liuli
v0.2.0
Просто объясните это вкратце:
Коллектор : отслеживает настроенные источники чтения, такие как общедоступные учетные записи, книги или источники блогов, на которые они подписаны, и передает их в Liuli в едином стандартном формате в качестве источника входных данных;
Процессор : настройка целевого контента, например использование машинного обучения для автоматической маркировки классификатора рекламы на основе исторических данных о рекламе или введение функций перехвата для выполнения на соответствующих узлах;
Распространитель : полагается на уровень интерфейса для выполнения запросов и ответов на данные, предоставляет пользователям персонализированные конфигурации, а затем автоматически распространяет в соответствии с конфигурацией, передавая чистые статьи клиентам WeChat, DingTalk, TG, RSS и даже самостоятельно созданным веб-сайтам;
Backer : резервное копирование обработанных статей, например сохранение их в базе данных или GitHub и т. д.
Это позволяет создать чистую среду для чтения. Таким образом, на основе полученных данных можно многое сделать. Вы можете поделиться своими идеями.
Панель мониторинга прогресса разработки:
v0.2.0: реализация базовых функций для обеспечения возможности применения решений для распространенных сценариев.
v0.3.0: реализована настройка сборщика, пользователи могут собирать то, что видят.
Я надеюсь, что каждый сможет предоставить образцы рекламы, чтобы повысить точность распознавания модели. См. файл примера: .files/datasets/ads.csv. Я установил следующий формат.
| заголовок | URL | is_process |
|---|---|---|
| Название рекламной статьи | Ссылка на рекламную статью | 0 |
Описание поля:
заголовок: название статьи
URL: ссылка на статью. Если вы хотите использовать статью WeChat, сначала проверьте, недействительна ли она.
is_process: указывает, следует ли выполнять выборочную обработку. По умолчанию введите 0 .
Приведем пример:
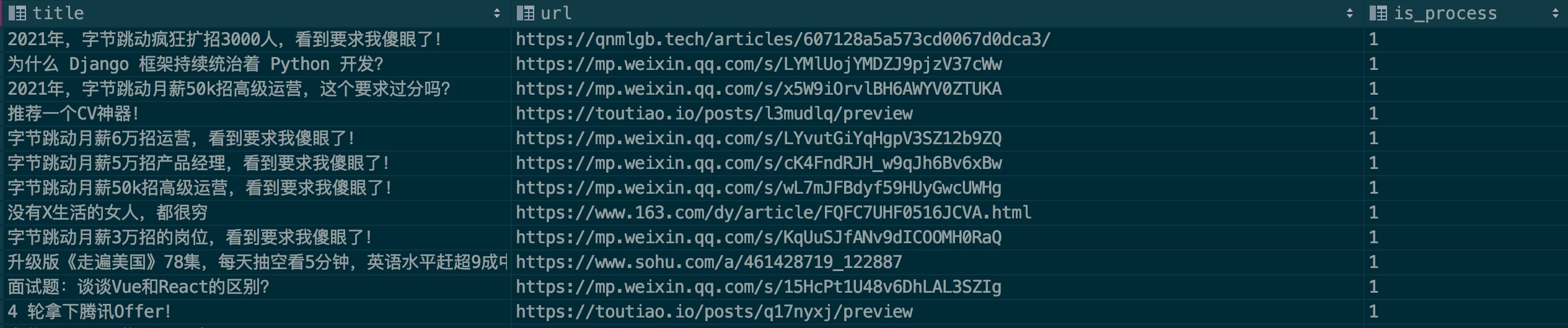
Как правило, реклама будет неоднократно размещаться на нескольких общедоступных аккаунтах. Пожалуйста, проверьте, существует ли эта запись, при ее заполнении. Я надеюсь, что каждый сможет внести свой вклад, дорогие, приходите и внесите свой вклад через PR!
Благодаря следующим проектам с открытым исходным кодом:
Flask: веб-фреймворк
Vue: прогрессивный фреймворк JavaScript.
Ruia: среда асинхронного сканера (разработана и используется самостоятельно).
драматург: Сбор данных с помощью браузера
Выше перечислены только основные зависимости с открытым исходным кодом. Дополнительные зависимости от третьих сторон см. в файле Pipfile.
Любой полученный вами пиар является мощной поддержкой проекта Liuli . Мы очень благодарны следующим разработчикам за их вклад (в произвольном порядке):
Приглашаем к совместному общению (подписаться на группу):


