ChatGPT WechatBot using OpenAI API via Wechty
1.0.0
ChatGPT-WechatBot — это робот, похожий на ChatGPT, реализованный с использованием диалоговой модели на основе официального API OpenAI и развертываемый в WeChat через платформу Wechaty для реализации чата робота.
ChatGPT WechatBot — это своего рода робот ChatGPT, основанный на официальном API OpenAI и использующий модель диалога. Он развертывается в WeChat через структуру Wechat для создания чата робота.
Примечание . Этот проект представляет собой локальную реализацию Win10 и не требует развертывания сервера (если требуется развертывание сервера, вы можете развернуть Docker на сервере).
(1), Windows10
(2), Докер 20.10.21
(3), Питон3.9
(4), Вечаты 0.10.7
1. Загрузите Докер
https://www.docker.com/products/docker-desktop/ Загрузите Docker.
2. Включите виртуализацию Win10.
Введите control в cmd, чтобы открыть панель управления и войти в программу, как показано на рисунке ниже:
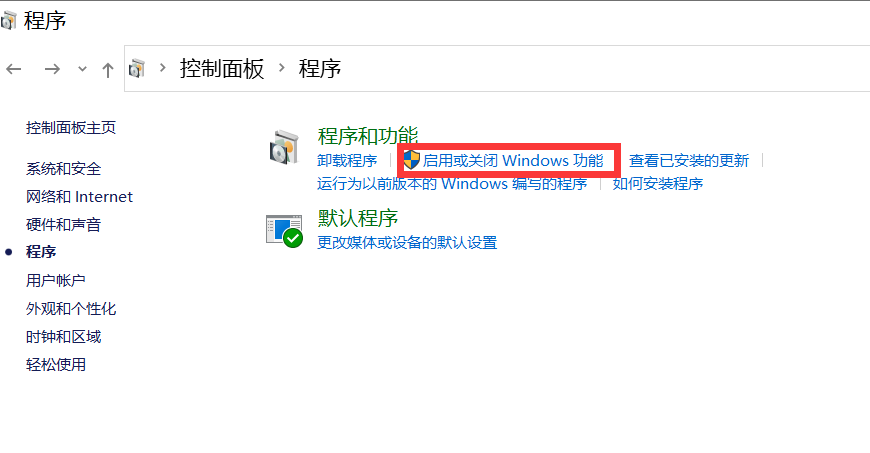
Перейдите в раздел «Включение или отключение функций Windows» и включите Hyper-V.
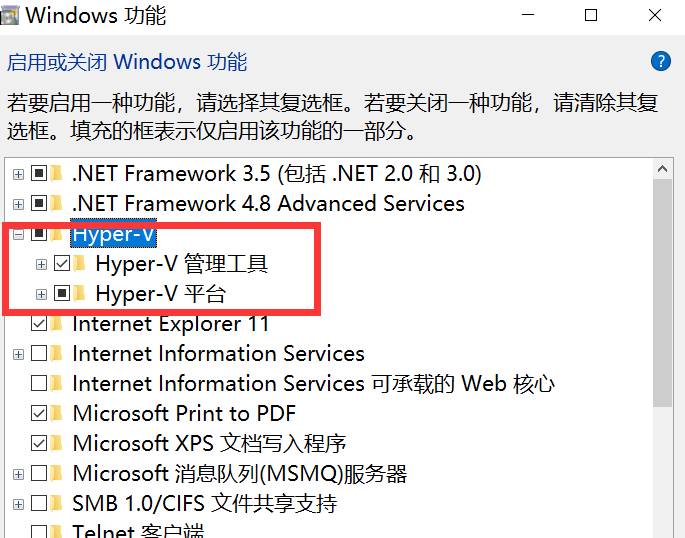
Примечание . Если на вашем компьютере нет Hyper-V, вам необходимо выполнить следующие операции:
Создайте текстовый документ, введите следующий код и назовите его Hyper.cmd.
pushd " %~dp0 "
dir /b %SystemRoot% s ervicing P ackages * Hyper-V * .mum > hyper-v.txt
for /f %%i in ( ' findstr /i . hyper-v.txt 2^>nul ' ) do dism /online /norestart /add-package: " %SystemRoot%servicingPackages%%i "
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALLЗатем запустите этот файл от имени администратора. После завершения работы сценария после перезагрузки компьютера появится узел Hyper-V .
3. Запустите Докер
Примечание . Если при первом запуске Docker происходит следующее:
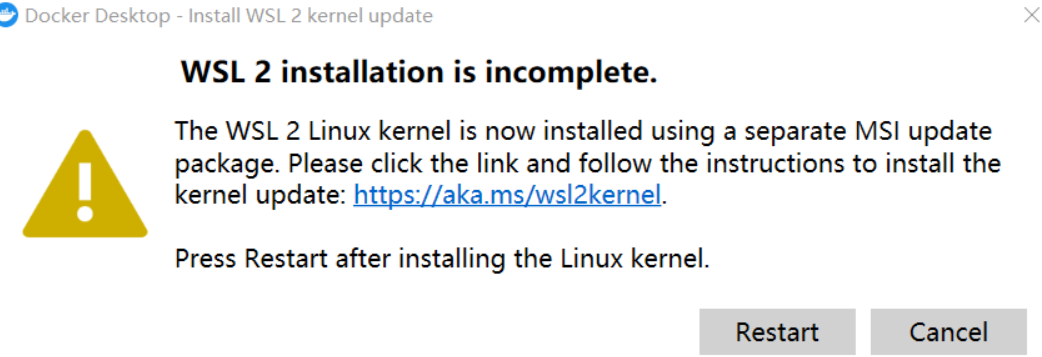
Необходимо загрузить последнюю версию пакета WSL 2.
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
После обновления вы можете войти на главную страницу, затем изменить настройки в движке докера и заменить изображение на отечественный образ Alibaba Cloud:
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"debug": false,
"experimental": false,
"features": {
"buildkit": true
},
"insecure-registries": [],
"registry-mirrors": [
"https://9cpn8tt6.mirror.aliyuncs.com"
]
}Так быстрее вытащить зеркало (для бытовых пользователей)
4. Загрузите изображение Wechaty :
docker pull wechaty:0 . 65Потому что в ходе тестирования выяснилось, что версия 0.65 вечаты самая стабильная.
После извлечения изображения:
Puppet : Если вы хотите использовать Wechaty для разработки робота WeChat, вам необходимо использовать промежуточное программное обеспечение Puppet для управления работой WeChat. Официальный перевод Puppet — puppet. В настоящее время доступно множество типов Puppet. Разница между различными версиями. Puppet — это различные функции робота, которые можно реализовать. Например, если вы хотите, чтобы ваш робот выгонял пользователей из группового чата, вам нужно использовать Puppet по протоколу Pad.
Подать заявку на подключение: http://pad-local.com/#/login
Примечание . После подачи заявки на учетную запись вы получите токен на 7 дней.
После подачи заявки на токен выполните следующую команду в окне cmd:
docker run - it - d -- name wechaty_test - e WECHATY_LOG="verbose" - e WECHATY_PUPPET="wechaty - puppet - padlocal" - e WECHATY_PUPPET_PADLOCAL_TOKEN="yourtoken" - e WECHATY_PUPPET_SERVER_PORT="8080" - e WECHATY_TOKEN="1fe5f846 - 3cfb - 401d - b20c - sailor==" - p "8080:8080" wechaty/wechaty:0 . 65
Описание параметра:
WECHATY_PUPPET_PADLOCAL_TOKEN : подать заявку на хороший токен.
**WECHATY_TOKEN **: просто напишите случайную строку, которая гарантированно будет уникальной.
WECHATY_PUPPET_SERVER_PORT : порт докер-сервера.
wechaty/wechaty:0.65 : версия изображения wechaty
Примечание. - «8080:8080»* — это порт вашего локального компьютера и сервера докеров. Обратите внимание, что порт сервера докеров должен соответствовать WECHATY_PUPPET_SERVER_PORT.
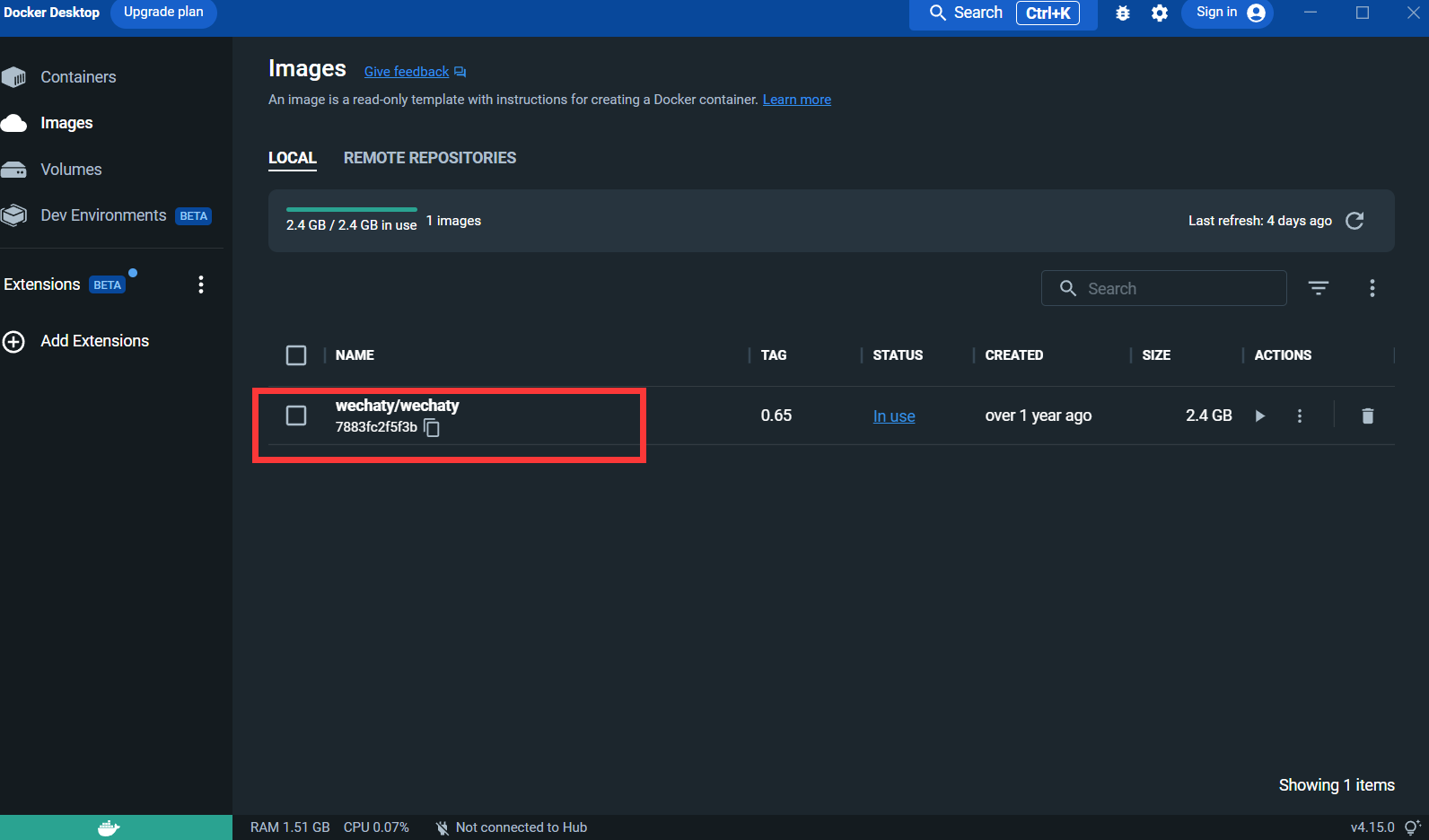
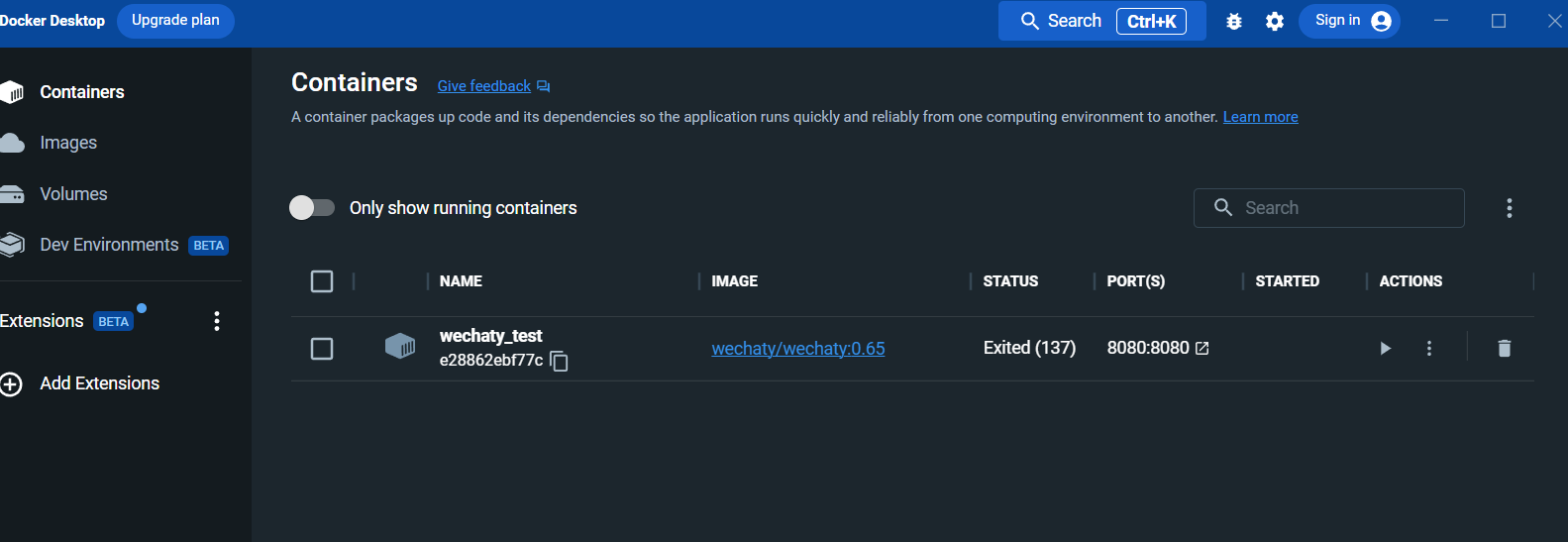
После запуска просмотрите контейнер на панели рабочего стола докера:
Войдите в интерфейс журнала:
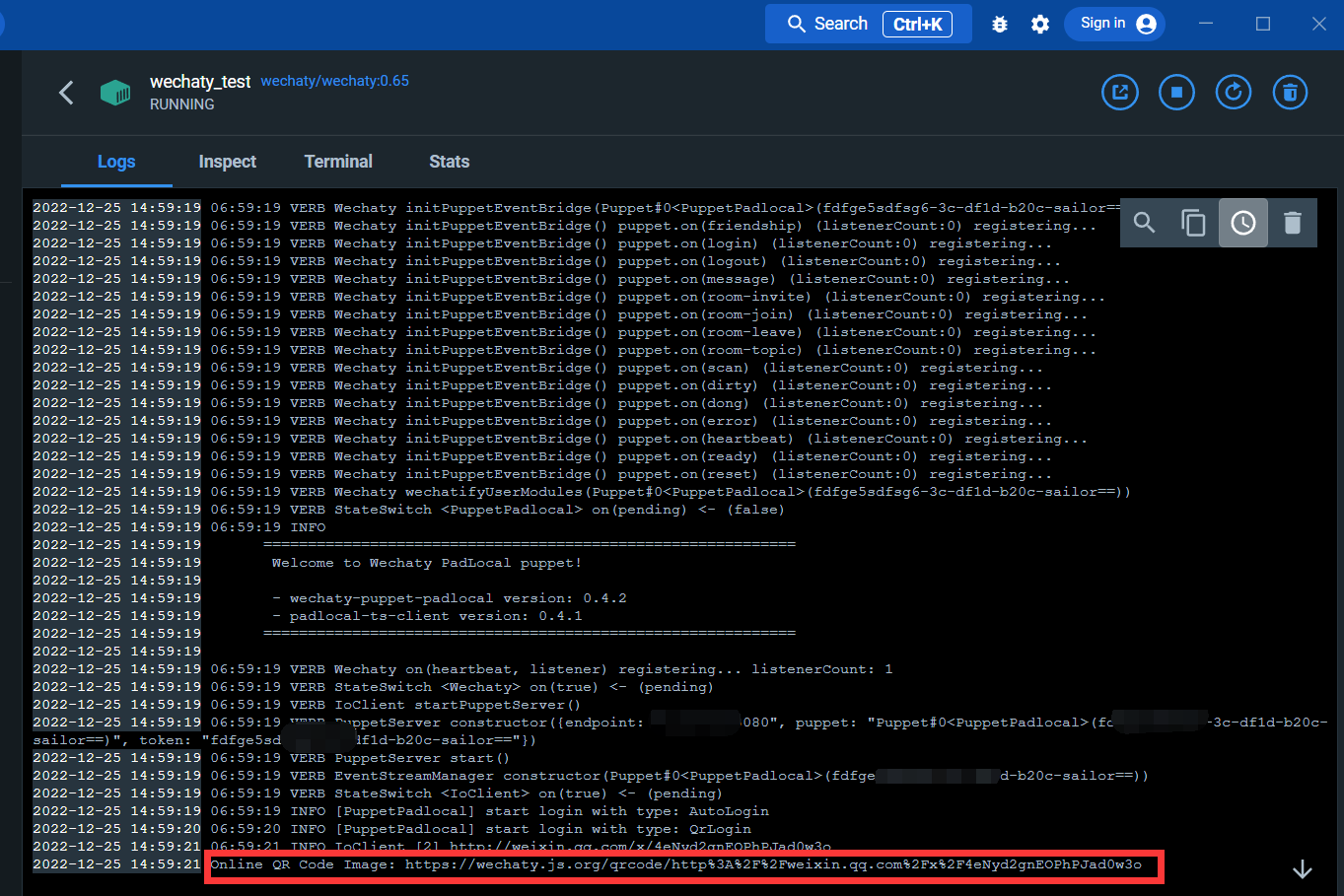
По ссылке ниже вы можете отсканировать QR-код, чтобы войти в WeChat.
После входа в систему служба Docker завершается.
Установите библиотеки wechaty и openai.
Откройте cmd и выполните следующую команду:
pip install wechaty
pip install openaiВойдите в openAI
https://beta.openai.com/
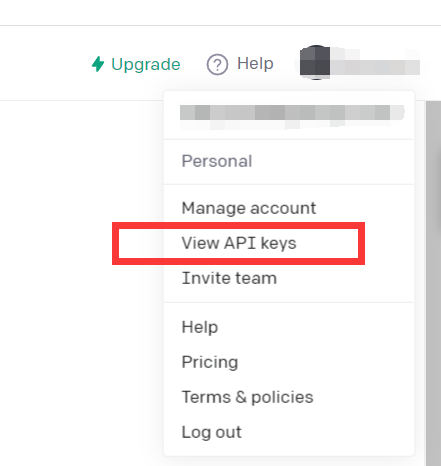
Нажмите «Просмотреть ключи API».
Просто получите API-ключ
На этом этапе среда настроена.
Вы можете попробовать прочитать этот демонстрационный код
import openai
openai . api_key = "your API-KEY"
start_sequence = "A:"
restart_sequence = "Q: "
while True :
print ( restart_sequence , end = "" )
prompt = input ()
if prompt == 'quit' :
break
else :
try :
response = openai . Completion . create (
model = "text-davinci-003" ,
prompt = prompt ,
temperature = 0.9 ,
max_tokens = 2000 ,
frequency_penalty = 0 ,
presence_penalty = 0
)
print ( start_sequence , response [ "choices" ][ 0 ][ "text" ]. strip ())
except Exception as exc :
print ( exc )
Этот код вызывает модель CPT-3, которая аналогична модели ChatGPT, и эффект ответа также хороший.
Модель openAI GPT-3 представлена следующим образом:
Наши модели GPT-3 могут понимать и генерировать естественный язык. Мы предлагаем четыре основные модели с разным уровнем мощности, подходящие для разных задач. Davinci — самая способная модель, а Ada — самая быстрая.
| ПОСЛЕДНЯЯ МОДЕЛЬ | ОПИСАНИЕ | МАКС. ЗАПРОС | ТРЕНИРОВОЧНЫЕ ДАННЫЕ |
|---|---|---|---|
| текст-давинчи-003 | Самая мощная модель GPT-3. Может выполнять любые задачи, которые могут выполнять другие модели, часто с более высоким качеством, более длительным выводом и лучшим следованием инструкциям. Также поддерживает вставку дополнений в текст. | 4000 жетонов | До июня 2021 г. |
| текст-кюри-001 | Очень мощный, но быстрее и дешевле, чем Давинчи. | 2048 токенов | До октября 2019 г. |
| текст-бэббидж-001 | Способен решать простые задачи, очень быстро и с меньшими затратами. | 2048 токенов | До октября 2019 г. |
| текст-ада-001 | Способен выполнять очень простые задачи, обычно самая быстрая модель серии GPT-3 и самая низкая стоимость. | 2048 токенов | До октября 2019 г. |
Хотя Давинчи, как правило, является наиболее функциональным, другие модели могут выполнять определенные задачи очень хорошо со значительным преимуществом в скорости или стоимости. Например, Кюри может выполнять многие из тех же задач, что и Давинчи, но быстрее и за 1/10 стоимости.
Мы рекомендуем использовать Davinci во время экспериментов, поскольку он даст наилучшие результаты. Как только все заработает, мы рекомендуем попробовать другие модели, чтобы посмотреть, сможете ли вы получить те же результаты с меньшей задержкой. Возможно, вы также сможете улучшить другую. производительность моделей путем точной настройки их под конкретную задачу.
Короче говоря, самая мощная модель GPT-3. Может делать все, что могут другие модели, обычно с более высоким качеством, большей производительностью и лучшим выполнением инструкций. Также поддерживается вставка дополнений в текст.
Хотя модель text-davinci-003 можно использовать непосредственно для достижения эффекта однораундного диалога в ChatGPT, однако, чтобы лучше достичь того же эффекта многораундового диалога, что и в ChatGPT, можно разработать модель диалога;
Основной принцип: сообщите модели text-davinci-003 контекст текущего разговора.
Метод реализации: спроектируйте очередь памяти диалогов, чтобы сохранить первые k раундов диалога текущего диалога, и сообщите модели text-davinci-003 содержание первых k раундов диалога, прежде чем задавать вопрос, а затем получите текущий ответ. через содержимое модели text-davinci-003
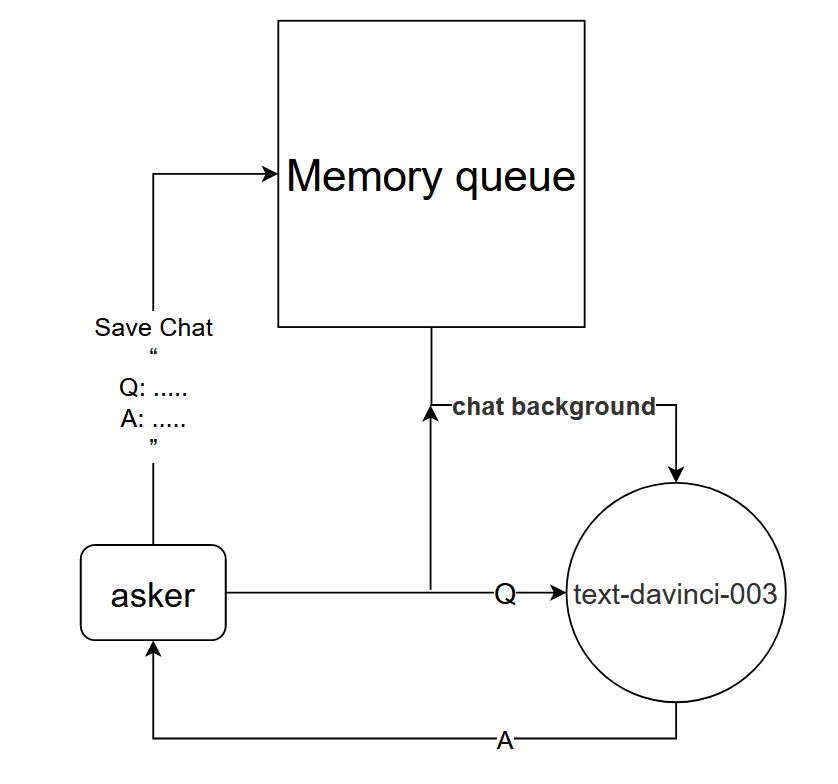
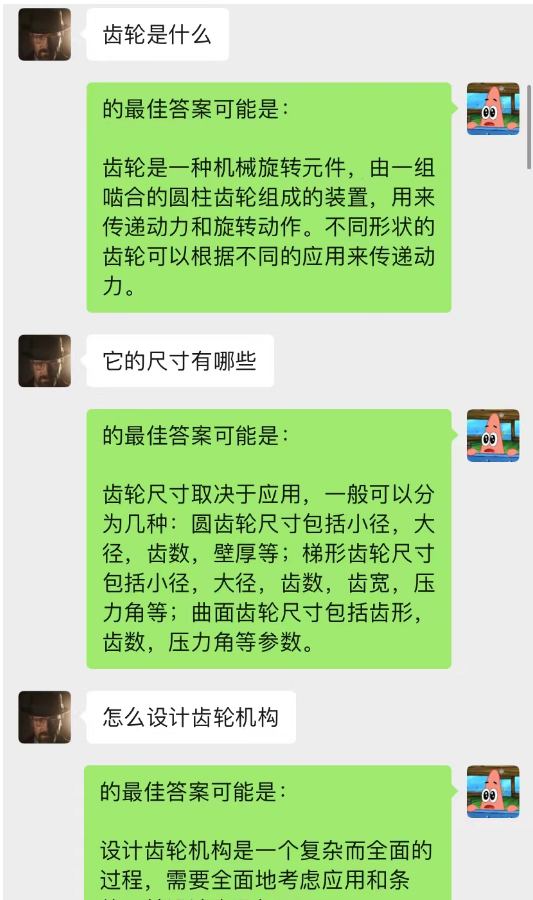
Этот метод работает на удивление хорошо! Дайте несколько записей чата
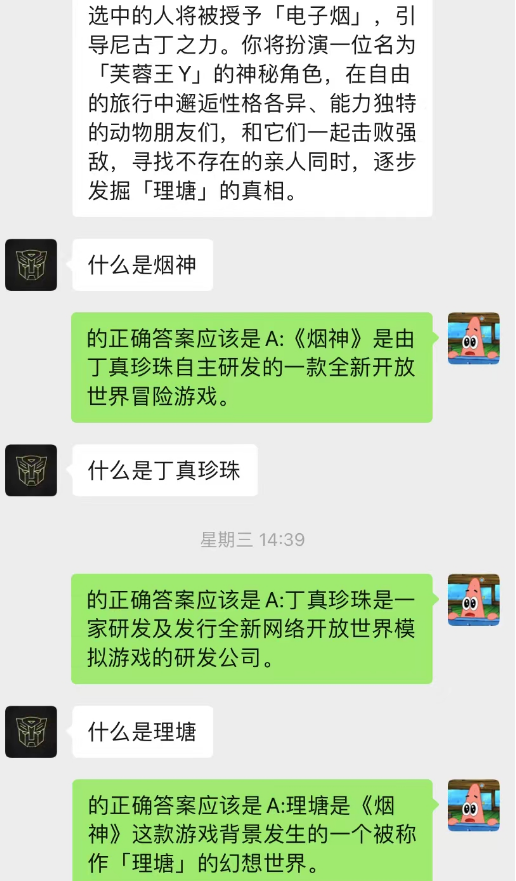
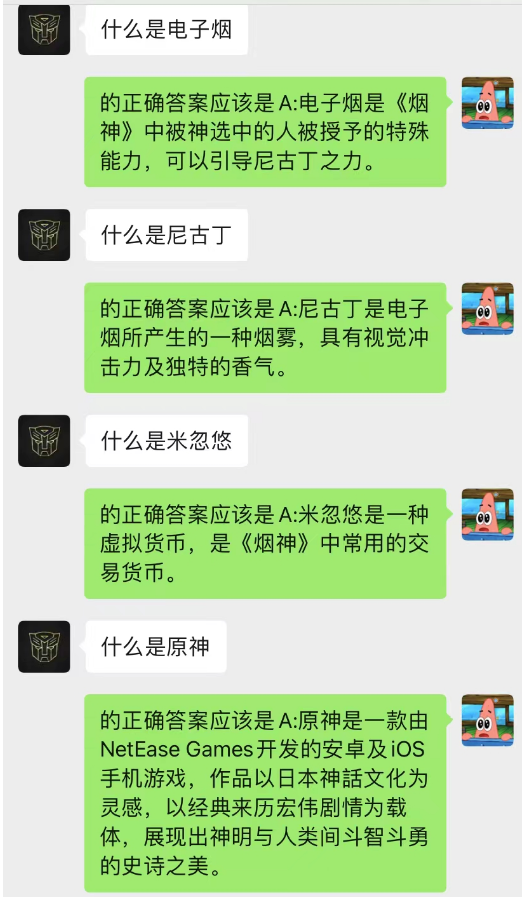
Видно, что в настоящее время фон чата также может использоваться, чтобы позволить ИИ завершить ситуационное обучение.
Мало того, вы также можете добиться того же написания статей с инструкциями, что и в ChatGPT.
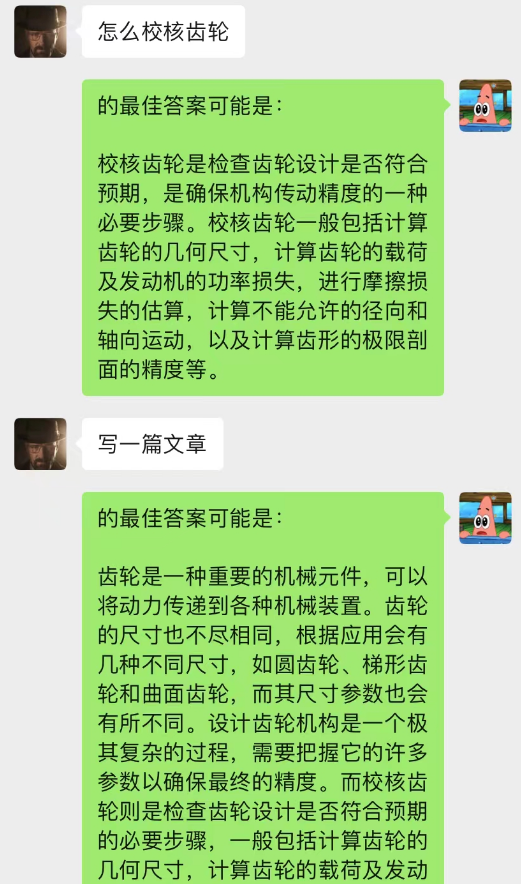
Эта модель представляет собой метод, который я сейчас разрабатываю для оптимизации модели диалога в фоновом режиме. Ее основная логика такая же, как и у модели языка N-грамм, за исключением того, что N динамически изменяется и добавляются марковские свойства для прогнозирования текущего диалога. контекст, чтобы определить, что этот раздел в фоне чата является наиболее важным, а затем использовать модель text-davinci-003, чтобы дать ответ на основе наиболее важного запомненного содержания разговора и текущей проблемы (что эквивалентно разрешению AI Сделайте это во время чата, используя предыдущий контент чата)
Реализация этой модели требует большого количества данных для обучения, а код еще не доработан.
------ Копание : после реализации кода обновите эту часть подробных шагов.
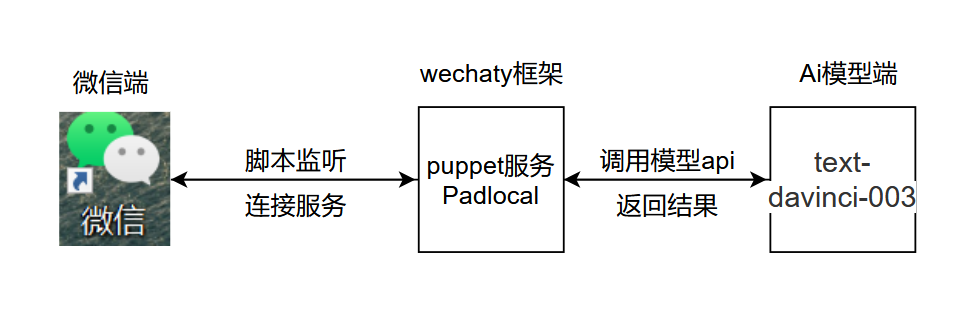
Основная логика проекта показана на рисунке ниже:
 .py, добавьте и откройте ChatGPT.py в указанном месте, добавьте секретный ключ и настройте переменные среды в указанном месте.
.py, добавьте и откройте ChatGPT.py в указанном месте, добавьте секретный ключ и настройте переменные среды в указанном месте.

Объяснение кода :
os . environ [ "WECHATY_PUPPET_SERVICE_TOKEN" ] = "填入你的Puppet的token" os . environ [ 'WECHATY_PUPPET' ] = 'wechaty-puppet-padlocal' #保证与docker中相同即可 os.environ['WECHATY_PUPPET_SERVICE_ENDPOINT'] = '主机ip:端口号'
Запустить успешно
1. Войдите в докер, не используйте wechaty-логин в python.
2. Установите в коде time.sleep(), чтобы имитировать скорость, с которой люди отвечают на сообщения.
3. Лучше не использовать большой размер при тестировании. Рекомендуется создать специальный небольшой размер для тестирования ИИ.
Содержимое этого проекта предназначено только для технических исследований и популяризации науки и не служит какой-либо убедительной основой. Он не дает разрешения на коммерческое применение и не несет ответственности за какие-либо действия.
~~электронная почта: [email protected]


