article_spider
1.0.0
Вывод консоли:
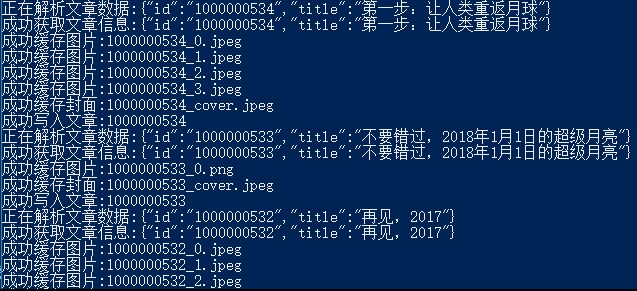
Данные статьи:
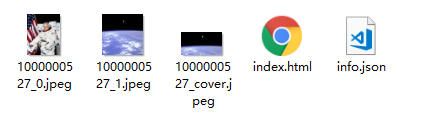
Предварительный просмотр HTML:

В настоящее время для сканирования статей поддерживаются два метода.
Получайте статьи через результаты поиска Sogou WeChat.
Преимущества: Этот метод не требует аутентификации при входе и прост в использовании.
Недостатки: можно захватить только последние 10 фрагментов данных.
Сценарий использования: подходит для настройки запланированных задач сканирования для получения больших объемов данных.
Перехватите параметры запроса Ajax списка статей общедоступной учетной записи WeChat и смоделируйте клиент WeChat для чтения списка статей и информации о статьях.
Преимущества: Можно получить все данные статей общедоступных аккаунтов.
Недостатки: вам необходимо войти в WeChat и вручную установить параметры, такие как файлы cookie, с помощью инструментов, прежде чем вы сможете его использовать.
Сценарий использования: захват большого количества данных общедоступных учетных записей за один раз и обновление данных с помощью метода Sogou после завершения захвата.
NodeJS и NPM, браузер Chrome, настольный клиент WeChat (Mac или Windows)
git clone [email protected]:f111fei/article_spider.git
cd article_spider
npm install typescript -g
npm install
tsc
Установите файл config.json в корневом каталоге проекта. Поля определяются следующим образом:
interface Config {
// 必填,要抓取的微信公众号名称。
name: string;
// 可选,若快打码平台的账号密码。用于搜狗抓取模式下自动识别验证码。
ruokuai: {
username: string;
password: string;
};
wechat: {
// 可选,要抓取文章的起始页,默认0
start?: number;
// 可选,要抓取的文章数,默认不限制
maxNum?: number;
// 可选,抓取模式(sougou, all)。默认all
mode?: string;
// 抓取模式为all时有效,公众号的biz字段,获取方法参见下面
biz?: string;
// 抓取模式为all时有效,当前cookie字段,获取方法参见下面
cookie?: string;
// 抓取模式为all时有效,当前appmsg_token字段,获取方法参见下面
appmsg_token?: string;
};
}
Если режим сканирования — sougou , пропустите этот раздел.
Чтобы получить данные запроса Ajax списка статей, вам необходимо перехватить запрос на получение данных списка статей и найти ключевые параметры, такие как biz, cookie, appmsg_token и т. д. Вот как получить параметры запроса.
В качестве примера возьмем публичный аккаунт NASA爱好者.
1. Откройте официальный аккаунт --- верхний правый угол --- нажмите, чтобы просмотреть исторические сообщения.
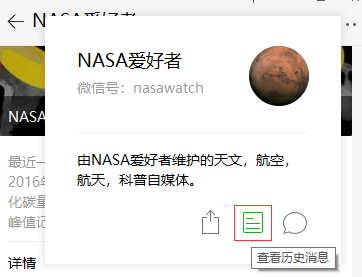
Примечание. Поле
nameв конфигурации должно быть заполнено идентификатором WeChat IDnasawatch, а неNASA爱好者.
2. В открывшемся окне нажмите «Открыть в браузере по умолчанию (Chrome)» в строке меню и с помощью Chrome откройте страницу со списком статей.

3. Если ссылка появляется при открытии в браузере请在微信客户端打开链接。 подсказка, указывающая, что URL-адрес зашифрован. Чтобы получить правильный URL-адрес, выполните следующие действия. В противном случае пропустите этот шаг.
Закройте клиент WeChat и найдите расположение исполняемой программы клиента WeChat для настольных компьютеров. Запустите программу с помощью командной строки:
В Windows это обычно:
"C:Program Files (x86)TencentWeChatWeChat.exe" --remote-debugging-port=9222
Под Mac это обычно:
"/Applications/WeChat.app/Contents/MacOS/WeChat" --remote-debugging-port=9222
Выполните шаг 1, чтобы открыть страницу сообщений истории.
Откройте URL-адрес http://127.0.0.1:9222/json с помощью браузера Chrome.
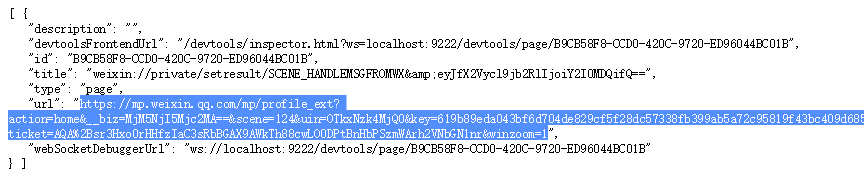
Скопируйте поле URL-адреса и откройте его на новой вкладке, и вы увидите правильную страницу исторических сообщений.
4. На странице сообщений истории щелкните правой кнопкой мыши ---- Проверьте, откройте Инструменты разработчика Chrome ---- Перейдите на вкладку "Сеть" ---- Обновите браузер. Найдите справа cookie, biz, appmsg_token и другие поля и заполните их в config.json .
Вам нужно прокрутить страницу списка вниз, чтобы загрузить следующую страницу, найти запрос, начинающийся с
https://mp.weixin.qq.com/mp/profile_ext?action=getmsgи просмотреть его параметры.
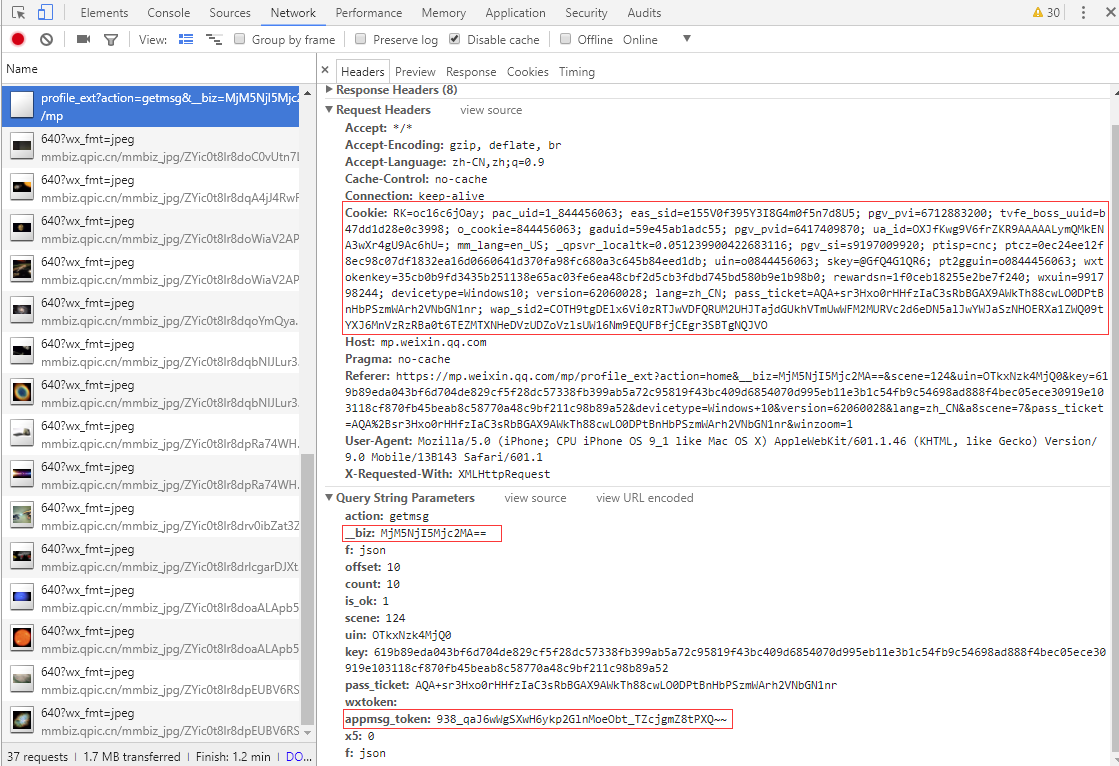
Эти поля могут стать недействительными через несколько часов, и вы можете получить их повторно, выполнив описанные выше действия.
npm start
Информация о просканированной статье, изображения и исходные данные статьи будут храниться в папке db в корневом каталоге проекта.


