whisper.cpp
v1.7.2
Стабильная: v1.7.2 / Roadmap | Часто задаваемые вопросы
Высокопроизводительный вывод модели автоматического распознавания речи Openai (ASR):
Поддерживаемые платформы:
Вся реализация модели высокого уровня содержится в Whisper.h и Whisper.cpp. Остальная часть кода является частью библиотеки машинного обучения ggml .
Наличие такой легкой реализации модели позволяет легко интегрировать ее в разные платформы и приложения. В качестве примера, вот видео о запуске модели на устройстве iPhone 13 - полностью офлайн, на Device: Whisper.objc
Вы также можете легко сделать свое собственное автономное приложение голосового помощника: команда
На яблоне кремния логический вывод полностью работает на графическом процессоре через металл:
Или вы даже можете запустить его прямо в браузере: Talk.wasm
Тенсорные операторы сильно оптимизированы для процессоров Apple Silicon. В зависимости от размера вычислений, используются внутренние витрины Arm Neon SIMD или CBLA. Последние особенно эффективны для больших размеров, так как рамка Accelerate использует специальный Coprocessor AMX, доступный в современных продуктах Apple.
Сначала клонировать репозиторий:
git clone https://github.com/ggerganov/whisper.cpp.gitПерейдите в каталог:
cd whisper.cpp
Затем загрузите одну из моделей Whisper, преобразованной в формате ggml . Например:
sh ./models/download-ggml-model.sh base.enТеперь создайте основной пример и транскрибируйте аудиофайл таким образом:
# build the main example
make -j
# transcribe an audio file
./main -f samples/jfk.wav Для быстрого демонстрации, просто запустите, make base.en :
$ make -j base.en
cc -I. -O3 -std=c11 -pthread -DGGML_USE_ACCELERATE -c ggml.c -o ggml.o
c++ -I. -I./examples -O3 -std=c++11 -pthread -c whisper.cpp -o whisper.o
c++ -I. -I./examples -O3 -std=c++11 -pthread examples/main/main.cpp whisper.o ggml.o -o main -framework Accelerate
./main -h
usage: ./main [options] file0.wav file1.wav ...
options:
-h, --help [default] show this help message and exit
-t N, --threads N [4 ] number of threads to use during computation
-p N, --processors N [1 ] number of processors to use during computation
-ot N, --offset-t N [0 ] time offset in milliseconds
-on N, --offset-n N [0 ] segment index offset
-d N, --duration N [0 ] duration of audio to process in milliseconds
-mc N, --max-context N [-1 ] maximum number of text context tokens to store
-ml N, --max-len N [0 ] maximum segment length in characters
-sow, --split-on-word [false ] split on word rather than on token
-bo N, --best-of N [5 ] number of best candidates to keep
-bs N, --beam-size N [5 ] beam size for beam search
-wt N, --word-thold N [0.01 ] word timestamp probability threshold
-et N, --entropy-thold N [2.40 ] entropy threshold for decoder fail
-lpt N, --logprob-thold N [-1.00 ] log probability threshold for decoder fail
-debug, --debug-mode [false ] enable debug mode (eg. dump log_mel)
-tr, --translate [false ] translate from source language to english
-di, --diarize [false ] stereo audio diarization
-tdrz, --tinydiarize [false ] enable tinydiarize (requires a tdrz model)
-nf, --no-fallback [false ] do not use temperature fallback while decoding
-otxt, --output-txt [false ] output result in a text file
-ovtt, --output-vtt [false ] output result in a vtt file
-osrt, --output-srt [false ] output result in a srt file
-olrc, --output-lrc [false ] output result in a lrc file
-owts, --output-words [false ] output script for generating karaoke video
-fp, --font-path [/System/Library/Fonts/Supplemental/Courier New Bold.ttf] path to a monospace font for karaoke video
-ocsv, --output-csv [false ] output result in a CSV file
-oj, --output-json [false ] output result in a JSON file
-ojf, --output-json-full [false ] include more information in the JSON file
-of FNAME, --output-file FNAME [ ] output file path (without file extension)
-ps, --print-special [false ] print special tokens
-pc, --print-colors [false ] print colors
-pp, --print-progress [false ] print progress
-nt, --no-timestamps [false ] do not print timestamps
-l LANG, --language LANG [en ] spoken language ('auto' for auto-detect)
-dl, --detect-language [false ] exit after automatically detecting language
--prompt PROMPT [ ] initial prompt
-m FNAME, --model FNAME [models/ggml-base.en.bin] model path
-f FNAME, --file FNAME [ ] input WAV file path
-oved D, --ov-e-device DNAME [CPU ] the OpenVINO device used for encode inference
-ls, --log-score [false ] log best decoder scores of tokens
-ng, --no-gpu [false ] disable GPU
sh ./models/download-ggml-model.sh base.en
Downloading ggml model base.en ...
ggml-base.en.bin 100%[========================>] 141.11M 6.34MB/s in 24s
Done! Model 'base.en' saved in 'models/ggml-base.en.bin'
You can now use it like this:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
===============================================
Running base.en on all samples in ./samples ...
===============================================
----------------------------------------------
[+] Running base.en on samples/jfk.wav ... (run 'ffplay samples/jfk.wav' to listen)
----------------------------------------------
whisper_init_from_file: loading model from 'models/ggml-base.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 512
whisper_model_load: n_audio_head = 8
whisper_model_load: n_audio_layer = 6
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 512
whisper_model_load: n_text_head = 8
whisper_model_load: n_text_layer = 6
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 2
whisper_model_load: mem required = 215.00 MB (+ 6.00 MB per decoder)
whisper_model_load: kv self size = 5.25 MB
whisper_model_load: kv cross size = 17.58 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 140.60 MB
whisper_model_load: model size = 140.54 MB
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:11.000] And so my fellow Americans, ask not what your country can do for you, ask what you can do for your country.
whisper_print_timings: fallbacks = 0 p / 0 h
whisper_print_timings: load time = 113.81 ms
whisper_print_timings: mel time = 15.40 ms
whisper_print_timings: sample time = 11.58 ms / 27 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 266.60 ms / 1 runs ( 266.60 ms per run)
whisper_print_timings: decode time = 66.11 ms / 27 runs ( 2.45 ms per run)
whisper_print_timings: total time = 476.31 ms
Команда загружает модель base.en , преобразованную в пользовательский формат ggml , и запускает вывод на всех образцах .wav в samples папок.
Для получения подробных инструкций по использованию, запустите: ./main -h
Обратите внимание, что основной пример в настоящее время работает только с 16-битными файлами WAV, поэтому обязательно преобразуйте свой ввод перед запуском инструмента. Например, вы можете использовать ffmpeg , как это:
ffmpeg -i input.mp3 -ar 16000 -ac 1 -c:a pcm_s16le output.wavЕсли вы хотите получить дополнительные образцы аудио, просто запустите:
make -j samples
Это загрузит еще несколько аудиофайлов из Википедии и преобразует их в 16-битный формат WAV через ffmpeg .
Вы можете скачать и запустить другие модели следующим образом:
make -j tiny.en
make -j tiny
make -j base.en
make -j base
make -j small.en
make -j small
make -j medium.en
make -j medium
make -j large-v1
make -j large-v2
make -j large-v3
make -j large-v3-turbo
| Модель | Диск | Мем |
|---|---|---|
| крошечный | 75 миб | ~ 273 МБ |
| база | 142 миб | ~ 388 МБ |
| маленький | 466 миб | ~ 852 МБ |
| середина | 1,5 Гиб | ~ 2,1 ГБ |
| большой | 2.9 Gib | ~ 3,9 ГБ |
whisper.cpp поддерживает целочисленное квантование моделей Whisper ggml . Квантованные модели требуют меньше памяти и дискового пространства, и в зависимости от аппаратного обеспечения можно обработать более эффективно.
Вот шаги для создания и использования квантовой модели:
# quantize a model with Q5_0 method
make -j quantize
./quantize models/ggml-base.en.bin models/ggml-base.en-q5_0.bin q5_0
# run the examples as usual, specifying the quantized model file
./main -m models/ggml-base.en-q5_0.bin ./samples/gb0.wav На Apple Silicon Devices вывод Encoder может быть выполнен на нейронном двигателе Apple (ANE) через Core ML. Это может привести к значительному ускорению-более чем на x3 быстрее по сравнению с выполнением только CPU. Вот инструкции по созданию модели Core ML и использования ее с whisper.cpp :
Установите зависимости от питона, необходимые для создания модели Core ML:
pip install ane_transformers
pip install openai-whisper
pip install coremltoolscoremltools работает правильно, подтвердите, что XCode установлен, и выполнить xcode-select --install для установки инструментов командной строки.conda create -n py310-whisper python=3.10 -yconda activate py310-whisper Создайте модель Core ML. Например, чтобы генерировать модель base.en , используйте:
./models/generate-coreml-model.sh base.en Это генерирует models/ggml-base.en-encoder.mlmodelc
Стройте whisper.cpp с поддержкой Core ML:
# using Makefile
make clean
WHISPER_COREML=1 make -j
# using CMake
cmake -B build -DWHISPER_COREML=1
cmake --build build -j --config ReleaseЗапустите примеры как обычно. Например:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_init_state: loading Core ML model from 'models/ggml-base.en-encoder.mlmodelc'
whisper_init_state: first run on a device may take a while ...
whisper_init_state: Core ML model loaded
system_info: n_threads = 4 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 | COREML = 1 |
...
Первый запуск на устройстве является медленным, так как служба ANE компилирует модель Core ML в какой-то специфический для устройства формат. Следующие пробежки быстрее.
Для получения дополнительной информации о реализации Core ML, пожалуйста, обратитесь к PR #566.
На платформах, которые поддерживают OpenVino, вывод Encoder может быть выполнен на устройствах, поддерживаемых OpenVino, включая процессоры x86 и графические процессоры Intel (интегрированные и дискретные).
Это может привести к значительному ускорению производительности энкодера. Вот инструкции по созданию модели OpenVino и использованию ее с whisper.cpp :
Во -первых, настройка Python Virtual Env. и установить зависимости от питона. Python 3.10 рекомендуется.
Windows:
cd models
python - m venv openvino_conv_env
openvino_conv_envScriptsactivate
python - m pip install -- upgrade pip
pip install - r requirements - openvino.txtLinux и MacOS:
cd models
python3 -m venv openvino_conv_env
source openvino_conv_env/bin/activate
python -m pip install --upgrade pip
pip install -r requirements-openvino.txt Создайте модель энкодера OpenVino. Например, чтобы генерировать модель base.en , используйте:
python convert-whisper-to-openvino.py --model base.en
Это создаст GGML-base.en-encoder-openvino.xml/.bin IR-модели. Рекомендуется перенести их в ту же папку, что и модели ggml , как это место по умолчанию, которое расширение OpenVino будет искать во время выполнения.
Стройте whisper.cpp с поддержкой OpenVino:
Скачать пакет OpenVino со страницы релиза. Рекомендуемая версия для использования - 2023.0.0.
После загрузки и извлечения пакета в вашу систему разработки настраивайте необходимую среду путем поиска сценария Setupvars. Например:
Linux:
source /path/to/l_openvino_toolkit_ubuntu22_2023.0.0.10926.b4452d56304_x86_64/setupvars.shWindows (CMD):
C:PathTow_openvino_toolkit_windows_2023. 0.0 . 10926. b4452d56304_x86_64 setupvars.batА затем создайте проект с помощью CMAKE:
cmake -B build -DWHISPER_OPENVINO=1
cmake --build build -j --config ReleaseЗапустите примеры как обычно. Например:
$ ./main -m models/ggml-base.en.bin -f samples/jfk.wav
...
whisper_ctx_init_openvino_encoder: loading OpenVINO model from 'models/ggml-base.en-encoder-openvino.xml'
whisper_ctx_init_openvino_encoder: first run on a device may take a while ...
whisper_openvino_init: path_model = models/ggml-base.en-encoder-openvino.xml, device = GPU, cache_dir = models/ggml-base.en-encoder-openvino-cache
whisper_ctx_init_openvino_encoder: OpenVINO model loaded
system_info: n_threads = 4 / 8 | AVX = 1 | AVX2 = 1 | AVX512 = 0 | FMA = 1 | NEON = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 0 | SSE3 = 1 | VSX = 0 | COREML = 0 | OPENVINO = 1 |
...
Первый раз, когда запуск на устройстве OpenVino медленно, так как Framework OpenVino составит модель IR (промежуточное представление) с специфическим для устройства «Blob». Эта специфическая для устройства Blob будет кэширован для следующего запуска.
Для получения дополнительной информации о реализации Core ML, пожалуйста, обратитесь к PR #1037.
С помощью карт NVIDIA обработка моделей эффективно выполняется на графическом процессоре через CUBLAS и пользовательские ядра CUDA. Во-первых, убедитесь, что вы установили cuda : https://developer.nvidia.com/cuda-woundloads
Теперь постройте whisper.cpp с поддержкой CUDA:
make clean
GGML_CUDA=1 make -j
Решение по междавторосту, которое позволяет вам ускорить рабочую нагрузку на графическом процессоре. Во -первых, убедитесь, что ваш драйвер для видеокарты обеспечивает поддержку Vulkan API.
Теперь постройте whisper.cpp с поддержкой Vulkan:
make clean
make GGML_VULKAN=1 -j
Обработка энкодера может быть ускорена на процессоре через OpenBlas. Во -первых, убедитесь, что вы установили openblas : https://www.openblas.net/
Теперь постройте whisper.cpp с поддержкой OpenBlas:
make clean
GGML_OPENBLAS=1 make -j
Обработка энкодера может быть ускорена на процессоре через BLAS -совместимый интерфейс библиотеки математического ядра Intel. Во-первых, убедитесь, что вы установили пакеты Intel Mkl Runtime and Development: https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-uthourload.html
Теперь постройте whisper.cpp с поддержкой Intel Mkl Blas:
source /opt/intel/oneapi/setvars.sh
mkdir build
cd build
cmake -DWHISPER_MKL=ON ..
WHISPER_MKL=1 make -j
ASCEND NPU обеспечивает ускорение вывода через ядра CANN и AI.
Во -первых, проверьте, поддерживается ли ваше устройство ASCEND NPU:
Проверенные устройства
| Воспроизведение NPU | Статус |
|---|---|
| Атлас 300T A2 | Поддерживать |
Затем убедитесь, что вы установили CANN toolkit . Рекомендуется последняя версия CANN.
Теперь построите whisper.cpp с поддержкой CANN:
mkdir build
cd build
cmake .. -D GGML_CANN=on
make -j
Например, запустите примеры вывода, например:
./build/bin/main -f samples/jfk.wav -m models/ggml-base.en.bin -t 8
Примечания:
Verified devices . У нас есть два изображения Docker, доступные для этого проекта:
ghcr.io/ggerganov/whisper.cpp:main : это изображение включает в себя основной исполняемый файл, а также curl и ffmpeg . (Платформы: linux/amd64 , linux/arm64 )ghcr.io/ggerganov/whisper.cpp:main-cuda : так же, как main , но составлена с поддержкой CUDA. (Платформы: linux/amd64 ) # download model and persist it in a local folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./models/download-ggml-model.sh base /models "
# transcribe an audio file
docker run -it --rm
-v path/to/models:/models
-v path/to/audios:/audios
whisper.cpp:main " ./main -m /models/ggml-base.bin -f /audios/jfk.wav "
# transcribe an audio file in samples folder
docker run -it --rm
-v path/to/models:/models
whisper.cpp:main " ./main -m /models/ggml-base.bin -f ./samples/jfk.wav " Вы можете установить предварительно построенные двоичные файлы для Whisper.cpp или создать его из источника с помощью Conan. Используйте следующую команду:
conan install --requires="whisper-cpp/[*]" --build=missing
Для получения подробных инструкций о том, как использовать Conan, пожалуйста, обратитесь к документации CONAN.
Вот еще один пример транскрибирования речи 3:24 мин примерно за полминуты на MacBook M1 Pro, используя модель medium.en :
$ ./main -m models/ggml-medium.en.bin -f samples/gb1.wav -t 8
whisper_init_from_file: loading model from 'models/ggml-medium.en.bin'
whisper_model_load: loading model
whisper_model_load: n_vocab = 51864
whisper_model_load: n_audio_ctx = 1500
whisper_model_load: n_audio_state = 1024
whisper_model_load: n_audio_head = 16
whisper_model_load: n_audio_layer = 24
whisper_model_load: n_text_ctx = 448
whisper_model_load: n_text_state = 1024
whisper_model_load: n_text_head = 16
whisper_model_load: n_text_layer = 24
whisper_model_load: n_mels = 80
whisper_model_load: f16 = 1
whisper_model_load: type = 4
whisper_model_load: mem required = 1720.00 MB (+ 43.00 MB per decoder)
whisper_model_load: kv self size = 42.00 MB
whisper_model_load: kv cross size = 140.62 MB
whisper_model_load: adding 1607 extra tokens
whisper_model_load: model ctx = 1462.35 MB
whisper_model_load: model size = 1462.12 MB
system_info: n_threads = 8 / 10 | AVX = 0 | AVX2 = 0 | AVX512 = 0 | FMA = 0 | NEON = 1 | ARM_FMA = 1 | F16C = 0 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 0 | VSX = 0 |
main: processing 'samples/gb1.wav' (3179750 samples, 198.7 sec), 8 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:08.000] My fellow Americans, this day has brought terrible news and great sadness to our country.
[00:00:08.000 --> 00:00:17.000] At nine o'clock this morning, Mission Control in Houston lost contact with our Space Shuttle Columbia.
[00:00:17.000 --> 00:00:23.000] A short time later, debris was seen falling from the skies above Texas.
[00:00:23.000 --> 00:00:29.000] The Columbia's lost. There are no survivors.
[00:00:29.000 --> 00:00:32.000] On board was a crew of seven.
[00:00:32.000 --> 00:00:39.000] Colonel Rick Husband, Lieutenant Colonel Michael Anderson, Commander Laurel Clark,
[00:00:39.000 --> 00:00:48.000] Captain David Brown, Commander William McCool, Dr. Kultna Shavla, and Ilan Ramon,
[00:00:48.000 --> 00:00:52.000] a colonel in the Israeli Air Force.
[00:00:52.000 --> 00:00:58.000] These men and women assumed great risk in the service to all humanity.
[00:00:58.000 --> 00:01:03.000] In an age when space flight has come to seem almost routine,
[00:01:03.000 --> 00:01:07.000] it is easy to overlook the dangers of travel by rocket
[00:01:07.000 --> 00:01:12.000] and the difficulties of navigating the fierce outer atmosphere of the Earth.
[00:01:12.000 --> 00:01:18.000] These astronauts knew the dangers, and they faced them willingly,
[00:01:18.000 --> 00:01:23.000] knowing they had a high and noble purpose in life.
[00:01:23.000 --> 00:01:31.000] Because of their courage and daring and idealism, we will miss them all the more.
[00:01:31.000 --> 00:01:36.000] All Americans today are thinking as well of the families of these men and women
[00:01:36.000 --> 00:01:40.000] who have been given this sudden shock and grief.
[00:01:40.000 --> 00:01:45.000] You're not alone. Our entire nation grieves with you,
[00:01:45.000 --> 00:01:52.000] and those you love will always have the respect and gratitude of this country.
[00:01:52.000 --> 00:01:56.000] The cause in which they died will continue.
[00:01:56.000 --> 00:02:04.000] Mankind is led into the darkness beyond our world by the inspiration of discovery
[00:02:04.000 --> 00:02:11.000] and the longing to understand. Our journey into space will go on.
[00:02:11.000 --> 00:02:16.000] In the skies today, we saw destruction and tragedy.
[00:02:16.000 --> 00:02:22.000] Yet farther than we can see, there is comfort and hope.
[00:02:22.000 --> 00:02:29.000] In the words of the prophet Isaiah, "Lift your eyes and look to the heavens
[00:02:29.000 --> 00:02:35.000] who created all these. He who brings out the starry hosts one by one
[00:02:35.000 --> 00:02:39.000] and calls them each by name."
[00:02:39.000 --> 00:02:46.000] Because of His great power and mighty strength, not one of them is missing.
[00:02:46.000 --> 00:02:55.000] The same Creator who names the stars also knows the names of the seven souls we mourn today.
[00:02:55.000 --> 00:03:01.000] The crew of the shuttle Columbia did not return safely to earth,
[00:03:01.000 --> 00:03:05.000] yet we can pray that all are safely home.
[00:03:05.000 --> 00:03:13.000] May God bless the grieving families, and may God continue to bless America.
[00:03:13.000 --> 00:03:19.000] [Silence]
whisper_print_timings: fallbacks = 1 p / 0 h
whisper_print_timings: load time = 569.03 ms
whisper_print_timings: mel time = 146.85 ms
whisper_print_timings: sample time = 238.66 ms / 553 runs ( 0.43 ms per run)
whisper_print_timings: encode time = 18665.10 ms / 9 runs ( 2073.90 ms per run)
whisper_print_timings: decode time = 13090.93 ms / 549 runs ( 23.85 ms per run)
whisper_print_timings: total time = 32733.52 ms
Это наивный пример выполнения вывода в реальном времени по аудио из вашего микрофона. Инструмент потока выбирает аудио каждые полсекунды и непрерывно запускает транскрипцию. Больше информации доступна в выпуске № 10.
make stream -j
./stream -m ./models/ggml-base.en.bin -t 8 --step 500 --length 5000 Добавление аргумента --print-colors будет печатать транскрибированный текст, используя экспериментальную стратегию цветового кодирования, чтобы выделить слова с высокой или низкой уверенностью:
./main -m models/ggml-base.en.bin -f samples/gb0.wav --print-colors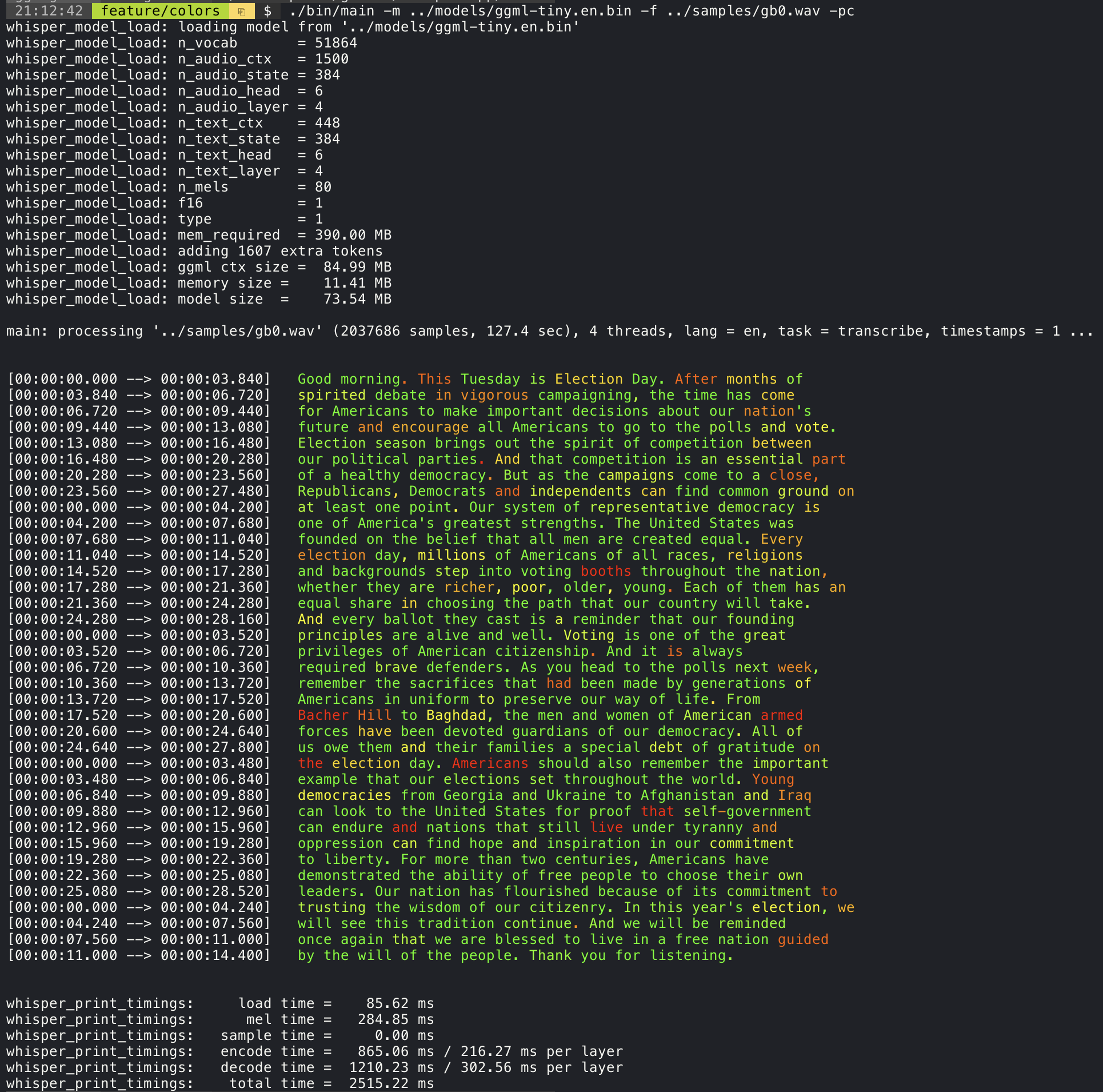
Например, чтобы ограничить длину линии максимум 16 символов, просто добавьте -ml 16 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 16
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.850] And so my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:04.140] Americans, ask
[00:00:04.140 --> 00:00:05.660] not what your
[00:00:05.660 --> 00:00:06.840] country can do
[00:00:06.840 --> 00:00:08.430] for you, ask
[00:00:08.430 --> 00:00:09.440] what you can do
[00:00:09.440 --> 00:00:10.020] for your
[00:00:10.020 --> 00:00:11.000] country.
Аргумент --max-len может использоваться для получения временных метров уровня слов. Просто используйте -ml 1 :
$ ./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -ml 1
whisper_model_load: loading model from './models/ggml-base.en.bin'
...
system_info: n_threads = 4 / 10 | AVX2 = 0 | AVX512 = 0 | NEON = 1 | FP16_VA = 1 | WASM_SIMD = 0 | BLAS = 1 |
main: processing './samples/jfk.wav' (176000 samples, 11.0 sec), 4 threads, 1 processors, lang = en, task = transcribe, timestamps = 1 ...
[00:00:00.000 --> 00:00:00.320]
[00:00:00.320 --> 00:00:00.370] And
[00:00:00.370 --> 00:00:00.690] so
[00:00:00.690 --> 00:00:00.850] my
[00:00:00.850 --> 00:00:01.590] fellow
[00:00:01.590 --> 00:00:02.850] Americans
[00:00:02.850 --> 00:00:03.300] ,
[00:00:03.300 --> 00:00:04.140] ask
[00:00:04.140 --> 00:00:04.990] not
[00:00:04.990 --> 00:00:05.410] what
[00:00:05.410 --> 00:00:05.660] your
[00:00:05.660 --> 00:00:06.260] country
[00:00:06.260 --> 00:00:06.600] can
[00:00:06.600 --> 00:00:06.840] do
[00:00:06.840 --> 00:00:07.010] for
[00:00:07.010 --> 00:00:08.170] you
[00:00:08.170 --> 00:00:08.190] ,
[00:00:08.190 --> 00:00:08.430] ask
[00:00:08.430 --> 00:00:08.910] what
[00:00:08.910 --> 00:00:09.040] you
[00:00:09.040 --> 00:00:09.320] can
[00:00:09.320 --> 00:00:09.440] do
[00:00:09.440 --> 00:00:09.760] for
[00:00:09.760 --> 00:00:10.020] your
[00:00:10.020 --> 00:00:10.510] country
[00:00:10.510 --> 00:00:11.000] .
Более подробная информация об этом подходе доступна здесь: #1058
Пример использования:
# download a tinydiarize compatible model
. / models / download - ggml - model . sh small . en - tdrz
# run as usual, adding the "-tdrz" command-line argument
. / main - f . / samples / a13 . wav - m . / models / ggml - small . en - tdrz . bin - tdrz
...
main : processing './samples/a13.wav' ( 480000 samples , 30.0 sec ), 4 threads , 1 processors , lang = en , task = transcribe , tdrz = 1 , timestamps = 1 ...
...
[ 00 : 00 : 00.000 - - > 00 : 00 : 03.800 ] Okay Houston , we ' ve had a problem here . [ SPEAKER_TURN ]
[ 00 : 00 : 03.800 - - > 00 : 00 : 06.200 ] This is Houston . Say again please . [ SPEAKER_TURN ]
[ 00 : 00 : 06.200 - - > 00 : 00 : 08.260 ] Uh Houston we ' ve had a problem .
[ 00 : 00 : 08.260 - - > 00 : 00 : 11.320 ] We ' ve had a main beam up on a volt . [ SPEAKER_TURN ]
[ 00 : 00 : 11.320 - - > 00 : 00 : 13.820 ] Roger main beam interval . [ SPEAKER_TURN ]
[ 00 : 00 : 13.820 - - > 00 : 00 : 15.100 ] Uh uh [ SPEAKER_TURN ]
[ 00 : 00 : 15.100 - - > 00 : 00 : 18.020 ] So okay stand , by thirteen we ' re looking at it . [ SPEAKER_TURN ]
[ 00 : 00 : 18.020 - - > 00 : 00 : 25.740 ] Okay uh right now uh Houston the uh voltage is uh is looking good um .
[ 00 : 00 : 27.620 - - > 00 : 00 : 29.940 ] And we had a a pretty large bank or so . Основной пример обеспечивает поддержку вывода фильмов в стиле караоке, где выделено в настоящее время произнесенное слово. Используйте аргумент -wts и запустите сгенерированный сценарий Bash. Это требует установки ffmpeg .
Вот несколько «типичных» примеров:
./main -m ./models/ggml-base.en.bin -f ./samples/jfk.wav -owts
source ./samples/jfk.wav.wts
ffplay ./samples/jfk.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/mm0.wav -owts
source ./samples/mm0.wav.wts
ffplay ./samples/mm0.wav.mp4./main -m ./models/ggml-base.en.bin -f ./samples/gb0.wav -owts
source ./samples/gb0.wav.wts
ffplay ./samples/gb0.wav.mp4Используйте скрипт Scripts/Bench-WTS.SH, чтобы сгенерировать видео в следующем формате:
./scripts/bench-wts.sh samples/jfk.wav
ffplay ./samples/jfk.wav.all.mp4Чтобы иметь объективное сравнение производительности вывода в разных конфигурациях системы, используйте инструмент Bench. Инструмент просто запускает часть модели энкодера и печатает, сколько времени потребовалось, чтобы выполнить ее. Результаты суммированы в следующей проблеме GitHub:
Контрольные результаты
Кроме того, сценарий для запуска Shepper.cpp с различными моделями и аудиофайлами предоставляется bend.py.
Вы можете запустить его со следующей командой, по умолчанию он будет работать против любой стандартной модели в папке моделей.
python3 scripts/bench.py -f samples/jfk.wav -t 2,4,8 -p 1,2Он написан на Python с намерением быть простым в изменении и расширении для вашего варианта использования.
Он выводит файл CSV с результатами сравнительного анализа.
ggmlОригинальные модели преобразуются в пользовательский двоичный формат. Это позволяет упаковать все необходимое в один файл:
Вы можете скачать конвертированные модели, используя сценарий Models/Download-Ggml-Model.sh или вручную отсюда:
Для получения более подробной информации см. Модели сценариев преобразования/Convert-pt-to-ggml.py или модели/readme.md.
Существуют различные примеры использования библиотеки для различных проектов в папке примеров. Некоторые из примеров даже переносятся для запуска в браузере с использованием webassembly. Проверьте их!
| Пример | Веб - | Описание |
|---|---|---|
| основной | Whisper.wasm | Инструмент для перевода и транскрибирования звука с использованием шепота |
| лавка | скамейка | Считайте производительность Whisper на вашей машине |
| транслировать | Stream.wasm | Транскрипция в реальном времени необработанного захвата микрофона |
| командование | command.wasm | Основной пример голосового помощника для получения голосовых команд от микрофона |
| wchess | wchess.wasm | Контролируемые голосовыми шахматами |
| разговаривать | Talk.wasm | Поговорите с ботом GPT-2 |
| Talk-Llama | Поговорите с ботом ламы | |
| Whisper.objc | Мобильное приложение для iOS с использованием shepper.cpp | |
| Whisper.swiftui | Swiftui iOS / MacOS Application с использованием shepper.cpp | |
| Whisper.android | Android Mobile Application с использованием shepper.cpp | |
| Whisper.nvim | Плагин речи к тексту для Neovim | |
| Generate-Karaoke.sh | Вспомогательный сценарий, чтобы легко генерировать видео караоке с необработанным захватом звука | |
| Livestream.sh | Транскрипция звука прямой трансляции | |
| yt-wsp.sh | Скачать + транскрибировать и/или перевести любой VOD (оригинал) | |
| сервер | Сервер транскрипции HTTP с API, подобным OAI |
Если у вас есть какие -либо отзывы об этом проекте, не стесняйтесь использовать раздел дискуссий и открывать новую тему. Вы можете использовать категорию Show and Dely, чтобы поделиться своими собственными проектами, которые используют whisper.cpp . Если у вас есть вопрос, обязательно проверьте обсуждение часто задаваемых вопросов (#126).


