github.com/mlfoundations/open_flamingo Лицензия: MIT.
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


