toyCarIRL
1.0.0
Обучение с подкреплением (RL) — это самая базовая и наиболее интуитивная форма обучения методом проб и ошибок. Это способ обучения большинства живых организмов, обладающих той или иной формой мыслительных способностей. Часто называемый обучением путем исследования, это способ, с помощью которого новорожденный человеческий ребенок учится делать свои первые шаги, то есть сначала совершая случайные действия, а затем медленно выясняя действия, которые приводят к движению вперед.
Обратите внимание: этот пост предполагает хорошее понимание структуры обучения с подкреплением. Пожалуйста, ознакомьтесь с RL на 5-й и 6-й неделе этого замечательного онлайн-курса AI_Berkeley.
Теперь вопрос, который я продолжал задавать себе, заключается в том, что является движущей силой такого рода обучения, что заставляет агента изучать определенное поведение тем способом, которым он это делает. Узнав больше о RL, я наткнулся на идею вознаграждений : по сути, агент пытается выбирать свои действия таким образом, чтобы вознаграждение, получаемое от этого конкретного поведения, было максимальным. Теперь, чтобы заставить агента выполнять разные действия, необходимо изменить/использовать структуру вознаграждения. Но предположим, что у нас есть только знание о поведении эксперта, тогда как мы можем оценить структуру вознаграждения с учетом конкретного поведения в окружающей среде? Что ж, это та самая проблема обратного обучения с подкреплением (IRL) , где, учитывая оптимальную экспертную политику (на самом деле считающуюся оптимальной), мы хотим определить основную структуру вознаграждения.
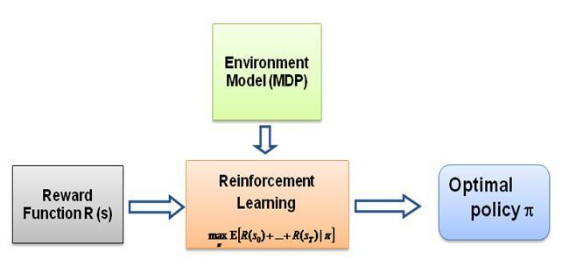
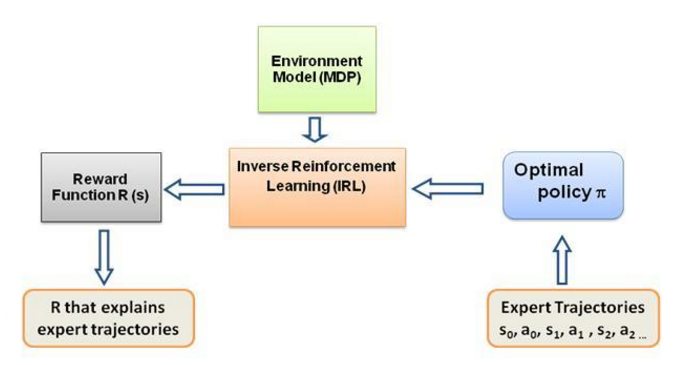
Опять же, это не статья «Введение в обучение с обратным подкреплением», а скорее руководство о том, как использовать/кодировать структуру обучения с обратным подкреплением для решения вашей собственной проблемы, но IRL лежит в самой ее основе, и очень важно знать о ней. это первое. В прошлом IRL тщательно изучалась, и для нее были разработаны алгоритмы. Дополнительную информацию можно найти в статьях Ng and Russell, 2000 и Abbeel and Ng, 2004.
В этом сообщении адаптируется алгоритм Аббила и Нг, 2004 г., для решения проблемы IRL.
Идея здесь состоит в том, чтобы запрограммировать простого агента в двумерном мире, полном препятствий, для копирования/клонирования различных вариантов поведения в окружающей среде, причем поведение вводится с помощью экспертных траекторий, заданных вручную экспертом-человеком/компьютером. Эта форма обучения на основе экспертных демонстраций в научной литературе называется ученичеством, в основе которого лежит обратное обучение с подкреплением, и мы просто пытаемся выяснить различные функции вознаграждения для этих разных видов поведения.
В целом да, это одно и то же, а значит учиться на демонстрации (LfD). Оба метода учатся на демонстрации, но они учат разным вещам:
Обучение посредством обучения с обратным подкреплением будет пытаться определить цель учителя . Другими словами, на основе наблюдения он изучит функцию вознаграждения, которую затем можно будет использовать в обучении с подкреплением. Если он обнаружит, что цель состоит в том, чтобы забить гвоздь молотком, он проигнорирует моргание и царапины учителя, поскольку они не имеют отношения к цели.
Имитационное обучение (также известное как поведенческое клонирование) будет пытаться напрямую копировать учителя . Этого можно достичь только за счет контролируемого обучения. ИИ будет пытаться скопировать каждое действие, даже не относящиеся к делу действия, такие как, например, моргание или почесывание, или даже ошибки. Вы также можете использовать RL здесь, но только если у вас есть функция вознаграждения.
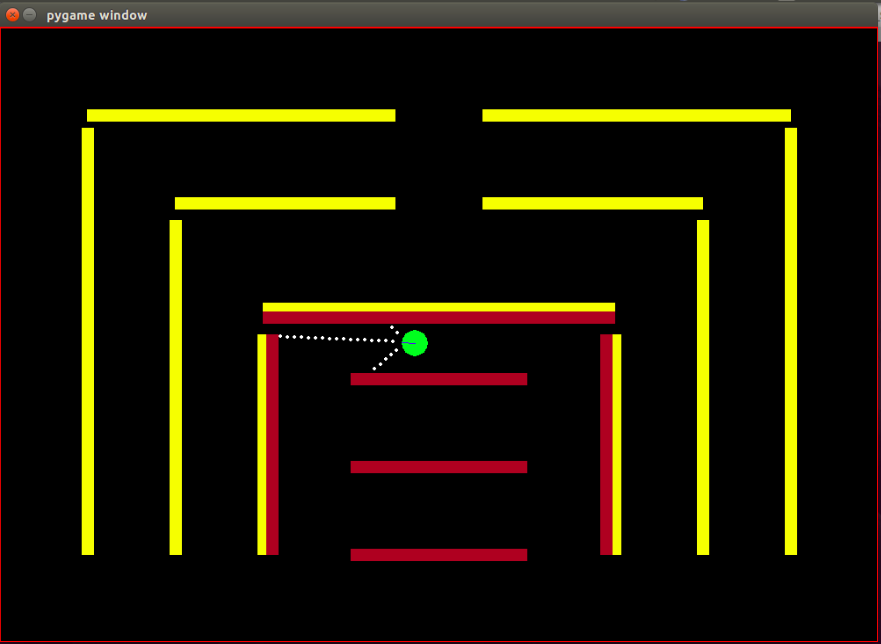
Агент: агент представляет собой небольшой зеленый кружок, направление курса которого обозначено синей линией.
Датчики: агент оснащен тремя датчиками расстояния и цвета, и это единственная информация, которую агент имеет об окружающей среде.
Пространство состояний: состояние агента состоит из 8 наблюдаемых особенностей:
Обратите внимание: нормализация выполняется для того, чтобы гарантировать, что каждое наблюдаемое значение признака находится в диапазоне [0,1], что является необходимым условием сходимости вознаграждений для алгоритма IRL.
Награды: вознаграждение после каждого кадра рассчитывается как взвешенная линейная комбинация значений признаков, наблюдаемых в этом соответствующем кадре. Здесь вознаграждение r_t в t-м кадре вычисляется скалярным произведением вектора весов w с вектором значений признаков в t-м кадре, то есть вектором состояния phi_t. Так что r_t = w^T x phi_t.
Доступные действия: с каждым новым кадром агент автоматически делает шаг вперед . Доступные действия могут либо повернуть агента влево , вправо , либо ничего не делать , что является простым шагом вперед. Обратите внимание, что действия поворота также включают в себя движение вперед. не является вращением на месте.
Препятствия: окружающая среда состоит из жестких стен, намеренно раскрашенных в разные цвета. Агент обладает способностью распознавания цвета, что помогает ему различать типы препятствий. Среда спроектирована таким образом, чтобы облегчить тестирование алгоритма IRL.
Начальная позиция(состояние) бота фиксирована, так как согласно алгоритму IRL необходимо, чтобы начальное состояние было одинаковым для всех итераций.
Обратите внимание, что алгоритм RL полностью заимствован из этого поста Мэттом Харви с небольшими изменениями, поэтому имеет смысл рассказать об изменениях, которые я внес, и даже если читателю комфортно с RL, я настоятельно рекомендую просмотреть этот пост, чтобы понять, как происходит обучение с подкреплением.
Окружающая среда значительно изменилась: агент получил способность не только определять расстояние от трех датчиков, но и определять цвет препятствий, что позволяет ему различать препятствия. Кроме того, агент теперь стал меньше по размеру, а его сенсорные точки теперь расположены ближе, чтобы обеспечить большее разрешение и лучшую производительность. Препятствия пока пришлось сделать статическими, чтобы упростить процесс тестирования алгоритма IRL, это вполне может привести к переобучению данных, но меня это на данный момент не беспокоит. Как обсуждалось выше, набор наблюдений или состояние агента было увеличено с 3 до 8 с включением функции сбоя в состояние агента. Структура вознаграждения полностью изменена, вознаграждение теперь представляет собой взвешенную линейную комбинацию этих 8 функций, агент больше не получает вознаграждение -500 за столкновение с препятствиями, вместо этого значение функции за столкновение равно +1, а за отсутствие столкновения - 0 и Алгоритм должен решить, какой вес следует присвоить этой функции на основе поведения эксперта.
Как указано в блоге Мэтта, цель здесь состоит в том, чтобы не просто научить агента RL избегать препятствий, я имею в виду, зачем предполагать что-либо о структуре вознаграждения, позволить структуре вознаграждения полностью определяться алгоритмом на основе экспертных демонстраций и посмотреть, какое поведение достигается определенный набор наград!
Особенности или базовые функции phi_i, которые по сути являются наблюдаемыми в состоянии. Особенности текущей проблемы обсуждаются выше в разделе «Пространство состояний». Мы определяем phi(s_t) как сумму всех ожиданий функции phi_i, таких, что:
Награды r_t — линейная комбинация этих значений признаков, наблюдаемых в каждом состоянии s_t.
Ожидания функций mu(pi) политики pi — это сумма дисконтированных значений функций phi(s_t).
Ожидаемые характеристики политики не зависят от весов, они зависят только от состояний, посещенных во время выполнения (согласно политике), и от коэффициента дисконтирования гаммы, числа от 0 до 1 (например, 0,9 в нашем случае). Чтобы получить ожидаемые функции политики, мы должны выполнить политику в реальном времени с помощью агента и записать посещенные состояния и полученные значения функций.
Ожидания функций экспертной политики или ожидания функций эксперта mu(pi_E) получаются в результате действий, которые предпринимаются в соответствии с поведением эксперта. По сути, мы выполняем эту политику и получаем ожидаемые функции, как и любую другую политику. Ожидания экспертных функций передаются алгоритму IRL для поиска таких весов, чтобы функция вознаграждения, соответствующая весам, напоминала базовую функцию вознаграждения, которую эксперт пытается максимизировать (на обычном языке RL).
Ожидания функций случайной политики — выполните случайную политику и используйте полученные ожидания функций для инициализации IRL.
Ведите список ожидаемых функций политики, которые мы получаем после каждой итерации.
В самом начале у нас есть только pi^1 -> ожидания случайной функции политики.
Найдите первый набор весов w^1 с помощью выпуклой оптимизации. Проблема аналогична классификатору SVM, который пытается присвоить метку +1 ожидаемой экспертной функции. и -1 метка для всех остальных ожидаемых функций политики.-
такой, что,
Условия прекращения:
Теперь, как только мы получим веса после одной итерации оптимизации, то есть когда мы получим новую функцию вознаграждения, нам нужно изучить политику, которую порождает эта функция вознаграждения. Это то же самое, что сказать: найти политику, которая пытается максимизировать полученную функцию вознаграждения. Чтобы найти эту новую политику, нам нужно обучить алгоритм обучения с подкреплением этой новой функцией вознаграждения и обучать его до тех пор, пока значения Q не сойдутся, чтобы получить правильную оценку политики.
После того, как мы изучили новую политику, мы должны протестировать ее в Интернете, чтобы получить ожидаемые функции, соответствующие этой новой политике. Затем мы добавляем эти новые ожидания функций в наш список ожиданий функций и продолжаем без следующей итерации алгоритма IRL до сходимости.
Давайте теперь попробуем разобраться в коде. Пожалуйста, найдите полный код в этом репозитории git. В основном вам следует беспокоиться о трех файлах:
manualControl.py — чтобы получить ожидаемые от эксперта функции путем ручного перемещения агента. Запустите «python3 manualControl.py», подождите, пока загрузится графический интерфейс, а затем используйте клавиши со стрелками, чтобы начать перемещаться. Дайте ему поведение, которое вы хотите скопировать (обратите внимание, что поведение, которое вы ожидаете от него, должно быть разумным для данного пространства состояний). Хорошим трюком было бы представить себя на месте агента и подумать, сможете ли вы различить данное поведение, учитывая только текущее пространство состояний. Более подробную информацию смотрите в исходном файле.
toy_car_IRL.py — основной файл, здесь лежит код IRL. Давайте посмотрим код шаг за шагом:
{% суть 51542f27e97eac1559a00f06b757df1a %}
Импортируйте зависимости и определите важные параметры, при необходимости измените ПОВЕДЕНИЕ. КАДРЫ — это количество кадров, которые вы хотите, чтобы алгоритм RL выполнялся. 100 тысяч — это нормально и занимает около 2 часов.
{% суть 49b602b9a3090773d492310175bb2e3f %}
Создайте простой в использовании класс irlAgent, который учитывает случайное и экспертное поведение, а также другие важные параметры, как показано.
{% суть bc17c06a07ea3b915827e89f3c13a2ae %}
Функция getRLAgentFE использует IRL_helper от обучаемого с подкреплением для обучения новой модели и получения ожидаемых функций, воспроизводя эту модель в течение 2000 итераций. По сути, он возвращает ожидаемые характеристики для каждого полученного набора весов (W).
{% суть ce0ef99adc652c7469f1bc4303a3af41 %}
Чтобы обновить словарь, в котором мы храним полученные политики и соответствующие им значения t. Где t = (weights.tanspose)x(expert-newPolicy).
{% суть be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
Реализация основного алгоритма IRL, о котором говорилось выше. {% суть 9faee18596467ee33ac5d91fd0cb675f %}
Выпуклая оптимизация для обновления весов при получении новой политики, по сути, присваивает метку +1 экспертной политике и метку -1 всем остальным политикам и оптимизирует веса с учетом упомянутых ограничений. Чтобы узнать больше об этой оптимизации, посетите сайт
{% суть 30cf6c59b9915054f3cf6d278f8f8a11 %}
Создайте irlAgent и передайте нужные параметры, выберите тип поведения эксперта, для которого вы хотите узнать веса, а затем запустите функциюOptimWeightFinder(). Обратите внимание, что я уже получил ожидаемые характеристики для красного, желтого и коричневого поведения. После завершения работы алгоритма вы получите список весов в файле Weights-red/yellow/brown.txt с соответствующим выбранным ПОВЕДЕНИЕМ. Теперь, чтобы выбрать наилучшее возможное поведение из всех полученных весов, воспроизведите сохраненные модели в каталоге save-models_BEHAVIOR/evaluatedPolicies/, модели сохраняются в следующем формате 'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+ номер итерации+ '-164-150-100-50000-100000' + '.h5' . По сути, вы получите разные веса для разных итераций. Сначала поиграйте с моделями, чтобы определить модель, которая работает лучше всего, затем запишите номер итерации этой модели. Полученные веса, соответствующие этому номеру итерации, являются весами, которые приближают вас к эксперту. поведение.
А еще есть файлы, которые вам, вероятно, не нужно обновлять/изменять, по крайней мере, для содержимого этого поста -
Примерно через 10-15 итераций алгоритм сходится во всех четырех выбранных вариантах поведения, я получил следующие результаты:
| Веса | я люблю желтый | Я люблю Брауна | Я люблю красный | Я люблю Бампинг |
|---|---|---|---|---|
| w1 (Расстояние левого датчика) | -0,0880 | -0,2627 | 0,2816 | -0,5892 |
| w2 (среднее расстояние датчика) | -0,0624 | 0,0363 | -0,5547 | -0,3672 |
| w3 (расстояние правого датчика) | 0,0914 | 0,0931 | -0,2297 | -0,4660 |
| w4 (черный цвет) | -0,0114 | 0,0046 | 0,6824 | -0,0299 |
| w5 (желтый цвет) | 0,6690 | -0,1829 | -0,3025 | -0,1528 |
| w6 (коричневый цвет) | -0,0771 | 0,6987 | 0,0004 | -0,0368 |
| w7 (красный цвет) | -0,6650 | -0,5922 | 0,0525 | -0,5239 |
| w8 (сбой) | -0,2897 | -0,2201 | -0,0075 | 0,0256 |
Высокое отрицательное значение присвоено весу, который принадлежит признаку удара в первых трех вариантах поведения, поскольку эти три экспертных поведения не хотят, чтобы агент натыкался на препятствия. В то время как вес той же функции в последнем поведении, а именно бота Nasty, положителен, поскольку поведение эксперта предполагает натыкание.
Очевидно, что веса цветовых характеристик соответствуют поведению эксперта: высокие, когда этот цвет желателен, в противном случае — довольно низкое/отрицательное значение, чтобы получить отчетливое поведение.
Веса признаков расстояний очень неоднозначны (нелогично), и очень сложно найти какую-то значимую закономерность в весах. Единственное, на что я хочу обратить внимание, это то, что в текущих настройках можно даже различать поведение по часовой стрелке и против часовой стрелки, эту информацию будут нести функции расстояния.
Обратите внимание: очень важно сначала подумать о том, сможете ли вы, как человек, отличить заданное поведение от наличия текущего набора состояний (наблюдений) при разработке структуры проблемы. В противном случае вы можете просто заставить алгоритм находить разные веса, не предоставляя ему полностью необходимую информацию.
Если вы действительно хотите попасть в реальную жизнь, я бы порекомендовал вам попытаться научить агента новому поведению (возможно, вам придется изменить для этого среду, поскольку возможные различные варианты поведения для текущего набора состояний уже были использованы, ну, по крайней мере, по моему мнению).
Установите зависимости Pygame с помощью:
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
Затем установите сам Pygame:
pip3 install hg+http://bitbucket.org/pygame/pygame
Это физический движок, используемый в симуляции. Он только что претерпел значительные изменения (v5), поэтому вам нужно использовать более старую версию v4. Версия 4 написана для Python 2, поэтому есть пара дополнительных шагов.
Вернитесь домой или загрузите и получите Pymunk 4:
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
Распакуйте его:
tar zxvf pymunk-4.0.0.tar.gz
Обновление с Python 2 до 3:
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
Установите его:
cd .. python3 setup.py install
Теперь вернитесь туда, где вы клонировали reinforcement-learning-car , и убедитесь, что все работает с помощью быстрого python3 learning.py . Если вы видите экран с маленькой точкой, летающей по экрану, вы готовы к работе!
Во-первых, вам нужно обучить модель. Это сохранит веса в папке saved-models . Возможно, вам придется создать эту папку перед запуском . Вы можете обучить модель, запустив:
python3 learning.py
Обучение модели может занять от часа до 36 часов, в зависимости от сложности сети и размера выборки. Однако он будет выдавать веса каждые 25 000 кадров, поэтому вы сможете перейти к следующему шагу за гораздо меньшее время.
Отредактируйте файл playing.py , изменив путь к модели, которую вы хотите загрузить. Извините, я знаю, что это должен быть аргумент командной строки.
Затем наблюдайте, как машина сама объезжает препятствия!
python3 playing.py
Вот и все.


