Цель этого репозитория - отслеживать некоторые аккуратные уловки GGPLOT2, которые я узнал. Это предполагает, что вы ознакомились с основными основаниями GGPLOT2 и можете построить несколько собственных сюжетов. Если нет, пожалуйста, просмотрите книгу в вашей аренде.
Я не невероятно приспосабливаюсь к великолепно наборным сюжетам и мастерскому настройки темы и цветовых палитр, так что вам придется простить меня. Набор данных mpg очень универсален для заговора, поэтому вы увидите многое, когда читаете дальше. Удлинительные пакеты великолепны, и я баловался, но я постараюсь ограничить себя ванильными трюками GGPLOT2 здесь.
На данный момент это будет в основном мешок с уловкой только для чтения, но позже я могу решить поместить их в отдельные группы в других файлах.
Загрузив библиотеку и установив тему сюжета. Первый трюк здесь состоит в том, чтобы использовать theme_set() , чтобы установить тему для всех ваших графиков на протяжении всего документа. Если вы обнаружите, что настраиваете очень многослойную тему для каждого сюжета, вот место, где вы устанавливаете все свои общие настройки. Тогда никогда больше никогда не пишите роман из элементов темы 1 !
library( ggplot2 )
library( scales )
theme_set(
# Pick a starting theme
theme_gray() +
# Add your favourite elements
theme(
axis.line = element_line(),
panel.background = element_rect( fill = " white " ),
panel.grid.major = element_line( " grey95 " , linewidth = 0.25 ),
legend.key = element_rect( fill = NA )
)
) Документация ?aes не говорит вам об этом, но вы можете развязать аргумент mapping в GGPLOT2. Что это значит? Ну, это означает, что вы можете составить аргумент mapping на ходу !!! Полем Это особенно изящно, если вам нужно время от времени перерабатывать эстетику.
my_mapping <- aes( x = foo , y = bar )
aes( colour = qux , !!! my_mapping )
# > Aesthetic mapping:
# > * `x` -> `foo`
# > * `y` -> `bar`
# > * `colour` -> `qux` Мое личное любимое использование этого - сделать цвет fill цветом colour , но немного легче 2 . Мы будем использовать систему отсроченной оценки для этого, after_scale() в этом случае, которую вы увидите в разделе, следующее за этим. Я повторяю этот трюк пару раз на протяжении всего документа.
my_fill <- aes( fill = after_scale(alpha( colour , 0.3 )))
ggplot( mpg , aes( displ , hwy )) +
geom_point(aes( colour = factor ( cyl ), !!! my_fill ), shape = 21 )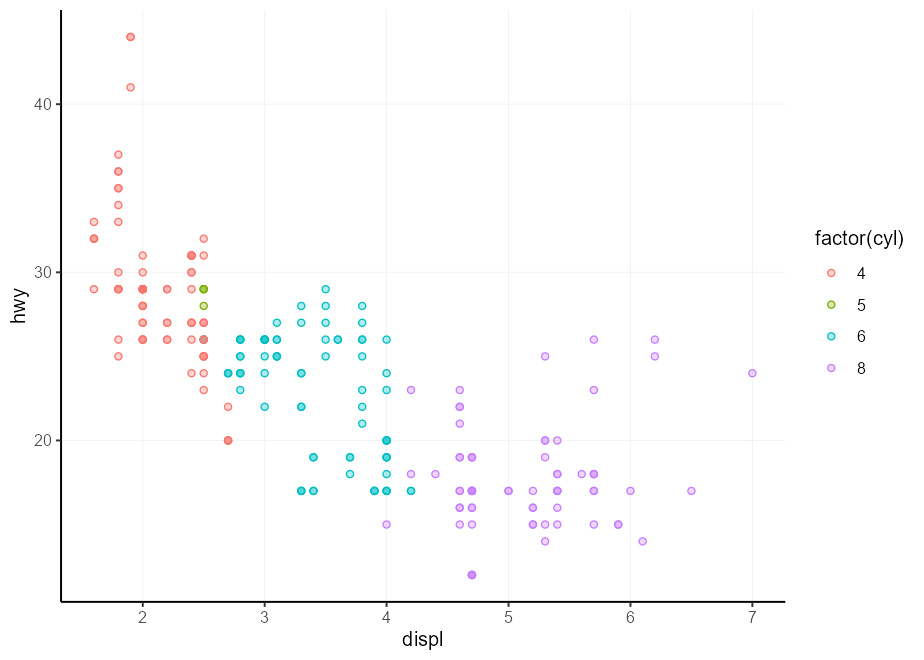
Вы можете оказаться в ситуации, когда вас просят сделать тепловую карту небольшого количества переменных. Как правило, последовательные масштабы работают от света до темноты или наоборот, что делает текст в одном цвете трудным для чтения. Мы могли бы разработать метод для автоматического записи текста белым на темном фоне и черного на легком фоне. Приведенная ниже функция учитывает значение легкостью для цвета и возвращает черный или белый в зависимости от этой легкость.
contrast <- function ( colour ) {
out <- rep( " black " , length( colour ))
light <- farver :: get_channel( colour , " l " , space = " hcl " )
out [ light < 50 ] <- " white "
out
} Теперь мы можем сделать эстетику, чтобы быть сплавкой в аргумент mapping слоя по требованию.
autocontrast <- aes( colour = after_scale(contrast( fill )))Наконец, мы можем проверить нашу автоматическую контрастную штуковину. Вы можете заметить, что он адаптируется к шкале, поэтому вам не нужно будет делать кучу условного форматирования для этого.
cors <- cor( mtcars )
# Melt matrix
df <- data.frame (
col = colnames( cors )[as.vector(col( cors ))],
row = rownames( cors )[as.vector(row( cors ))],
value = as.vector( cors )
)
# Basic plot
p <- ggplot( df , aes( row , col , fill = value )) +
geom_raster() +
geom_text(aes( label = round( value , 2 ), !!! autocontrast )) +
coord_equal()
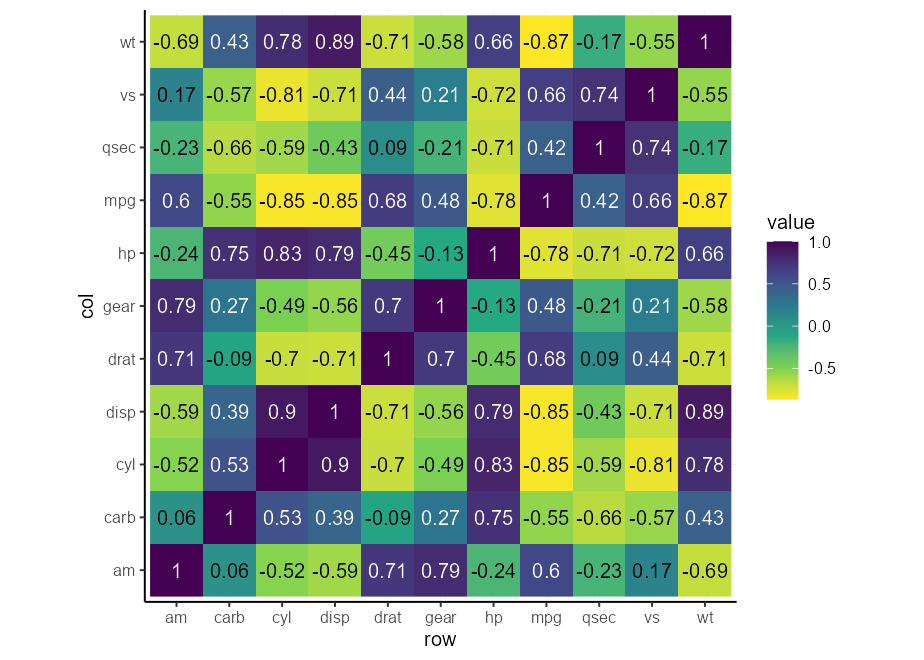
p + scale_fill_viridis_c( direction = 1 )
p + scale_fill_viridis_c( direction = - 1 )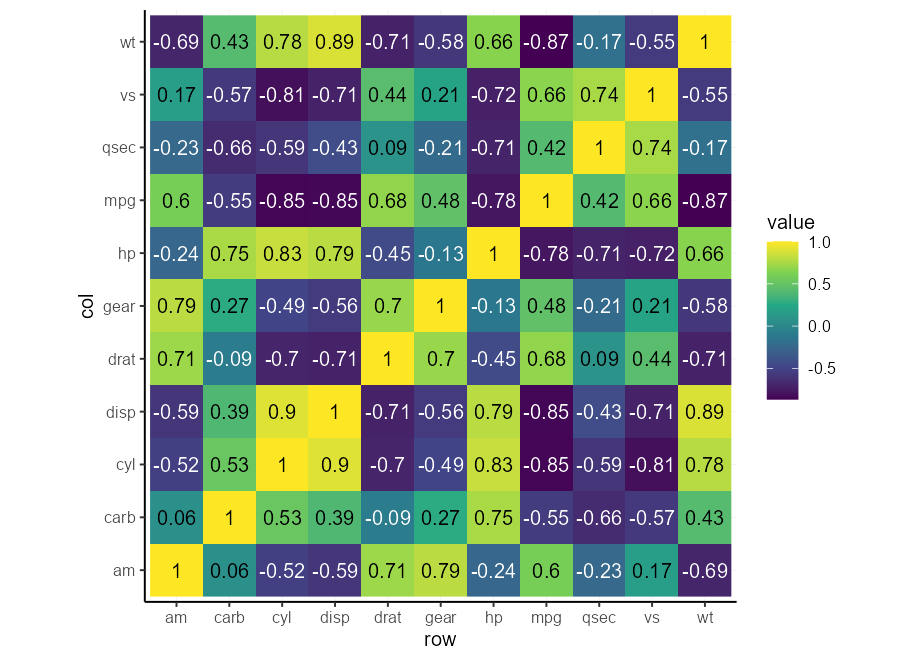
Есть некоторые расширения, которые предлагают половину версии вещей. Из тех, кого я знаю, Gghalves и See Package предлагают несколько полугемов.
Вот как злоупотреблять системой отсроченной оценки, чтобы сделать свою собственную. Это может пригодиться, если вы не хотите приобретать дополнительную зависимость только для этой функции.
Легкий корпус - это ящик. Вы можете установить xmin или xmax на after_scale(x) чтобы сохранить правую и левую часть ящика соответственно. Это все еще отлично работает с position = "dodge" .
# A basic plot to reuse for examples
p <- ggplot( mpg , aes( class , displ , colour = class , !!! my_fill )) +
guides( colour = " none " , fill = " none " ) +
labs( y = " Engine Displacement [L] " , x = " Type of car " )
p + geom_boxplot(aes( xmin = after_scale( x )))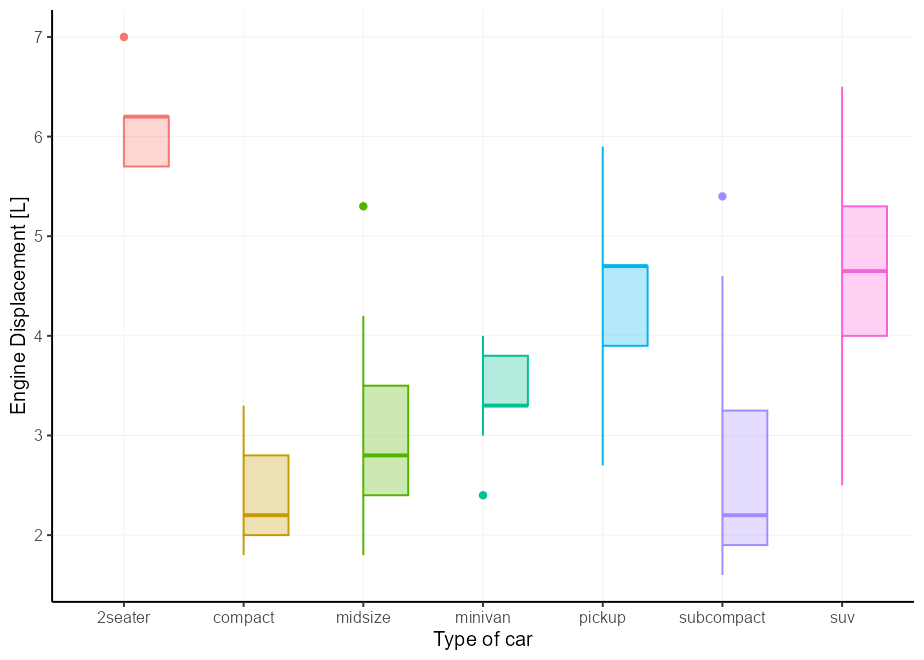
То же самое, что работает для ящиков, также работает для ошибок.
p + geom_errorbar(
stat = " summary " ,
fun.data = mean_se ,
aes( xmin = after_scale( x ))
)
Мы можем еще раз сделать то же самое для сюжетов на скрипке, но слой жалуется на то, что не знает об эстетике xmin . Он использует эту эстетику, но только после настройки данных, поэтому он не предназначен для того, чтобы быть доступной пользователем эстетикой. Мы можем замолчать предупреждение, обновив по умолчанию xmin до NULL , что означает, что оно не будет жаловаться, но также не использует его, если отсутствует.
update_geom_defaults( " violin " , list ( xmin = NULL ))
p + geom_violin(aes( xmin = after_scale( x )))
На этот раз не осталось упражнением для читателя, но я просто хотел показать, как это будет работать, если вы объедините две половины и хотите, чтобы они немного смещены друг от друга. Мы злоупотребляем планами ошибок, чтобы служить основными продуктами для ящиков.
# A small nudge offset
offset <- 0.025
# We can pre-specify the mappings if we plan on recycling some
right_nudge <- aes(
xmin = after_scale( x ),
x = stage( class , after_stat = x + offset )
)
left_nudge <- aes(
xmax = after_scale( x ),
x = stage( class , after_stat = x - offset )
)
# Combining
p +
geom_violin( right_nudge ) +
geom_boxplot( left_nudge ) +
geom_errorbar( left_nudge , stat = " boxplot " , width = 0.3 )
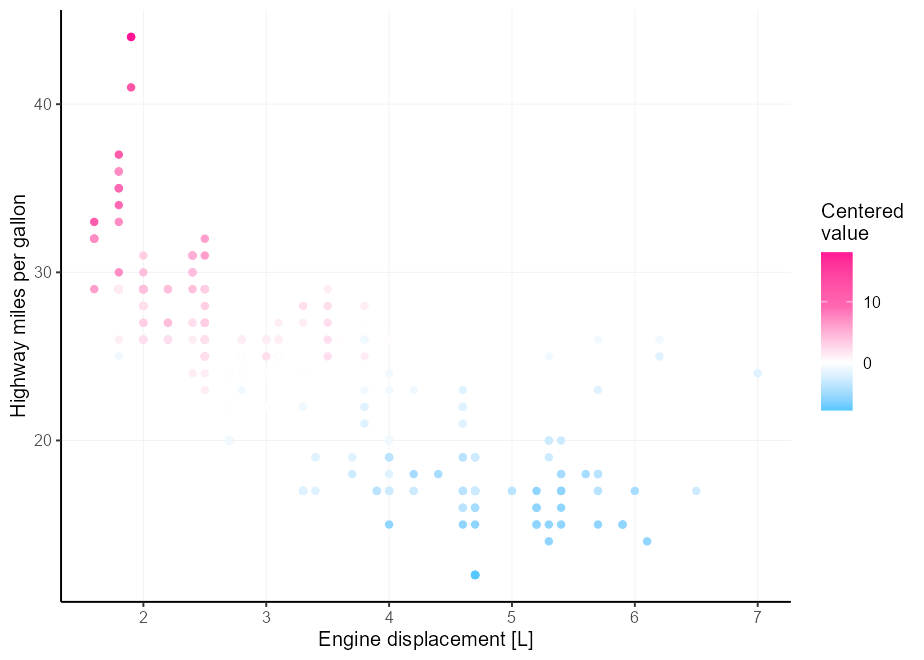
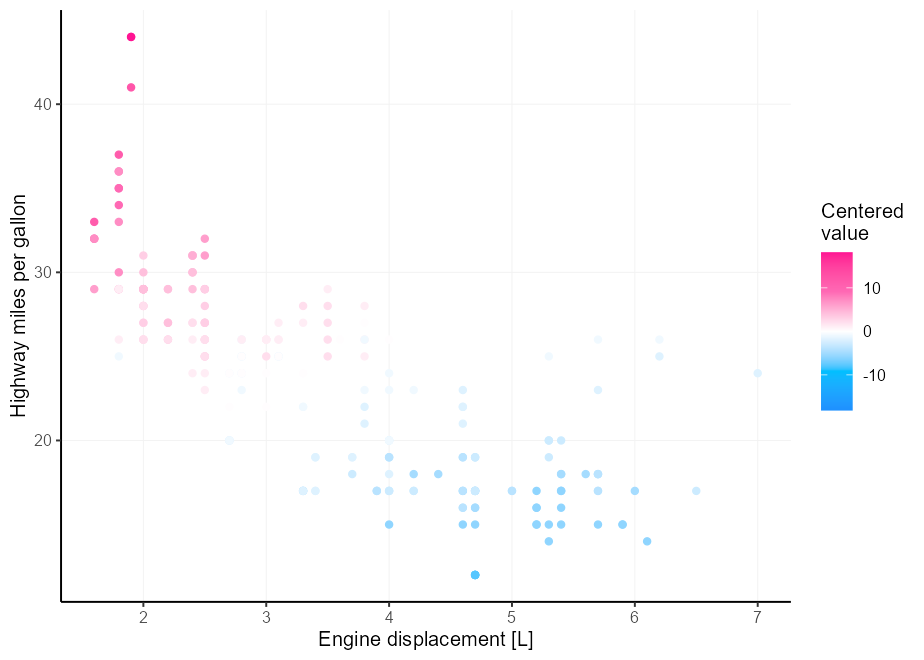
Допустим, у вас есть лучшая интуиция цвета, чем у меня, и трех цветов недостаточно для ваших потребностей в расходящейся цветовой палитре. Обезболивающая в том, что сложно получить правильную среднюю точку, если ваши ограничения не идеально сосредоточены вокруг нее. Введите аргумент rescaler в лиге с scales::rescale_mid() .
my_palette <- c( " dodgerblue " , " deepskyblue " , " white " , " hotpink " , " deeppink " )
p <- ggplot( mpg , aes( displ , hwy , colour = cty - mean( cty ))) +
geom_point() +
labs(
x = " Engine displacement [L] " ,
y = " Highway miles per gallon " ,
colour = " Centered n value "
)
p +
scale_colour_gradientn(
colours = my_palette ,
rescaler = ~ rescale_mid( .x , mid = 0 )
)
Альтернатива - просто сосредоточить пределы на x. Мы можем сделать это, предоставив функцию в пределах масштаба.
p +
scale_colour_gradientn(
colours = my_palette ,
limits = ~ c( - 1 , 1 ) * max(abs( .x ))
)
Вы можете пометить точки geom_text() , но потенциальная проблема заключается в том, что текст и точки перекрываются.
set.seed( 0 )
df <- USArrests [sample(nrow( USArrests ), 5 ), ]
df $ state <- rownames( df )
q <- ggplot( df , aes( Murder , Rape , label = state )) +
geom_point()
q + geom_text()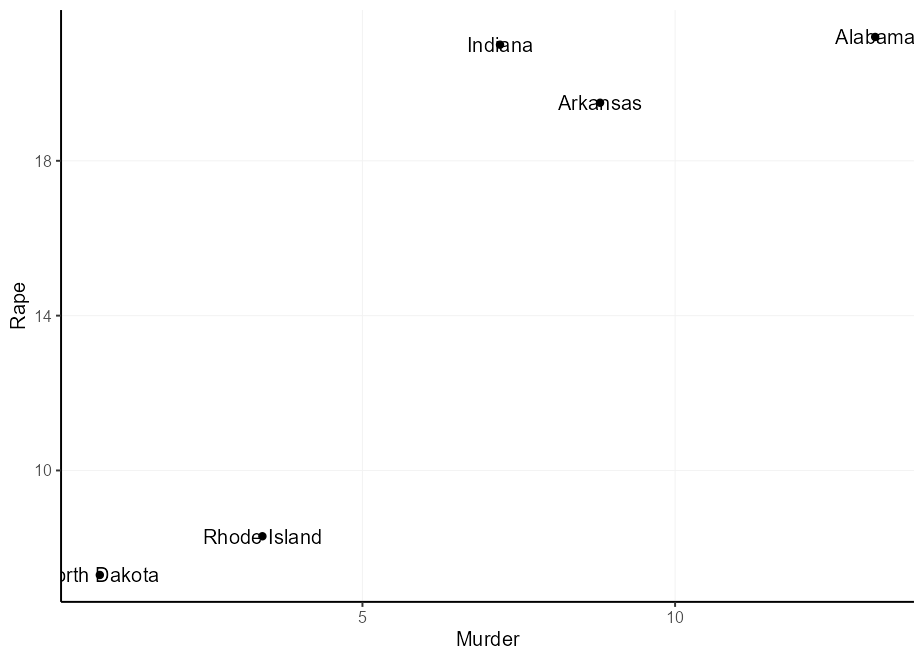
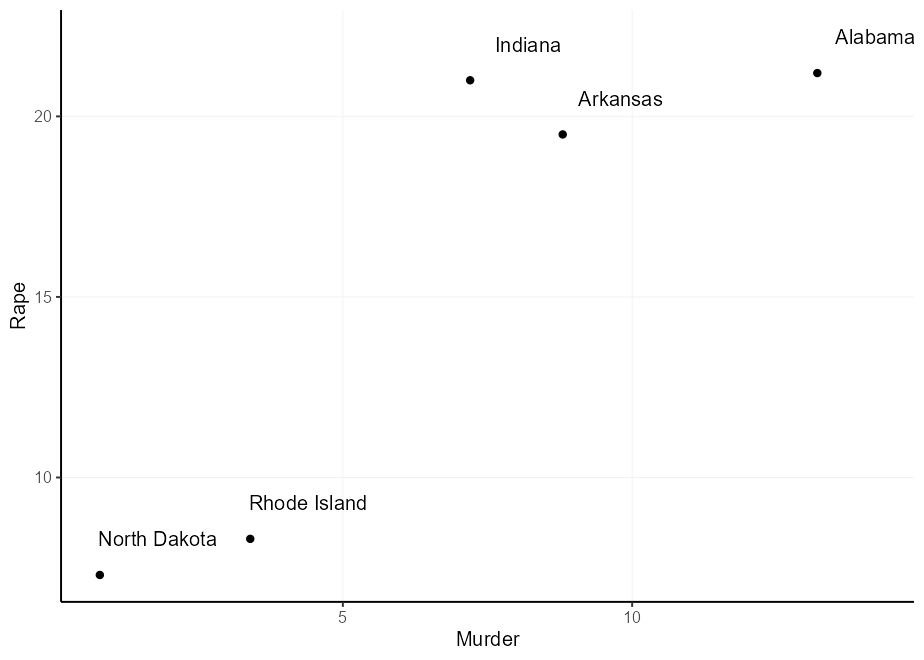
Есть несколько типичных решений этой проблемы, и все они поставляются с недостатками:
nudge_x и nudge_y . Проблема здесь заключается в том, что они определены в единицах данных, поэтому расстояние непредсказуемо, и их невозможно зависеть от исходных мест.hjust и vjust . Это позволяет вам зависеть от исходных мест, но они не имеют естественных смещений.Вот варианты 2 и 3 в действии:
q + geom_text( nudge_x = 1 , nudge_y = 1 )
q + geom_text(aes(
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
))
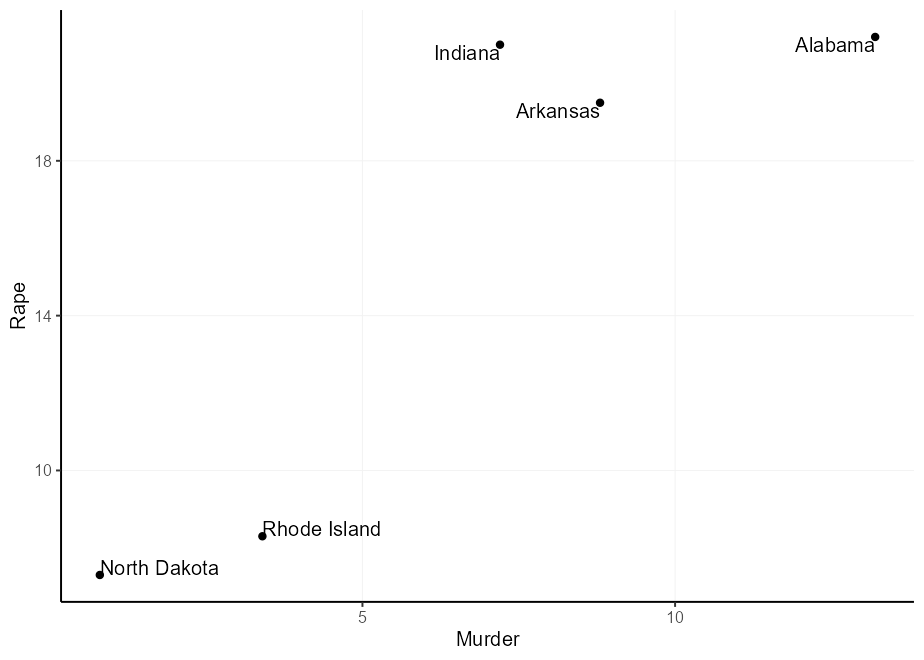
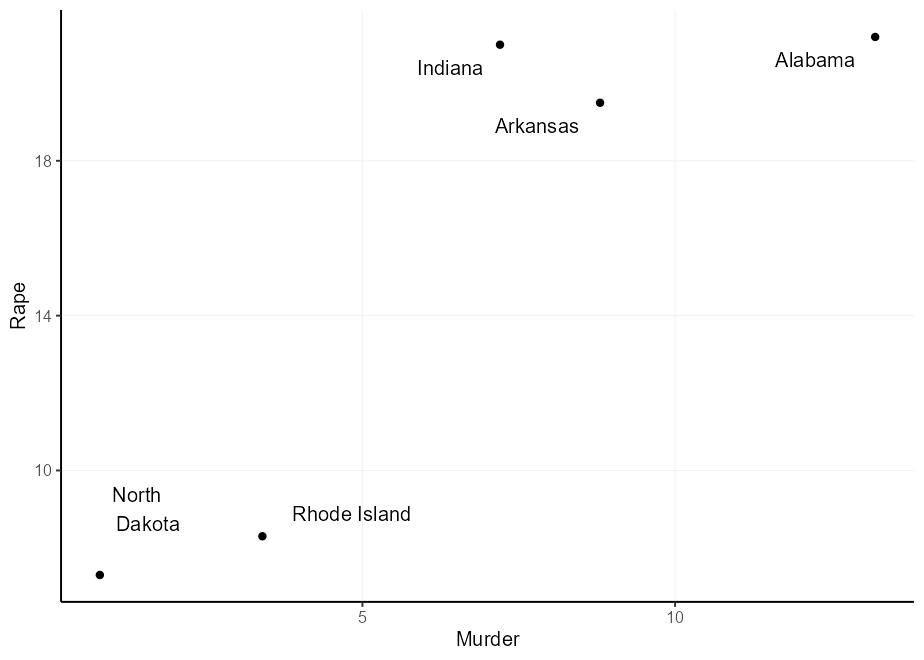
Вы можете подумать: «Я могу просто умножить оправдания, чтобы получить более широкое смещение», и вы будете правы. Однако, поскольку оправдание зависит от размера текста, вы можете получить неравные смещения. Заметите на указанном ниже участке, что «Северная Дакота» слишком компенсируется в направлении Y и «Род-Айленд» в направлении X.
q + geom_text(aes(
label = gsub( " North Dakota " , " North n Dakota " , state ),
hjust = (( Murder > mean( Murder )) - 0.5 ) * 1.5 + 0.5 ,
vjust = (( Rape > mean( Rape )) - 0.5 ) * 3 + 0.5
))
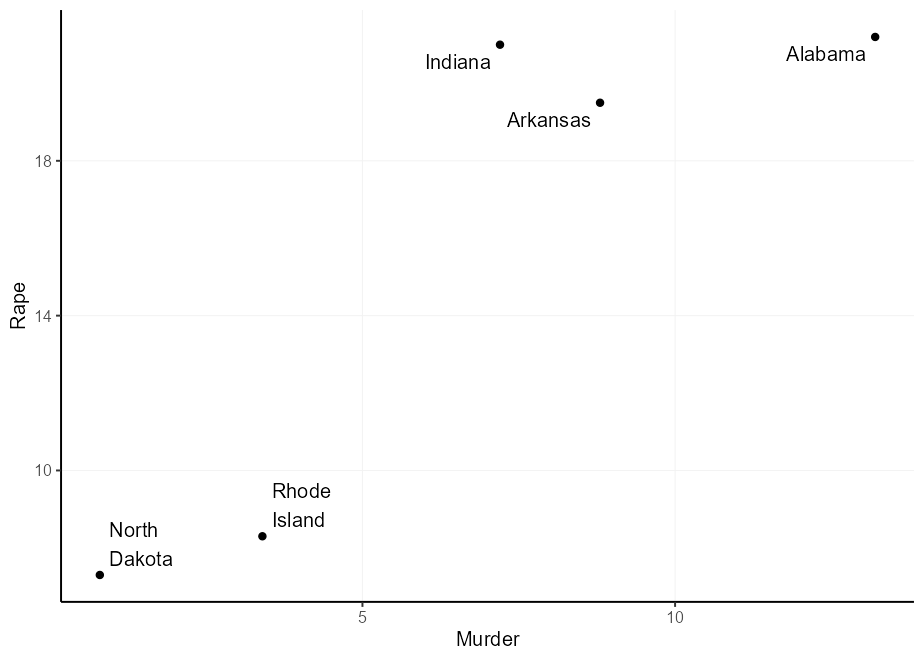
Хорошая вещь geom_label() заключается в том, что вы можете выключить коробку метки и сохранить текст. Таким образом, вы можете продолжать использовать другие полезные вещи, такие как настройка label.padding , чтобы дать абсолютное (независимое от данных) смещение от текста в метку.
q + geom_label(
aes(
label = gsub( " " , " n " , state ),
hjust = Murder > mean( Murder ),
vjust = Rape > mean( Rape )
),
label.padding = unit( 5 , " pt " ),
label.size = NA , fill = NA
)
Раньше это был совет по поводу размещения фасеточных метков на панели, что раньше было сложным. С GGPLOT2 3.5.0 вам больше не придется возиться с установкой бесконечных позиций и настраивая параметры hjust или vjust . Теперь вы можете просто использовать x = I(0.95), y = I(0.95) чтобы поместить текст в верхнем правом углу. Откройте детали, чтобы увидеть старый совет.
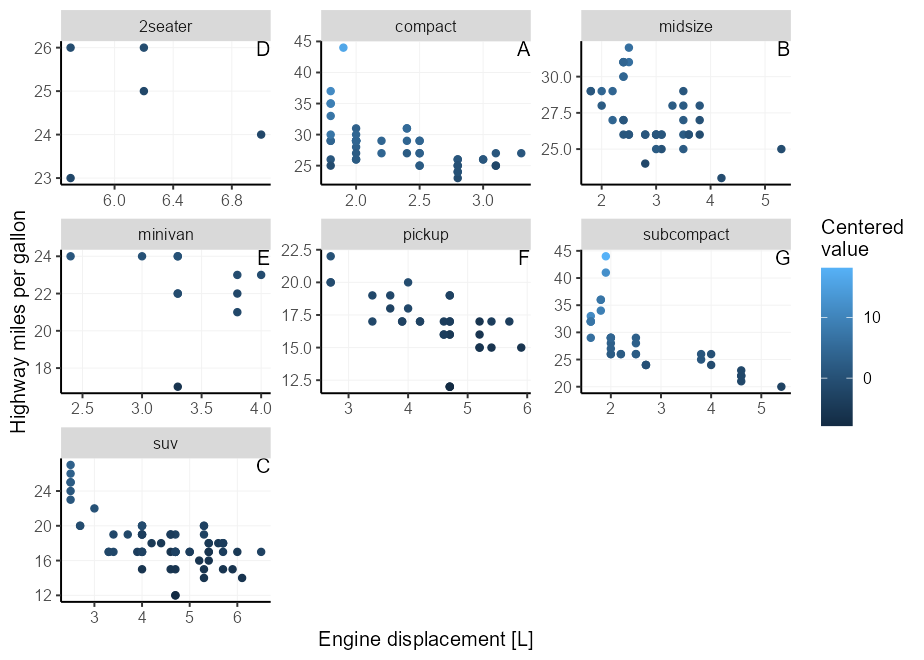
Размещение текстовых аннотаций на огражденные участки-это боль, потому что ограничения могут варьироваться в зависимости от панели, поэтому очень трудно найти правильное положение. Расширение, которое исследует облегчение этой боли, - это расширение Tagger, но мы можем сделать аналогичную вещь в Vanilla GGPLOT2.
К счастью, в осях положения GGPLOT2 есть механик, которая позволяет -Inf и Inf интерпретироваться как минимальный и максимальный предел шкалы соответственно 3 . Вы можете использовать это, выбрав x = Inf, y = Inf чтобы положить этикетки в угол. Вы также можете использовать -Inf вместо Inf для размещения на дне вместо сверху или влево вместо правого.
Нам нужно соответствовать аргументам hjust / vjust с стороной сюжета. Для x/y = Inf они должны быть hjust/vjust = 1 , а для x/y = -Inf они должны быть hjust/vjust = 0 .
p + facet_wrap( ~ class , scales = " free " ) +
geom_text(
# We only need 1 row per facet, so we deduplicate the facetting variable
data = ~ subset( .x , ! duplicated( class )),
aes( x = Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 1 , vjust = 1 ,
colour = " black "
)
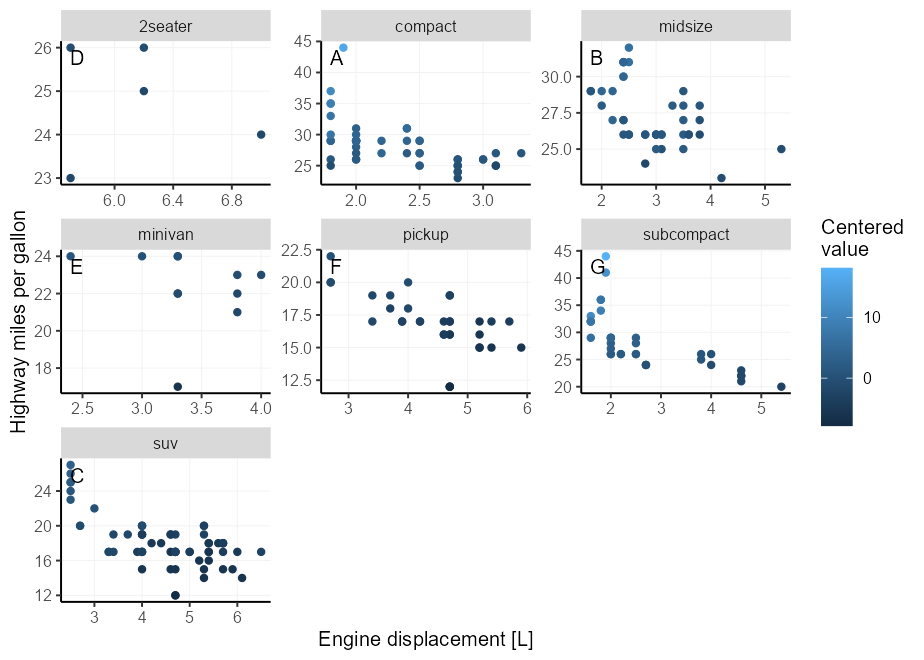
К сожалению, это помещает текст прямо на границе панели, что может оскорбить наше чувство красоты. Мы можем стать немного причудливым, используя geom_label() , который позволяет нам более точно контролировать расстояние между текстом и границей панели, установив аргумент label.padding .
Кроме того, мы можем использовать label.size = NA, fill = NA чтобы скрыть часть Textbox Geom. В целях иллюстрации мы теперь размещаем метку в верхней левой вместо вершины.
p + facet_wrap( ~ class , scales = " free " ) +
geom_label(
data = ~ subset( .x , ! duplicated( class )),
aes( x = - Inf , y = Inf , label = LETTERS [seq_along( class )]),
hjust = 0 , vjust = 1 , label.size = NA , fill = NA ,
label.padding = unit( 5 , " pt " ),
colour = " black "
)
Допустим, нам поручено создать кучу похожих сюжетов, с различными наборами данных и столбцами. Например, мы могли бы захотеть сделать серию баржеров 4 с некоторыми конкретными предварительными сетями: мы хотели бы, чтобы бары касались оси X, а не рисовать вертикальные сетки.
Одним из известных способов создать кучу похожих сюжетов является завершение конструкции сюжета в функцию. Таким образом, вы можете использовать кодирование всех пресетов, которые вы хотите в вашей функции.
Если вы можете не знать, существуют различные методы для программирования с функцией aes() , и использование {{ }} (кудрявый) является одним из наиболее гибких способов 5 .
barplot_fun <- function ( data , x ) {
ggplot( data , aes( x = {{ x }})) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.05 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class )
Одним из недостатков этого подхода является то, что вы блокируете любую эстетику в функциональных аргументах. Чтобы обойти это, еще более простой способ - просто пройти ... непосредственно к aes() .
barplot_fun <- function ( data , ... ) {
ggplot( data , aes( ... )) +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
}
barplot_fun( mpg , class , colour = factor ( cyl ), !!! my_fill )
Другой метод выполнения очень похожей вещи - использовать сюжет «скелеты». Идея скелета заключается в том, что вы можете создать сюжет, с каким -либо аргументом data или без него, и добавить в специфику позже. Затем, когда вы действительно хотите создать сюжет, вы можете использовать %+% чтобы заполнить или заменить набор данных, и + aes(...) чтобы установить соответствующую эстетику.
barplot_skelly <- ggplot() +
geom_bar( width = 0.618 ) +
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )) +
theme( panel.grid.major.x = element_blank())
my_plot <- barplot_skelly % + % mpg +
aes( class , colour = factor ( cyl ), !!! my_fill )
my_plot 
Одна из них в этих скелетах заключается в том, что даже когда вы уже заполняли data и mapping аргументы, вы можете просто заменить их снова и снова.
my_plot % + % mtcars +
aes( factor ( carb ), colour = factor ( cyl ), !!! my_fill )
Идея здесь состоит в том, чтобы не скелететь весь сюжет, а просто часто повторный набор частей. Например, мы могли бы захотеть пометить наш барпло и собрать все вещи, которые составляют маркированный барпло. Хитрость к этому состоит в том, чтобы не добавлять эти компоненты вместе с + , а просто положить их в list() . Затем вы можете + ваш список вместе с основным вызовом сюжета.
labelled_bars <- list (
geom_bar( my_fill , width = 0.618 ),
geom_text(
stat = " count " ,
aes( y = after_stat( count ),
label = after_stat( count ),
fill = NULL , colour = NULL ),
vjust = - 1 , show.legend = FALSE
),
scale_y_continuous( expand = c( 0 , 0 , 0.1 , 0 )),
theme( panel.grid.major.x = element_blank())
)
ggplot( mpg , aes( class , colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mpg` dataset " )
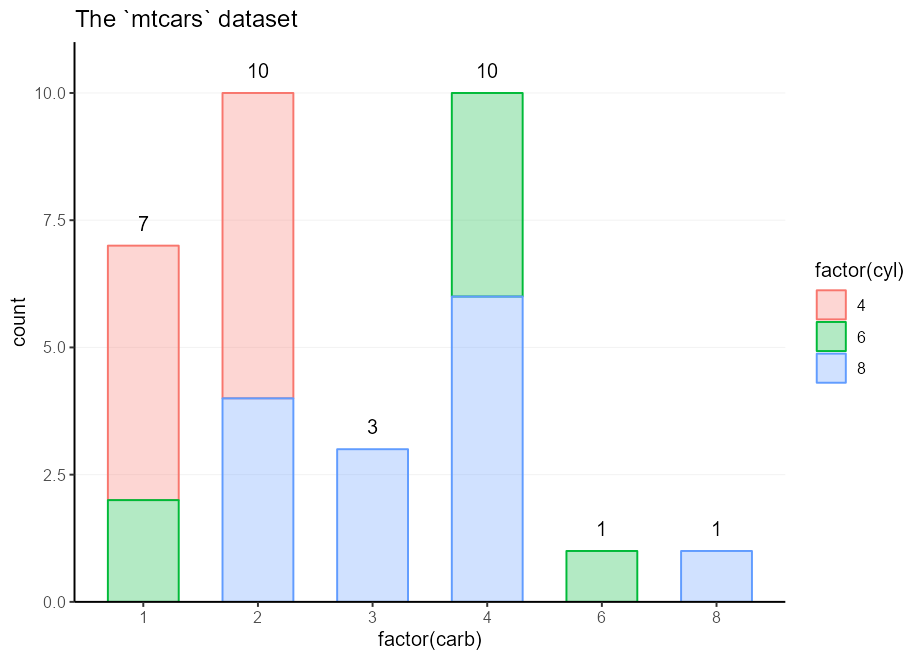
ggplot( mtcars , aes( factor ( carb ), colour = factor ( cyl ))) +
labelled_bars +
ggtitle( " The `mtcars` dataset " )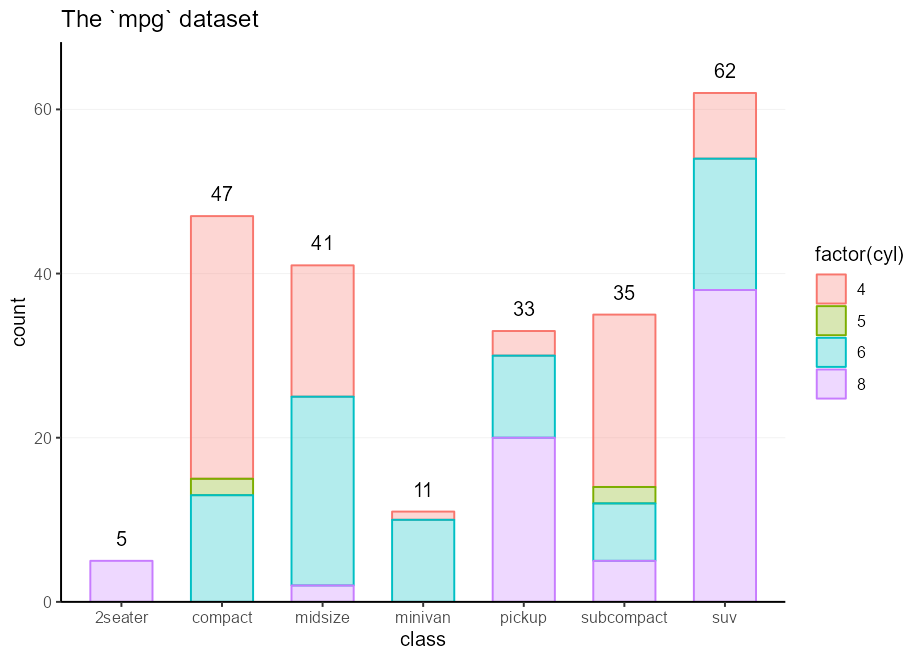
#> ─ Session info ───────────────────────────────────────────────────────────────
#> setting value
#> version R version 4.3.2 (2023-10-31 ucrt)
#> os Windows 11 x64 (build 22631)
#> system x86_64, mingw32
#> ui RTerm
#> language (EN)
#> collate English_Netherlands.utf8
#> ctype English_Netherlands.utf8
#> tz Europe/Amsterdam
#> date 2024-02-27
#> pandoc 3.1.1
#>
#> ─ Packages ───────────────────────────────────────────────────────────────────
#> package * version date (UTC) lib source
#> cli 3.6.2 2023-12-11 [] CRAN (R 4.3.2)
#> colorspace 2.1-0 2023-01-23 [] CRAN (R 4.3.2)
#> digest 0.6.34 2024-01-11 [] CRAN (R 4.3.2)
#> dplyr 1.1.4 2023-11-17 [] CRAN (R 4.3.2)
#> evaluate 0.23 2023-11-01 [] CRAN (R 4.3.2)
#> fansi 1.0.6 2023-12-08 [] CRAN (R 4.3.2)
#> farver 2.1.1 2022-07-06 [] CRAN (R 4.3.2)
#> fastmap 1.1.1 2023-02-24 [] CRAN (R 4.3.2)
#> generics 0.1.3 2022-07-05 [] CRAN (R 4.3.2)
#> ggplot2 * 3.5.0.9000 2024-02-27 [] local
#> glue 1.7.0 2024-01-09 [] CRAN (R 4.3.2)
#> gtable 0.3.4 2023-08-21 [] CRAN (R 4.3.2)
#> highr 0.10 2022-12-22 [] CRAN (R 4.3.2)
#> htmltools 0.5.7 2023-11-03 [] CRAN (R 4.3.2)
#> knitr 1.45 2023-10-30 [] CRAN (R 4.3.2)
#> labeling 0.4.3 2023-08-29 [] CRAN (R 4.3.1)
#> lifecycle 1.0.4 2023-11-07 [] CRAN (R 4.3.2)
#> magrittr 2.0.3 2022-03-30 [] CRAN (R 4.3.2)
#> munsell 0.5.0 2018-06-12 [] CRAN (R 4.3.2)
#> pillar 1.9.0 2023-03-22 [] CRAN (R 4.3.2)
#> pkgconfig 2.0.3 2019-09-22 [] CRAN (R 4.3.2)
#> R6 2.5.1 2021-08-19 [] CRAN (R 4.3.2)
#> ragg 1.2.7 2023-12-11 [] CRAN (R 4.3.2)
#> rlang 1.1.3 2024-01-10 [] CRAN (R 4.3.2)
#> rmarkdown 2.25 2023-09-18 [] CRAN (R 4.3.2)
#> rstudioapi 0.15.0 2023-07-07 [] CRAN (R 4.3.2)
#> scales * 1.3.0 2023-11-28 [] CRAN (R 4.3.2)
#> sessioninfo 1.2.2 2021-12-06 [] CRAN (R 4.3.2)
#> systemfonts 1.0.5 2023-10-09 [] CRAN (R 4.3.2)
#> textshaping 0.3.7 2023-10-09 [] CRAN (R 4.3.2)
#> tibble 3.2.1 2023-03-20 [] CRAN (R 4.3.2)
#> tidyselect 1.2.0 2022-10-10 [] CRAN (R 4.3.2)
#> utf8 1.2.4 2023-10-22 [] CRAN (R 4.3.2)
#> vctrs 0.6.5 2023-12-01 [] CRAN (R 4.3.2)
#> viridisLite 0.4.2 2023-05-02 [] CRAN (R 4.3.2)
#> withr 3.0.0 2024-01-16 [] CRAN (R 4.3.2)
#> xfun 0.41 2023-11-01 [] CRAN (R 4.3.2)
#> yaml 2.3.8 2023-12-11 [] CRAN (R 4.3.2)
#>
#>
#> ──────────────────────────────────────────────────────────────────────────────
Ну, вам нужно сделать это один раз в начале вашего документа. Но потом никогда больше! Кроме как в вашем следующем документе. Просто напишите сценарий и source() plot_defaults.R , который из вашего документа. Скопируйте этот сценарий для каждого проекта. Тогда, действительно, никогда больше: Сердце:. ↩
Это ложь. В действительности я использую aes(colour = after_scale(colorspace::darken(fill, 0.3))) вместо освещения заполнения. Я не хотел, чтобы этот Readme имел зависимость от {colorspace}, хотя. ↩
Если вы не саботаете свои сюжеты, установив, например, oob = scales::oob_censor_any в шкале. ↩
В своей душе души вы действительно хотите сделать кучу барных заводов? ↩
Альтернатива состоит в том, чтобы использовать местоимение .data , которое может быть .data$var , если вы хотите заранее заблокировать этот столбец, или .data[[var]] когда var передается в качестве символа. ↩
Этот бит изначально назывался «частичный скелет», но в качестве грудной клетки является частью скелета, этот заголовок звучал более вызывающе. ↩


