vision_transformer
1.0.0
В этом репозитории мы выпускаем модели из бумаг
Модели были предварительно обучены наборе данных ImageNet и ImageNet-21K. Мы предоставляем код для точной настройки выпущенных моделей в JAX/лене.
Модели из этой кодовой базы были первоначально обучены на https://github.com/google-research/big_vision/, где вы можете найти более продвинутый код (например, обучение с несколькими хостами), а также некоторые из исходных тренировочных сценариев (например, конфигурации /vit_i21k.py для предварительного обучения Vit или configs/transfer.py для передачи модели).
Оглавление:
Ниже колабами работают как с графическими процессорами, так и с TPU (8 ядер, параллелизм данных).
Первый колаб демонстрирует код кода Vision Code of Vision Transformers и MLP -миксеры. Этот колаб позволяет вам редактировать файлы из репозитория непосредственно в пользовательском интерфейсе Colab и имеет аннотированные ячейки Colab, которые проводят вас через код шаг за шагом, и позволяет взаимодействовать с данными.
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax.ipynb
Второй колаб позволяет вам изучить> 50K Vision Transformer и гибридные контрольно -пропускные пункты, которые использовались для генерации данных третьей статьи «Как обучить свой вит? ...». Colab включает код для изучения и выбора контрольных точек, а также для вывода как с использованием кода JAX из этого репо, так и с использованием популярной библиотеки timm Pytorch, которая также может напрямую загружать эти контрольные точки. Обратите внимание, что несколько моделей также доступны непосредственно от TF-Hub: Sayakpaul/Collections/Vision_transformer (внешний вклад Саяка Пола).
Второй Colab также позволяет точно настроить контрольные точки на любом наборе данных TFDS и вашего собственного набора данных с примерами в отдельных файлах JPEG (опционально прямо с чтением с Google Drive).
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/vit_jax_augreg.ipynb
ПРИМЕЧАНИЕ . На данный момент (020.06.21) Google Colab поддерживает только один графический процессор (NVIDIA TESLA T4), а TPU (в настоящее время TPUV2-8) косвенно прикрепляются к Colab VM и передаются по медленной сети, которая приводит к красивой Плохая скорость тренировок. Обычно вы захотите настроить специальную машину, если у вас есть нетривиальное количество данных для точной настройки. Подробности см. В разделе «Запуск на облаке».
Убедитесь, что у вас есть Python>=3.10 установлен на вашем компьютере.
Установите зависимости JAX и Python, работая:
# If using GPU:
pip install -r vit_jax/requirements.txt
# If using TPU:
pip install -r vit_jax/requirements-tpu.txt
Для новых версий JAX следуйте инструкциям, представленным в соответствующем хранилище, связанном здесь. Обратите внимание, что инструкции по установке для процессора, графического процессора и TPU немного отличаются.
Установите FlaxFormer, следуйте инструкциям, представленным в соответствующем хранилище, связанном здесь.
Для получения более подробной информации см. В разделе, работающем на облаке ниже.
Вы можете запустить точную настройку загруженной модели в вашем наборе данных. Все модели имеют один и тот же интерфейс командной строки.
Например, для точной настройки Vit-b/16 (предварительно обученного на ImageNet21k) на Cifar10 (обратите внимание на то, как мы указываем b16,cifar10 в качестве аргументов для конфигурации, и как мы инструктируем код для доступа к моделям непосредственно из ведра GCS Вместо сначала загружать их в локальный каталог):
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/vit.py:b16,cifar10
--config.pretrained_dir= ' gs://vit_models/imagenet21k 'Чтобы точно настроить смеситель-B/16 (предварительно обученный на ImageNet21K) на CiFAR10:
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/mixer_base16_cifar10.py
--config.pretrained_dir= ' gs://mixer_models/imagenet21k ' «Как обучить свой вит? ...» добавлена бумага> 50 тыс. Контрольных точек, которые вы можете точно настроить с конфигурацией configs/augreg.py . Если вы указываете имя модели (значение config.name из configs/model.py ), то выбирается лучшая контрольная точка i21k с точностью проверки вверх по течению («Рекомендуемая» контрольная точка, см. Раздел 4.5 бумаги). Чтобы принять решение, какая модель вы хотите использовать, посмотрите на рисунок 3 в статье. Также можно выбрать другую контрольную точку (см. Colab vit_jax_augreg.ipynb ), а затем указать значение из колонки filename или adapt_filename , которое соответствует именам файлов без .npz из каталога gs://vit_models/augreg .
python -m vit_jax.main --workdir=/tmp/vit- $( date +%s )
--config= $( pwd ) /vit_jax/configs/augreg.py:R_Ti_16
--config.dataset=oxford_iiit_pet
--config.base_lr=0.01 В настоящее время код будет автоматически загружать наборы данных CIFAR-10 и CIFAR-100. Другие публичные или пользовательские наборы данных могут быть легко интегрированы, используя библиотеку наборов данных TensorFlow. Обратите внимание, что вам также нужно будет обновить vit_jax/input_pipeline.py чтобы указать некоторые параметры о любом добавленном наборе данных.
Обратите внимание, что наш код использует все доступные графические процессоры/TPU для точной настройки.
Чтобы увидеть подробный список всех доступных флагов, запустите python3 -m vit_jax.train --help .
Примечания по памяти:
--config.accum_steps=8 -Альтернативно, вы также можете уменьшить --config.batch=512 (и уменьшить --config.base_lr соответственно).--config.shuffle_buffer=50000 . Алексей Досовицкий*†, Лукас Бейер*, Александр Колесников*, Дирк Вайсенборн*, Сяохуа Чжай*, Томас Унингтинер, Мостафа Дехгани, Матиас Миндерер, Георг Хейголд, Сильвейн Гелли, Джакоб Ускорет и Нейл Хулсби*.
(*) Равный технический вклад, (†) равные консультирование.
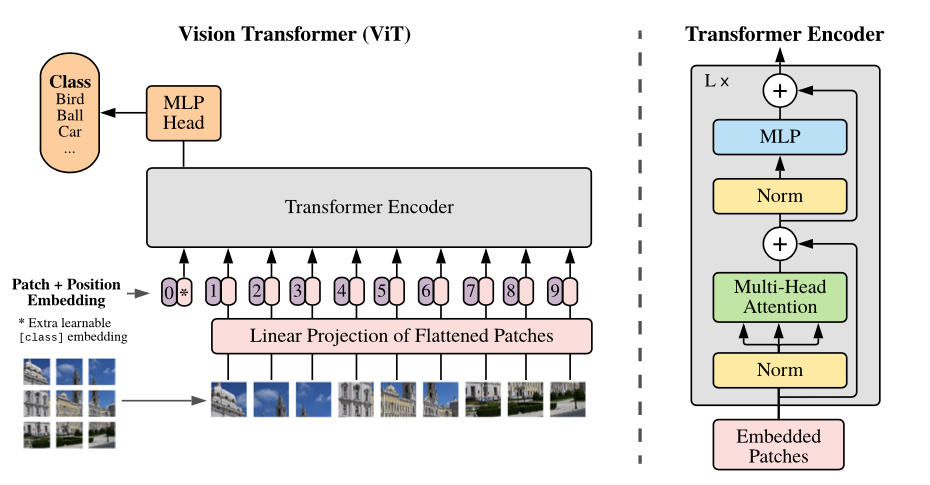
Обзор модели: мы разделили изображение на патчи с фиксированным размером, линейно внедряют каждый из них, добавляем встраиваемые положения и подаем полученную последовательность векторов стандартному энкодеру трансформатора. Чтобы выполнить классификацию, мы используем стандартный подход добавления дополнительного обучения «токен классификации» в последовательность.
Мы предоставляем различные модели Vit в различных ведрах GCS. Модели можно загрузить с помощью например:
wget https://storage.googleapis.com/vit_models/imagenet21k/ViT-B_16.npz
Имена файлов модели (без расширения .npz ) соответствуют config.model_name in vit_jax/configs/models.py
gs://vit_models/imagenet21k -модели, предварительно обученные ImageNet-21K.gs://vit_models/imagenet21k+imagenet2012 -модели, предварительно обученные ImageNet-21K и тонко настраивали на ImageNet.gs://vit_models/augreg -модели, предварительно обученные ImageNet-21K, применяя различные количества Augreg. Улучшенная производительность.gs://vit_models/sam - Модели, предварительно обученные на ImageNet с SAM.gs://vit_models/gsam - модели, предварительно обученные ImageNet с GSAM.Мы рекомендуем использовать следующие контрольно-пропускные пункты, обученные с аугитом, которые имеют лучшие метрики перед тренировкой:
| Модель | Предварительно обученная контрольная точка | Размер | Тонко настроенная контрольная точка | Разрешение | IMG/с | Точность ImageNet |
|---|---|---|---|---|---|---|
| L/16 | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0.npz | 1243 Mib | gs://vit_models/augreg/L_16-i21k-300ep-lr_0.001-aug_strong1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 50 | 85,59% |
| Б/16 | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0.npz | 391 миб | gs://vit_models/augreg/B_16-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 138 | 85,49% |
| S/16 | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0.npz | 115 миб | gs://vit_models/augreg/S_16-i21k-300ep-lr_0.001-aug_light1-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 300 | 83,73% |
| R50+L/32 | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1.npz | 1337 Mib | gs://vit_models/augreg/R50_L_32-i21k-300ep-lr_0.001-aug_medium1-wd_0.1-do_0.1-sd_0.1--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 327 | 85,99% |
| R26+S/32 | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 170 миб | gs://vit_models/augreg/R26_S_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 560 | 83,85% |
| Ti/16 | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 37 миб | gs://vit_models/augreg/Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 610 | 78,22% |
| Б/32 | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0.npz | 398 миб | gs://vit_models/augreg/B_32-i21k-300ep-lr_0.001-aug_light1-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 955 | 83,59% |
| S/32 | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0.npz | 118 миб | gs://vit_models/augreg/S_32-i21k-300ep-lr_0.001-aug_none-wd_0.1-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.01-res_384.npz | 384 | 2154 | 79,58% |
| R+ti/16 | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0.npz | 40 миб | gs://vit_models/augreg/R_Ti_16-i21k-300ep-lr_0.001-aug_none-wd_0.03-do_0.0-sd_0.0--imagenet2012-steps_20k-lr_0.03-res_384.npz | 384 | 2426 | 75,40% |
Результаты оригинальной бумаги Vit (https://arxiv.org/abs/2010.11929) были воспроизведены с использованием моделей из gs://vit_models/imagenet21k :
| модель | набор данных | отсечение = 0,0 | отсечение = 0,1 |
|---|---|---|---|
| R50+Vit-B_16 | cifar10 | 98,72%, 3,9 часа (A100), TB.DEV | 98,94%, 10,1H (V100), TB.DEV |
| R50+Vit-B_16 | CIFAR100 | 90,88%, 4,1H (A100), TB.DEV | 92,30%, 10,1H (V100), TB.DEV |
| R50+Vit-B_16 | ImageNet2012 | 83,72%, 9,9 часа (A100), TB.DEV | 85,08%, 24,2H (V100), TB.DEV |
| Vit-B_16 | cifar10 | 99,02%, 2,2 часа (A100), TB.DEV | 98,76%, 7,8H (V100), TB.DEV |
| Vit-B_16 | CIFAR100 | 92,06%, 2,2 часа (A100), TB.DEV | 91,92%, 7,8H (V100), TB.DEV |
| Vit-B_16 | ImageNet2012 | 84,53%, 6,5H (A100), TB.DEV | 84,12%, 19,3H (V100), TB.DEV |
| Vit-B_32 | cifar10 | 98,88%, 0,8H (A100), TB.DEV | 98,75%, 1,8 часа (v100), tb.dev |
| Vit-B_32 | CIFAR100 | 92,31%, 0,8H (A100), TB.DEV | 92,05%, 1,8 часа (v100), tb.dev |
| Vit-B_32 | ImageNet2012 | 81,66%, 3,3 часа (A100), TB.DEV | 81,31%, 4,9H (V100), TB.DEV |
| Vit-l_16 | cifar10 | 99,13%, 6,9 часа (a100), tb.dev | 99,14%, 24,7H (V100), TB.DEV |
| Vit-l_16 | CIFAR100 | 92,91%, 7,1H (A100), TB.DEV | 93,22%, 24,4H (V100), TB.DEV |
| Vit-l_16 | ImageNet2012 | 84,47%, 16,8H (A100), TB.DEV | 85,05%, 59,7H (V100), TB.DEV |
| Vit-l_32 | cifar10 | 99,06%, 1,9 часа (a100), tb.dev | 99,09%, 6,1H (V100), TB.DEV |
| Vit-l_32 | CIFAR100 | 93,29%, 1,9 часа (A100), TB.DEV | 93,34%, 6,2 часа (v100), tb.dev |
| Vit-l_32 | ImageNet2012 | 81,89%, 7,5H (A100), TB.DEV | 81,13%, 15,0H (V100), TB.DEV |
Мы также хотели бы подчеркнуть, что высококачественные результаты могут быть достигнуты с помощью более коротких учебных графиков и поощрять пользователей нашего кода играть с гиперпараметрами к точности компромисса и вычислительному бюджету. Некоторые примеры для наборов данных CIFAR-10/100 представлены в таблице ниже.
| вверх по течению | модель | набор данных | total_steps / warmup_steps | точность | Время на стене | связь |
|---|---|---|---|---|---|---|
| ImageNet21k | Vit-B_16 | cifar10 | 500 /50 | 98,59% | 17 м | tensorboard.dev |
| ImageNet21k | Vit-B_16 | cifar10 | 1000 /100 | 98,86% | 39 м | tensorboard.dev |
| ImageNet21k | Vit-B_16 | CIFAR100 | 500 /50 | 89,17% | 17 м | tensorboard.dev |
| ImageNet21k | Vit-B_16 | CIFAR100 | 1000 /100 | 91,15% | 39 м | tensorboard.dev |
Илью Толстихин*, Нил Хоулсби*, Александр Колесников*, Лукас Бейер*, Сяуа Чжай, Томас Унтертинер, Джессика Юнг, Андреас Штейнер, Даниэль Кизерс, Якоб Усзорит, Марио Люсич, Алексеей Доскицкий.
(*) Равный вклад.
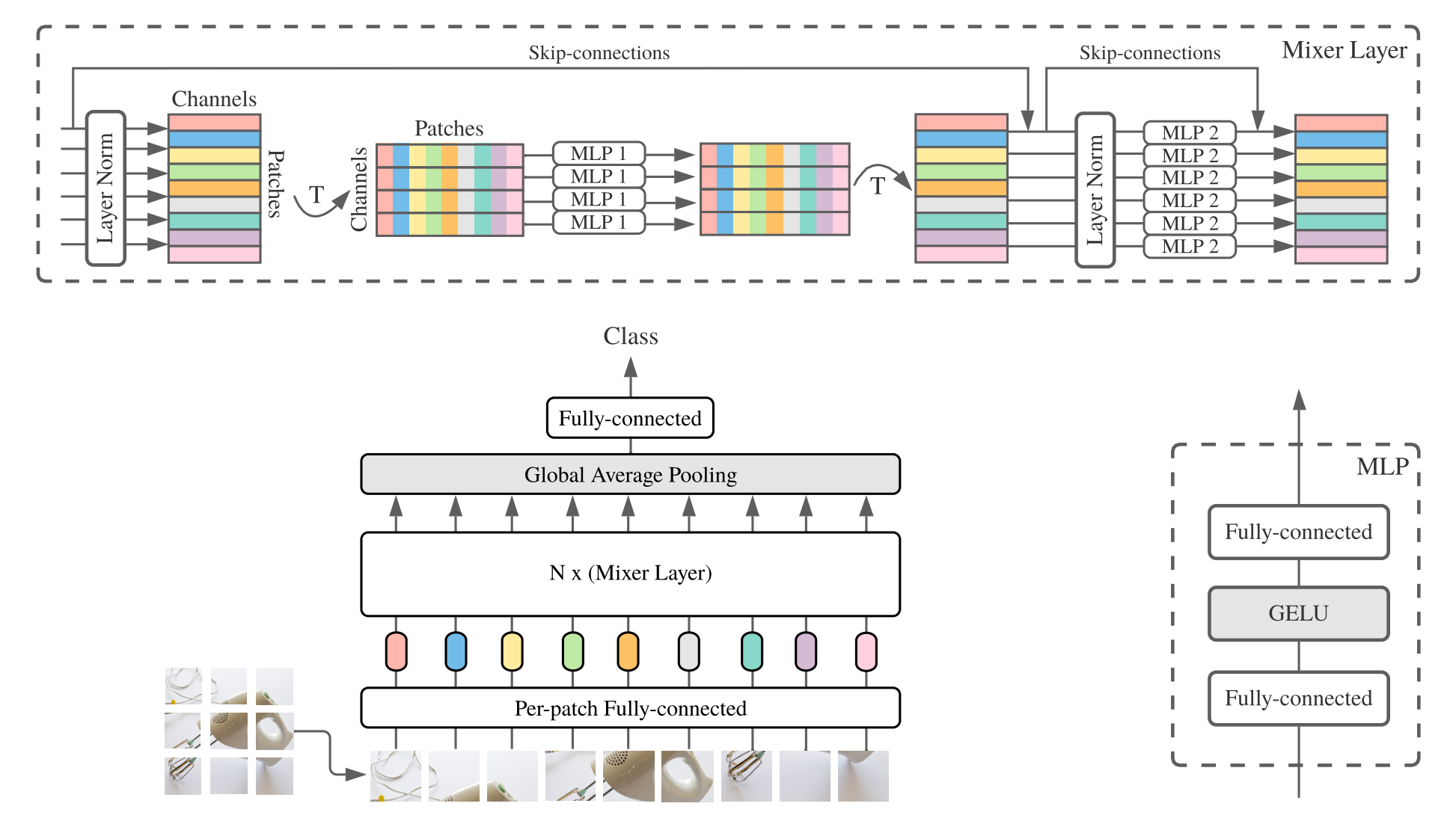
MLP-Mixer ( микшер для короткометражных) состоит из линейных встраиваний, слоев микшера и головки классификатора. Слои смесителей содержат один MLP-смешивающий токен и один MLP-MIX-MIX, каждый из которых состоит из двух полностью подключенных слоев и нелинейности гелу. Другие компоненты включают в себя: скип-соединения, отсечение и линейную головку классификатора.
Для установки следуйте тем же шагам, что и выше.
Мы предоставляем модели Mixer-B/16 и Mixer-L/16, предварительно обученные наборам данных ImageNet и ImageNet-21K. Подробности можно найти в таблице 3 смесительной бумаги. Все модели можно найти по адресу:
https://console.cloud.google.com/storage/mixer_models/
Обратите внимание, что эти модели также доступны непосредственно от TF-Hub: Sayakpaul/Collections/MLP-Mixer (внешний вклад Саяка Пола).
Мы запустили код с тонкой настройкой в Google Cloud Machine с четырьмя графическими процессорами V100 с параметрами адаптации по умолчанию из этого репозитория. Вот результаты:
| вверх по течению | модель | набор данных | точность | Wall_clock_time | связь |
|---|---|---|---|---|---|
| ImageNet | Микшер-B/16 | cifar10 | 96,72% | 3,0H | tensorboard.dev |
| ImageNet | Микшер-L/16 | cifar10 | 96,59% | 3,0H | tensorboard.dev |
| ImageNet-21K | Микшер-B/16 | cifar10 | 96,82% | 9.6H | tensorboard.dev |
| ImageNet-21K | Микшер-L/16 | cifar10 | 98,34% | 10,0H | tensorboard.dev |
Для получения подробной информации обратитесь к сообщению в блоге Google AI Lit: добавление языкового понимания в модели изображений или прочитайте бумагу CVPR «Lit: Zero Shot Transfer с настройкой текста Bocked-image» (https://arxiv.org/abs/2111.079911 )
Мы опубликовали модель Transformer B/16-базой с точностью ImageNet ZeroShot 72,1%и моделью L/16-16 с точностью imemenet ZeroShot 75,7%. Для получения более подробной информации об этих моделях, пожалуйста, обратитесь к карте Lit Model.
Мы предоставляем демонстрацию в браузере с небольшими текстовыми кодерами для интерактивного использования (самые маленькие модели должны даже работать на современном сотовом телефоне):
https://google-research.github.io/vision_transformer/lit/
И, наконец, колаба для использования моделей JAX с помощью кодеров изображения и текстовых систем:
https://colab.research.google.com/github/google-research/vision_transformer/blob/main/lit.ipynb
Обратите внимание, что ни одна из вышеуказанных моделей еще не поддерживает многоязычные входы, но мы работаем над публикацией таких моделей и обновим этот репозиторий, как только они станут доступными.
Этот репозиторий содержит только код оценки только для моделей LIT. Вы можете найти код обучения в репозитории big_vision :
https://github.com/google-research/big_vision/tree/main/big_vision/configs/proj/image_text
Ожидаемые результаты ZeroShot от model_cards/lit.md (обратите внимание, что оценка ZeroShot немного отличается от упрощенной оценки в Colab):
| Модель | B16B_2 | L16L |
|---|---|---|
| ImageNet Zero-Shot | 73,9% | 75,7% |
| ImageNet v2 Zero-Shot | 65,1% | 66,6% |
| CIFAR100 нулевой выстрел | 79,0% | 80,5% |
| Pets37 Zero-Shot | 83,3% | 83,3% |
| RESISC45 ZERO-SHOT | 25,3% | 25,6% |
| Подписи MS-COCO Изображение в текст | 51,6% | 48,5% |
| Подписи MS-COCO | 31,8% | 31,1% |
В то время как выше, чем колаба, очень полезны для начала, вы обычно захотите тренироваться на большей машине с более мощными ускорителями.
Вы можете использовать следующие команды для настройки виртуальной машины с помощью графических процессоров в Google Cloud:
# Set variables used by all commands below.
# Note that project must have accounting set up.
# For a list of zones with GPUs refer to
# https://cloud.google.com/compute/docs/gpus/gpu-regions-zones
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-gpu
ZONE=europe-west4-b
# Below settings have been tested with this repository. You can choose other
# combinations of images & machines (e.g.), refer to the corresponding gcloud commands:
# gcloud compute images list --project ml-images
# gcloud compute machine-types list
# etc.
gcloud compute instances create $VM_NAME
--project= $PROJECT --zone= $ZONE
--image=c1-deeplearning-tf-2-5-cu110-v20210527-debian-10
--image-project=ml-images --machine-type=n1-standard-96
--scopes=cloud-platform,storage-full --boot-disk-size=256GB
--boot-disk-type=pd-ssd --metadata=install-nvidia-driver=True
--maintenance-policy=TERMINATE
--accelerator=type=nvidia-tesla-v100,count=8
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud compute ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud compute instances stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud compute instances delete --project $PROJECT --zone $ZONE $VM_NAMEВ качестве альтернативы, вы можете использовать следующие аналогичные команды для настройки облачной виртуальной машины с прикрепленными к ним TPU (ниже команды, скопированных из учебника TPU):
PROJECT=my-awesome-gcp-project # Project must have billing enabled.
VM_NAME=vit-jax-vm-tpu
ZONE=europe-west4-a
# Required to set up service identity initially.
gcloud beta services identity create --service tpu.googleapis.com
# Create a VM with TPUs directly attached to it.
gcloud alpha compute tpus tpu-vm create $VM_NAME
--project= $PROJECT --zone= $ZONE
--accelerator-type v3-8
--version tpu-vm-base
# Connect to VM (after some minutes needed to setup & start the machine).
gcloud alpha compute tpus tpu-vm ssh --project $PROJECT --zone $ZONE $VM_NAME
# Stop the VM after use (only storage is billed for a stopped VM).
gcloud alpha compute tpus tpu-vm stop --project $PROJECT --zone $ZONE $VM_NAME
# Delete VM after use (this will also remove all data stored on VM).
gcloud alpha compute tpus tpu-vm delete --project $PROJECT --zone $ZONE $VM_NAME А затем принесите репозиторий и зависимости установки (включая jaxlib с поддержкой TPU), как обычно:
git clone --depth=1 --branch=master https://github.com/google-research/vision_transformer
cd vision_transformer
# optional: install virtualenv
pip3 install virtualenv
python3 -m virtualenv env
. env/bin/activateЕсли вы подключены к виртуальной машине с прикрепленными графическими процессорами, установите JAX и другие зависимости со следующей командой:
pip install -r vit_jax/requirements.txtЕсли вы подключены к виртуальной машине с прикрепленным TPU, установите JAX и другие зависимости со следующей командой:
pip install -r vit_jax/requirements-tpu.txtУстановите FlaxFormer, следуйте инструкциям, представленным в соответствующем хранилище, связанном здесь.
Как для графических процессоров, так и для TPU, проверьте, что JAX может подключаться к прикрепленным акселераторам с командой:
python -c ' import jax; print(jax.devices()) 'И, наконец, выполнить одну из команд, упомянутых в разделе, настраивать модель.
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
@article{tolstikhin2021mixer,
title={MLP-Mixer: An all-MLP Architecture for Vision},
author={Tolstikhin, Ilya and Houlsby, Neil and Kolesnikov, Alexander and Beyer, Lucas and Zhai, Xiaohua and Unterthiner, Thomas and Yung, Jessica and Steiner, Andreas and Keysers, Daniel and Uszkoreit, Jakob and Lucic, Mario and Dosovitskiy, Alexey},
journal={arXiv preprint arXiv:2105.01601},
year={2021}
}
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
@article{chen2021outperform,
title={When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations},
author={Chen, Xiangning and Hsieh, Cho-Jui and Gong, Boqing},
journal={arXiv preprint arXiv:2106.01548},
year={2021},
}
@article{zhuang2022gsam,
title={Surrogate Gap Minimization Improves Sharpness-Aware Training},
author={Zhuang, Juntang and Gong, Boqing and Yuan, Liangzhe and Cui, Yin and Adam, Hartwig and Dvornek, Nicha and Tatikonda, Sekhar and Duncan, James and Liu, Ting},
journal={ICLR},
year={2022},
}
@article{zhai2022lit,
title={LiT: Zero-Shot Transfer with Locked-image Text Tuning},
author={Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas},
journal={CVPR},
year={2022}
}
В обратном хронологическом порядке:
2022-08-18: добавленная модель Lit-B16B_2, которая была обучена для 60K шагов (LIT_B16B: 30K) без линейной головки на стороне изображения (LIT_B16B: 768) и имеет лучшую производительность.
2022-06-09: добавлены модели VIT и миксера, обученные с нуля с использованием GSAM на ImageNet без сильного увеличения данных. Результирующие VIT опережают VIT с аналогичными размерами, обученными с использованием Adamw Optimizer или исходного алгоритма SAM, или с сильным дополнением данных.
2022-04-14: добавленные модели и колаб для моделей LIT.
2021-07-29: добавлены модели Augreg Vit-B/8 (3 контрольные точки вверх по течению и адаптация с разрешением = 224).
2021-07-02: Добавлена «Когда трансформаторы зрения опережают Resnets ...»
2021-07-02: Добавлены SAM (минимизация резкости) Оптимизированные контрольные точки Vit и MLP-Mixer.
2021-06-20: добавил бумагу «Как тренировать свой вит? ...» и новая колаба, чтобы исследовать предварительно обученные и тонкие контрольные точки> 50K, упомянутые в газете.
2021-06-18: этот репозиторий был переписан для использования API Flax Linen и ml_collections.ConfigDict для конфигурации.
2021-05-19: С публикацией бумаги «Как тренировать свой вит? ...», мы добавили более 50 тыс. Моделей Vit и гибридных, предварительно обученных ImageNet и ImageNet-21K с различными степенями увеличения данных и регуляризации моделей и тонко настроены на ImageNet, Pets37, Kitti-Distance, Cifar-100 и RESISC45. Проверьте vit_jax_augreg.ipynb , чтобы ориентироваться в этом сокровищем моделях! Например, вы можете использовать этот колаб для извлечения имен файлов рекомендуемых предварительно обученных и тонких контрольных точек с столбца i21k_300 таблицы 3 в статье.
2020-12-01: добавлена гибридная модель R50+VIT-B/16 (Vit-B/16 на основе RESNET-50). При предварительном состоянии на ImageNet21K эта модель достигает практически производительности модели L/16 с менее чем половиной стоимости вычислительного происхождения. Обратите внимание, что «R50» несколько изменен для варианта B/16: исходный Resnet-50 имеет блоки [3,4,6,3], каждый из которых уменьшает разрешение изображения в два раза. В сочетании со стеблем Resnet это приведет к снижению 32-кратного, так что даже с размером пластыря (1,1) вариант Vit-B/16 больше не может быть реализован. По этой причине мы вместо этого используем блоки [3,4,9] для варианта R50+B/16.
2020-11-09: добавлена модель Vit-L/16.
2020-10-29: добавлены модели VIT-B/16 и Vit-L/16, предварительно предварительно проведенные на ImageNet-21K, а затем настраивались на ImageNet с разрешением 224x224 (вместо по умолчанию 384x384). Эти модели имеют суффикс "-224" в их имени. Ожидается, что они достигнут 81,2% и 82,7% топора TOP-1 соответственно.
Выпуск с открытым исходным кодом, подготовленный Андреасом Штайнером.
Примечание. Этот репозиторий был раздроблен и изменен из Google-Research/big_transfer.
Это не официальный продукт Google.


