Разработайте API REST для выполнения машинного перевода, используя модель SEQ2SEQ. Развертывание модели выполняется с использованием платформы Google.
Проект создан с помощью:
Данные для этого проекта доступны в виде текстового файла на источнике данных, где каждая строка имеет предложение в каннаде и перевод его на английском языке с космическим разделителем. Мы вручную проверены случайным образом, чтобы убедиться, что каждый пример имел смысл.
Сначала мы строим модель декодера энкодера с механизмом внимания с использованием GRU RNN. Обучение было проведено с помощью сценария Python, доступного здесь
Создайте приложение Flask, которое можно получить с локальной машины по адресу http://127.0.0.1:5000/predict.
Мы будем использовать сценарий для обучения модели. После обучения модели мы сохраним веса модели в файле .pt и храним в Google Cloud Storage. Мы также строим словарь словарного запаса, индексируя каждое слово и мариновано их. Эти маринованные файлы также хранятся в файле хранилища. Вы можете получить доступ к ним здесь, как только эти файлы будут на месте, развертывание может быть сделано после шагов ниже
Мы загрузим файлы на ведро для хранения. Чтобы создать ведро, используя следующие параметры, как указано в следующих спецификациях
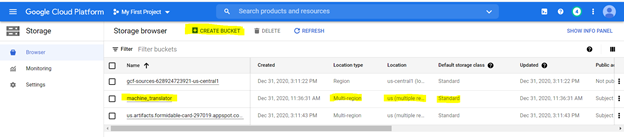
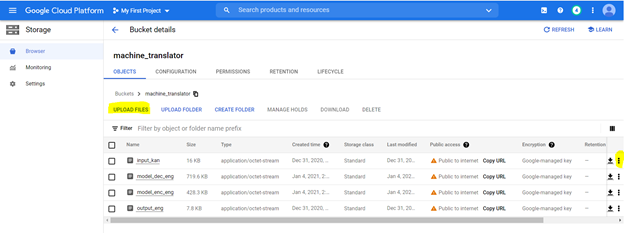
Для создания облачной функции, просмотрите ее на платформе GCP и используйте параметры, выделенные ниже, чтобы создать функцию,
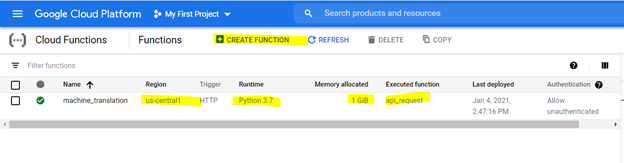
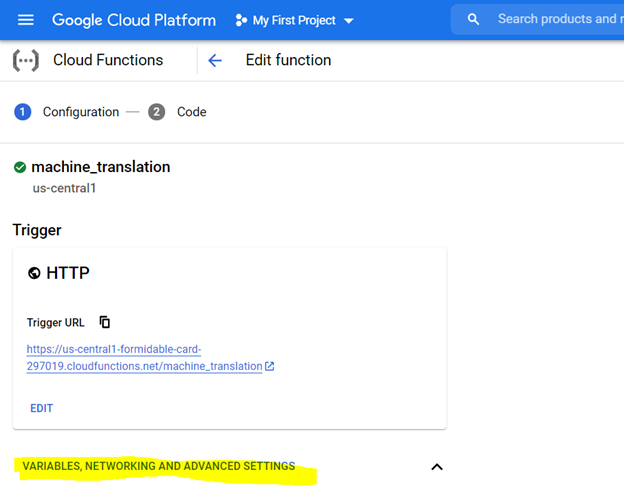
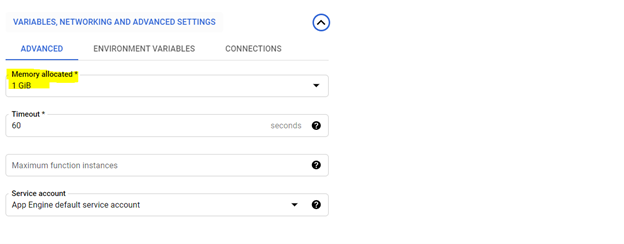
*Рекомендуется распределение 1 памяти GIB. После установки нажмите «Далее» и разверните код на консоли функции Cloud.
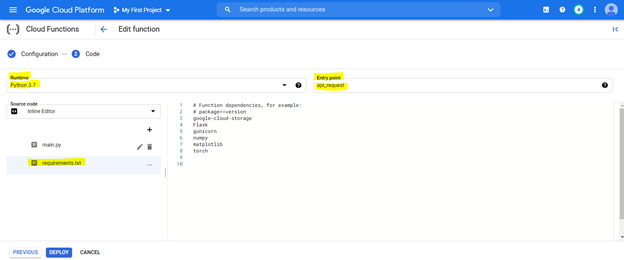
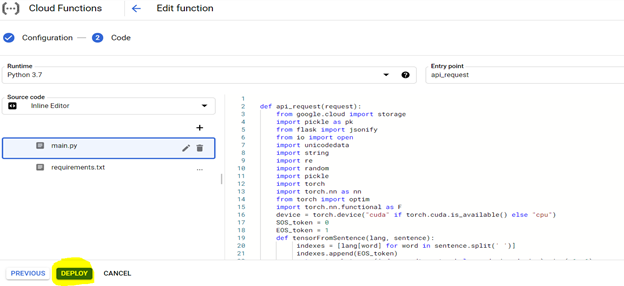
Чтобы развернуть код, сначала настройте консоль с выделенными ниже настройками и подготовьте среду, используя файл требований (это эквивалентно PIP {Library}), как описано ниже,

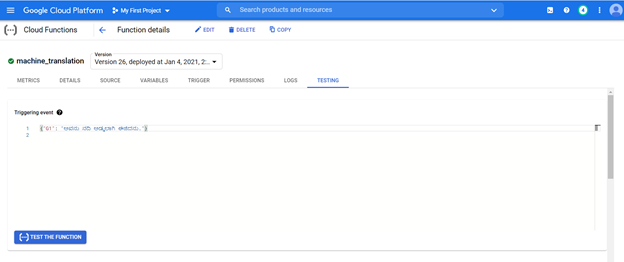

Развернутая модель можно получить из URL -адреса из любой системы для перевода предложений каннада на английский.


