
Официальная внедрение GFT, модели междоменного фонда на графиках. Логотип генерируется Dall · E 3.
Автор Zehong Wang, Zheyuan Zhang, Nitesh V Chawla, Chuxu Zhang и Yanfang Ye.
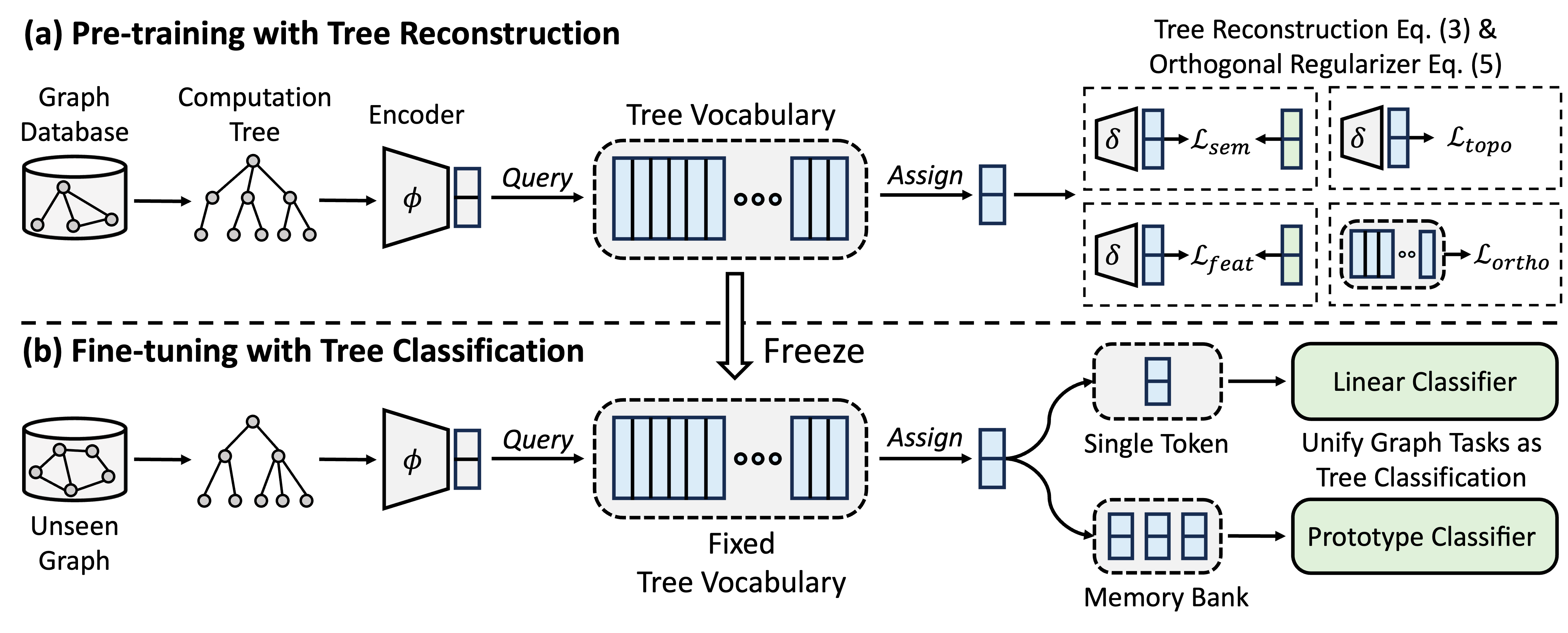
GFT представляет собой модель поперечного домена и графического фонда, которая рассматривает деревья вычислений как передаваемые шаблоны для получения переносимых словарного запаса дерева. Кроме того, GFT обеспечивает унифицированную структуру для соответствия задачам, связанных с графиком, позволяя одну графическую модель, например, GNN для совместной обработки задач уровня узлов, уровня края и уровня графика.
Во время предварительного обучения модель кодирует общие знания из базы данных графиков в словарный запас деревьев с помощью задачи реконструкции деревьев. В тонкой настройке, условный словарный запас, который применяется для объединения задач, связанных с графом в качестве задач классификации деревьев, адаптируя приобретенные общие знания к конкретным задачам.
Вы можете использовать Conda для установки среды. Пожалуйста, запустите следующий сценарий. Мы запускаем все эксперименты на одном графическом процессоре A40 48G, но графический процессор с памятью 24G достаточно для обработки всех наборов данных с мини-партией.
conda env create -f environment.yml
conda activate GFT
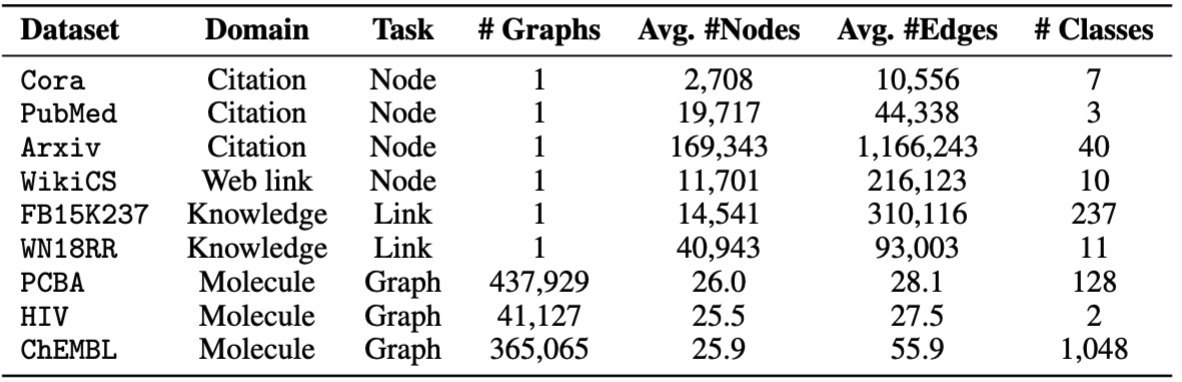
Мы используем наборы данных, предоставленные OFA. Вы можете запустить pretrain.py для автоматической загрузки наборов данных, которые будут загружены в папку /data по умолчанию. Трубопровод автоматически предварительно обрабатывает наборы данных путем преобразования текстовых описаний в текстовые встраивания.
В качестве альтернативы, вы можете загрузить наши предварительные наборы данных и распад в папке /data .
Код GFT представлен в папке /GFT . Структура заключается в следующем.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Вы можете запустить pretrain.py для предварительной подготовки на широком спектре графиков и finetune.py для адаптации к определенным нисходящим задачам с основным созданием или нескольких выстрелом.
Чтобы воспроизвести результаты, мы предоставляем подробные гиперпараметры как для предварительной подготовки, так и для создания, поддерживаемого в config/pretrain.yaml . YAML и config/finetune.yaml , соответственно. Чтобы использовать гиперпараметры по умолчанию, мы предоставляем команду --use_params как для предварительного, так и для Finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Для Manetuning мы предоставляем восемь наборов данных, включая cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv и chempcba .
В качестве альтернативы, вы можете запустить сценарий, чтобы воспроизвести эксперименты.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
ПРИМЕЧАНИЕ. Предварительная модель будет храниться в ckpts/pretrain_model/ по умолчанию.
# The basic command for pretraining GFT
python GFT/pretrain.py
Когда вы запускаете pretrain.py , вы можете настроить наборы данных предварительного подготовки и гиперпараметры.
Вы можете использовать --pretrain_dataset (или --pt_data ), чтобы установить используемые наборы данных предварительных данных и соответствующие веса. Предварительно определенная конфигурация данных находится в config/pt_data.yaml , со следующими структурами.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
В вышеприведенном случае all - это имя настройки, то есть все наборы данных используются в предварительной подготовке. Для каждого набора данных есть пары клавиш, где ключ-это имя набора данных, а значение-вес отбора проб. Например, cora: 5 означает, что набор данных cora будет отображаться 5 раз в одну эпоху. Вы можете разработать свою собственную комбинацию наборов данных для предварительной подготовки GFT.
Вы можете настроить фазу предварительной подготовки, изменяя гиперпараметры энкодера, квантования вектора, модели.
--pretrain_dataset : Укажите набор данных предварительной подготовки. То же самое до вышеизложенного.--use_params : Используйте предварительно определенные гиперпараметры.--seed : Семя, используемые для предварительной подготовки.--hidden_dim : измерение в скрытом слое GNN.--num_layers : слои GNN.--activation : функция активации.--backbone : костяк GNN.--normalize : слой нормализации.--dropout : выброс слоя GNN.--code_dim : измерение каждого кода в словаре.--codebook_size : количество кодов в словаре.--codebook_head : количество голов кодовой книги. Если число больше 1, вы совместно будете использовать несколько словари.--codebook_decay : скорость распада кодов.--commit_weight : вес термина обязательства.--pretrain_epochs : количество эпох.--pretrain_lr : скорость обучения.--pretrain_weight_decay : вес L2 Regaritizer.--pretrain_batch_size : размер партии.--feat_p : скорость коррупции функции.--edge_p : скорость коррупции края/структура.--topo_recon_ratio : соотношение краев должно быть восстановлено.--feat_lambda : вес потери признаков.--topo_lambda : вес потери топологии.--topo_sem_lambda : вес потери топологии в функциях реконструкции.--sem_lambda : вес семантической потери.--sem_encoder_decay : скорость обновления импульса для семантического энкодера. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Вы можете установить --dataset для указания набора данных в нижнем потоке, а --use_params для использования предварительно определенных гиперпараметров для каждого набора данных. Другие гиперпараметры, которые вы можете указать, представлены следующим образом.
Для графиков с 1 предварительно определенным расщеплением вы можете установить --repeat провести несколько экспериментов.
--hidden_dim : измерение в скрытом слое GNN.--num_layers : слои GNN.--activation : функция активации.--backbone : костяк GNN.--normalize : слой нормализации.--dropout : выброс слоя GNN.--code_dim : измерение каждого кода в словаре.--codebook_size : количество кодов в словаре.--codebook_head : количество голов кодовой книги. Если число больше 1, вы совместно будете использовать несколько словари.--codebook_decay : скорость распада кодов.--commit_weight : вес термина обязательства.--finetune_epochs : количество эпох.--finetune_lr : скорость обучения.--early_stop : максимальная ранняя эпоха остановки.--batch_size : если установлено в 0, проведите полное обучение графическим графикам. --lambda_proto : Вес классификатора прототипа в области.
--lambda_act : Вес линейного классификатора в Manetuning.
--trade_off : компромисс между использованием прототипа Classier или использованием линейного классификатора по выводу.
Вы можете добавить --no_lin_clf или --no_proto_clf , чтобы избежать использования линейного классификатора или классификатора прототипа соответственно. Обратите внимание, что эти два термина являются конфликтом, так как вы должны использовать хотя бы один классификатор.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Вы можете установить --dataset для указания набора данных в нижнем потоке, а --use_params для использования предварительно определенных гиперпараметров для каждого набора данных. Другие гиперпараметры, которые вы можете указать, представлены следующим образом.
Гиперпараметры, посвященные для нескольких выстрелов
--n_train : количество учебных экземпляров на класс для создания модели. Обратите внимание, что маленький n_train достигает желаемой производительности --n_task : количество выбранных задач.--n_way : количество способов.--n_query : размер набора запросов на путь.--n_shot : размер поддержки набор для каждого пути.--hidden_dim : измерение в скрытом слое GNN.--num_layers : слои GNN.--activation : функция активации.--backbone : костяк GNN.--normalize : слой нормализации.--dropout : выброс слоя GNN.--code_dim : измерение каждого кода в словаре.--codebook_size : количество кодов в словаре.--codebook_head : количество голов кодовой книги. Если число больше 1, вы совместно будете использовать несколько словари.--codebook_decay : скорость распада кодов.--commit_weight : вес термина обязательства.--finetune_epochs : количество эпох.--finetune_lr : скорость обучения.--early_stop : максимальная ранняя эпоха остановки.--batch_size : если установлено в 0, проведите полное обучение графическим графикам. --lambda_proto : Вес классификатора прототипа в области.
--lambda_act : Вес линейного классификатора в Manetuning.
--trade_off : компромисс между использованием прототипа Classier или использованием линейного классификатора по выводу.
Вы можете добавить --no_lin_clf или --no_proto_clf , чтобы избежать использования линейного классификатора или классификатора прототипа соответственно. Обратите внимание, что эти два термина являются конфликтом, так как вы должны использовать хотя бы один классификатор.
Экспериментальные результаты могут варьироваться в зависимости от рандомизированной инициализации во время предварительной подготовки. Мы предоставляем экспериментальные результаты с использованием различных случайных семян (т.е. 1-5) в предварительной подготовке, чтобы показать потенциальное влияние случайной инициализации.
| Кора | PubMed | Wiki-CS | Arxiv | Wn18rr | FB15K237 | ВИЧ | PCBA | Средний | |
|---|---|---|---|---|---|---|---|---|---|
| Семя = 1 | 78,58 ± 0,90 | 77,55 ± 1,54 | 79,38 ± 0,57 | 72,24 ± 0,16 | 91,56 ± 0,33 | 89,67 ± 0,35 | 72,69 ± 1,93 | 78,24 ± 0,23 | 79,99 |
| Семя = 2 | 78,27 ± 1,26 | 76,41 ± 1,36 | 79,36 ± 0,62 | 72,13 ± 0,24 | 91,72 ± 0,19 | 89,66 ± 0,31 | 71,62 ± 2,45 | 78,20 ± 0,33 | 79,67 |
| Семя = 3 | 78,16 ± 1,62 | 76,28 ± 1,37 | 79,32 ± 0,65 | 72,13 ± 0,30 | 91,57 ± 0,44 | 89,78 ± 0,23 | 71,58 ± 2,28 | 78,12 ± 0,37 | 79,62 |
| Семя = 4 | 78,42 ± 1,37 | 75,76 ± 1,58 | 79,44 ± 0,62 | 72,36 ± 0,34 | 91,70 ± 0,24 | 89,73 ± 0,21 | 72,57 ± 2,46 | 78,34 ± 0,27 | 79,79 |
| Семя = 5 | 78,56 ± 1,62 | 76,49 ± 2,00 | 79,27 ± 0,55 | 72,18 ± 0,26 | 91,47 ± 0,39 | 89,80 ± 0,19 | 72,27 ± 0,93 | 78,31 ± 0,34 | 79,79 |
| Сообщается | 78,62 ± 1,21 | 77,19 ± 1,99 | 79,39 ± 0,42 | 71,93 ± 0,12 | 91,91 ± 0,34 | 89,72 ± 0,20 | 72,67 ± 1,38 | 77,90 ± 0,64 | 79,92 |
Чтобы лучше обеспечить воспроизводимость, мы предоставляем контрольные точки семян = 1 в этой ссылке. Мы выбираем это из -за его лучшей средней производительности. Вы можете разкапливаться загруженным файлом в пути ckpts/pretrain_model/ и установить --pt_seed 1 при использовании finetune.py , чтобы деликатно использовать наши предусмотренные контрольные точки.
Пожалуйста, свяжитесь с [email protected] или откройте проблему, если у вас есть вопросы.
Если вы обнаружите, что репо полезно для вашего исследования, пожалуйста, укажите оригинальную статью правильно.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Этот репозиторий основан на кодовой базе OFA, PYG, OGB и VQ. Спасибо за их обмен!


