Awesome LLM 3D
1.0.0
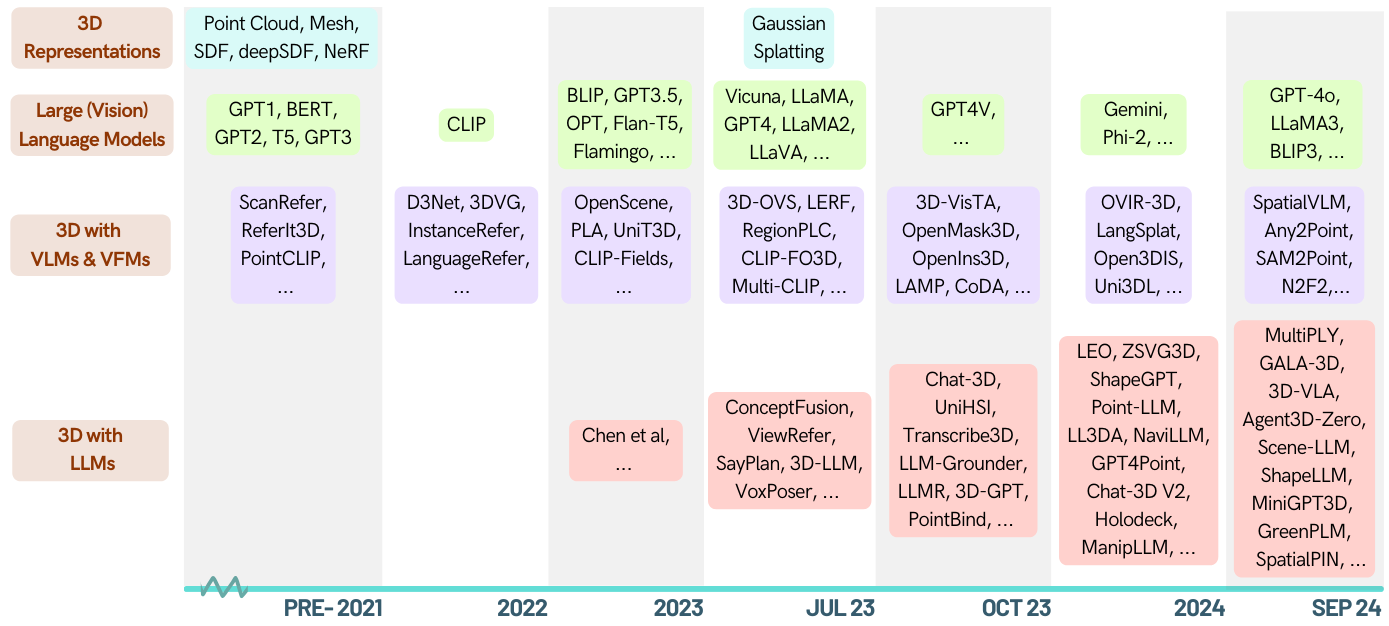
Вот курированный список документов о трехмерных задачах, уполномоченных крупными языковыми моделями (LLMS). Он содержит различные задачи, включая 3D -понимание, рассуждения, поколение и воплощенные агенты. Кроме того, мы включаем другие модели фундамента (клип, SAM) для всей картины этой области.
Это активный репозиторий, вы можете следить за последними достижениями. Если вы найдете это полезным, пожалуйста, обратите внимание на это репо и приведите бумагу.
[2024-05-16]? Ознакомьтесь с первой документом обследования в домене 3D-LLM: когда LLMs шагают в 3D World: обзор и метаанализ 3D-задач с помощью многомодальных крупных языковых моделей
[2024-01-06] Рунсен Сюй добавил хронологическую информацию, а Xianzheng MA реорганизовал ее в ZA в порядке, чтобы получить лучшие результаты после последних достижений.
[2023-12-16] Сянчжэн Ма и Яш Бхалгат курили этот список и опубликовали первую версию;
Awesome-llm-3d
3D понимание (LLM)
3D -понимание (другие модели фундамента)
3 -й рассуждения
3d поколение
3D воплощенный агент
3D -тесты
Внося
| Дата | Ключевые слова | Институт (первое) | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2024-10-12 | Ситуация3d | UIUC | Ситуационная осведомленность имеет значение в языковом рассуждении 3D видения | CVPR '24 | проект |
| 2024-09-28 | Llava-3d | HKU | Llava-3D: простой, но эффективный путь к расширению прав и возможностей LMM с 3D-осознанием | Arxiv | проект |
| 2024-09-08 | MSR3D | Бигаи | Мультимодальные рассуждения в трехмерных сценах | Neurips '24 | проект |
| 2024-08-28 | Greenplm | Посадка | Больше текста, меньше точки: к 3D-эффективному пониманию точечного языка | Arxiv | GitHub |
| 2024-06-17 | Ллана | Unibo | Llana: большой язык и помощник Nerf | Neurips '24 | проект |
| 2024-06-07 | Пространство | Оксфорд | Spatialpin: улучшение возможностей пространственных рассуждений моделей языка зрений посредством побуждения и взаимодействия трехмерных априоров | Neurips '24 | проект |
| 2024-06-03 | Spatialrgpt | UCSD | Spatialrgpt: обоснованные пространственные рассуждения в языковых моделях зрения | Neurips '24 | GitHub |
| 2024-05-02 | Minigpt-3d | Посадка | Minigpt-3D: эффективно выравнивание трехмерных облаков с большими языковыми моделями с использованием 2D Priors | ACM MM '24 | проект |
| 2024-02-27 | Шапеллм | Xjtu | Shapellm: Universal 3D -понимание объекта для воплощенного взаимодействия | Arxiv | проект |
| 2024-01-22 | Spatialvlm | Google DeepMind | Spatialvlm: модели на языке зрений с возможностями пространственных рассуждений | CVPR '24 | проект |
| 2023-12-21 | Lidar-llm | Пку | LiDAR-LLM: Изучение потенциала крупных языковых моделей для 3D-понимания лидара | Arxiv | проект |
| 2023-12-15 | 3dap | Шанхайская лаборатория | 3daxiesprompts: раскрытие 3D-пространственных возможностей GPT-4V GPT-4V | Arxiv | проект |
| 2023-12-13 | Чат-сцен | Зджу | Чат-сцен: соединение 3D-сцены и большие языковые модели с идентификаторами объектов | Neurips '24 | GitHub |
| 2023-12-5 | GPT4Point | HKU | GPT4Point: унифицированная структура для понимания и поколения точечного языка | Arxiv | GitHub |
| 2023-11-30 | LL3DA | Университет Фудана | LL3DA: визуальная интерактивная настройка инструкций для омни-3D понимание, рассуждения и планирование | Arxiv | GitHub |
| 2023-11-26 | Zsvg3d | Cuhk (Sz) | Визуальное программирование для визуального заземления с нулевым выстрелом | Arxiv | проект |
| 2023-11-18 | ЛЕО | Бигаи | Воплощенный агент универсали в 3D мира | Arxiv | GitHub |
| 2023-10-14 | Jm3d-llm | Университет Сюймен | JM3D & JM3D-LLM: повышение 3D-представления с помощью совместных мультимодальных сигналов | ACM MM '23 | GitHub |
| 2023-10-10 | Uni3d | Баай | UNI3D: Изучение единого 3D -представления в масштабе | ICLR '24 | проект |
| 2023-9-27 | - | Кауст | Соответствие 3D-формы с нулевым выстрелом | Siggraph Asia '23 | - |
| 2023-9-21 | LLM-Grounder | U-Mich | LLM-Grounder: 1D-визуальное обоснование с открытым вокабулярием с большой языковой моделью в качестве агента | ICRA '24 | GitHub |
| 2023-9-1 | Точечный | Cuhk | Точечная связка и точка-LLM: Aligning Point Cloud с многомодальностью для 3D-понимания, генерации и инструкции следующим образом | Arxiv | GitHub |
| 2023-8-31 | Pointllm | Cuhk | Pointllm: расширение прав и возможностей крупных языковых моделей для понимания облаков точек | ECCV '24 | GitHub |
| 2023-8-17 | Чат-3D | Зджу | Чат-3D: эффективная настройка модели большой языка для универсального диалога трехмерных сцен | Arxiv | GitHub |
| 2023-8-8 | 3D-Vista | Бигаи | 3D-Vista: предварительно обученный трансформатор для 3D-зрения и выравнивания текста | ICCV '23 | GitHub |
| 2023-7-24 | 3d-llm | UCLA | 3D-LLM: инъекция 3D мира в большие языковые модели | Neurips '23 | GitHub |
| 2023-3-29 | ViewRefer | Cuhk | ViewRefer: поймайте многозначные знания для трехмерного визуального заземления | ICCV '23 | GitHub |
| 2022-9-12 | - | Грань | Использование больших (визуальных) языковых моделей для понимания 3D -сцены робота | Arxiv | GitHub |
| ИДЕНТИФИКАТОР | ключевые слова | Институт (первое) | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2024-10-12 | Lexicon3d | UIUC | Lexicon3D: исследование моделей визуального основания для сложного понимания 3D -сцены | Neurips '24 | проект |
| 2024-10-07 | Diff2scene | CMU | 3D-сегментация с открытой вокабуляцией с моделями диффузии текста до изображения | ECCV 2024 | проект |
| 2024-04-07 | Any2point | Шанхайская лаборатория | Any2point: расширение возможностей в любой модальности крупных моделей для эффективного 3D-понимания | ECCV 2024 | GitHub |
| 2024-03-16 | N2F2 | Оксфорд-VGG | N2F2: Понимание иерархического сцены с вложенными областями нейронных элементов | Arxiv | - |
| 2023-12-17 | Sai3d | Пку | SAI3D: сегмент любой экземпляр в 3D -сценах | Arxiv | проект |
| 2023-12-17 | OPEN3DIS | Винай | OPEN3DIS: сегментация 3D экземпляра с открытой вокабуляцией с руководством 2D Маски | Arxiv | проект |
| 2023-11-6 | Ovir-3d | Университет Рутгерса | OVIR-3D: Открытый вокабулярный 3D-получение экземпляра без обучения на 3D данных | Corl '23 | GitHub |
| 2023-10-29 | OpenMask3d | Эт | OpenMask3d: сегментация экземпляра с открытым вокабулярием 3D | Neurips '23 | проект |
| 2023-10-5 | Открытый слияние | - | Открытый фьюжн: 3D-картирование в реальном времени в реальном времени и представление сцены | Arxiv | GitHub |
| 2023-9-22 | OV-3DDET | HKUST | CODA: Совместное обнаружение романа и кросс-модальное выравнивание для обнаружения 3D-объекта с открытым вокабуляцией | Neurips '23 | GitHub |
| 2023-9-19 | Лампа | - | От языка до 3D миров: адаптация языковой модели для восприятия облака точек | OpenReview | - |
| 2023-9-15 | Opennerf | - | OpenNerf: открытый набор 3D сегментация нейронной сцены с пиксель | OpenReview | GitHub |
| 2023-9-1 | OpenIns3d | Кембридж | OpenINS3D: SNAP и поиск 3D сегментации экземпляра Open-Vocabulary | Arxiv | проект |
| 2023-6-7 | Контрастирующий подъем | Оксфорд-VGG | Контрастный подъем: сегментация экземпляра 3D объекта с помощью медленного контрастного слияния | Neurips '23 | GitHub |
| 2023-6-4 | Многопользовательский | Эт | Multi-Clip: контрастное предварительное обучение на языке зрения для задач ответа на вопросы в трехмерных сценах | Arxiv | - |
| 2023-5-23 | 3D-OVS | Ntu | Слабо контролируемая 3D сегментация открытой вокабуляции | Neurips '23 | GitHub |
| 2023-5-21 | VL-Fields | Эдинбургский университет | VL-Fields: На пути к языковому нейронным неявным пространственным представлениям | ICRA '23 | проект |
| 2023-5-8 | Клип-FO3D | Университет Цингхуа | Clip-Fo3d: обучение бесплатно открытое 3D-представления сцены с 2D Lense Clip | ICCVW '23 | - |
| 2023-4-12 | 3D-VQA | Эт | ПРЕДВАРИТЕЛЬНАЯ ПРЕДОСТАВЛЕНИЯ ПРОДОЛЖАТИЯ | CVPRW '23 | GitHub |
| 2023-4-3 | RegionPlc | HKU | RegionPlc: Региональное точечное контрастное обучение для понимания 3D-сцены открытого мира | Arxiv | проект |
| 2023-3-20 | CG3D | JHU | Clip Goes 3D: использование оперативной настройки для языка, обоснованного 3D, распознавание | Arxiv | GitHub |
| 2023-3-16 | Lerf | UC Беркли | LERF: Языковые поля сияния | ICCV '23 | GitHub |
| 2023-2-14 | Концептфузия | Грань | Концепция: мультимодальное 3D-картирование с открытым набором | RSS '23 | проект |
| 2023-1-12 | Clip2scene | HKU | Clip2scene: к эффективному маркированию 3D-сцены понимание клипа | CVPR '23 | GitHub |
| 2022-12-1 | Unit3d | Тумана | UNIT3D: унифицированный трансформатор для 3D плотных подписи и визуального заземления | ICCV '23 | GitHub |
| 2022-11-29 | Плата | HKU | PLA: языковое понимание 3D-сцены, управляемое языком | CVPR '23 | GitHub |
| 2022-11-28 | OpenScene | Этз | OpenScene: Понимание 3D -сцены с открытыми словарями | CVPR '23 | GitHub |
| 2022-10-11 | Клип-поля | Нью -Йоркский университет | Клип-поля: слабо контролируемые семантические поля для роботизированной памяти | Arxiv | проект |
| 2022-7-23 | Семантическая абстракция | Колумбия | Семантическая абстракция: Понимание трехмерной сцены с открытым миром из моделей 2D-языка | Corl '22 | проект |
| 2022-4-26 | Scannet200 | Тумана | Основанная на языке 3D семантическую сегментацию в дикой природе в дикой природе | ECCV '22 | проект |
| Дата | ключевые слова | Институт (первое) | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2023-5-20 | 3D-CLR | UCLA | 3D-концепция обучения и рассуждения из многопрофильных изображений | CVPR '23 | GitHub |
| - | Транскрибибель3d | TTI, Чикаго | Transcribe3D: заземление LLM с использованием транскрибированной информации для 3D-референциальных рассуждений с самокорректированным созданием. | Corl '23 | GitHub |
| Дата | ключевые слова | Институт | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2023-11-29 | Shapegpt | Университет Фудана | ShapeGpt: 3D-генерация формы с унифицированной моделью мультимодального языка | Arxiv | GitHub |
| 2023-11-27 | Meshgpt | Тумана | Meshgpt: генерирование сетки треугольника с трансформаторами только декодером | Arxiv | проект |
| 2023-10-19 | 3D-GPT | Ану | 3D-GPT: процедурное 3D-моделирование с большими языковыми моделями | Arxiv | GitHub |
| 2023-9-21 | LLMR | Грань | LLMR: подсказка интерактивных миров в реальном времени с использованием больших языковых моделей | Arxiv | - |
| 2023-9-20 | Dreamllm | Мегвии | Dreamllm: синергетическое мультимодальное понимание и творение | Arxiv | GitHub |
| 2023-4-1 | Чатаватар | Deemos Tech | Dreamface: прогрессивное поколение анимируемых трехмерных лиц под руководством текста | Acm tog | веб -сайт |
| Дата | ключевые слова | Институт | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2024-01-22 | Spatialvlm | Глубокий | Spatialvlm: модели на языке зрений с возможностями пространственных рассуждений | CVPR '24 | проект |
| 2023-11-27 | Dobb-e | Нью -Йоркский университет | При привлечении роботов домой | Arxiv | GitHub |
| 2023-11-26 | СТИВ | Зджу | Смотрите и подумайте: воплощенный агент в виртуальной среде | Arxiv | GitHub |
| 2023-11-18 | ЛЕО | Бигаи | Воплощенный агент универсали в 3D мира | Arxiv | GitHub |
| 2023-9-14 | Unihsi | Шанхайская лаборатория | Унифицированное взаимодействие человека сцены с помощью побужденной цепочки контактов | Arxiv | GitHub |
| 2023-7-28 | RT-2 | Google-Deepmind | RT-2: модели на языке зрения-назывов | Arxiv | GitHub |
| 2023-7-12 | Sayplan | Центр робототехники QUT | SAYPLAN: Заземляя большие языковые модели с использованием 3D -графиков сцены для масштабируемого планирования задач робота | Corl '23 | GitHub |
| 2023-7-12 | Voxposer | Стэнфорд | Voxposer: композиционные 3D -карты значения для роботизированных манипуляций с языковыми моделями | Arxiv | GitHub |
| 2022-12-13 | RT-1 | RT-1: трансформатор робототехники для управления реальным миром в масштабе | Arxiv | GitHub | |
| 2022-12-8 | LLM-Planner | Университет штата Огайо | LLM-Planner: несколько выстрела заземленного планирования для воплощенных агентов с большими языковыми моделями | ICCV '23 | GitHub |
| 2022-10-11 | Клип-поля | NYU, Meta | Клип-поля: слабо контролируемые семантические поля для роботизированной памяти | RSS '23 | GitHub |
| 2022-09-20 | Nlmap-saycan | Запросы с открытым вокабуляцией представления сцены для реального планирования мира | ICRA '23 | GitHub |
| Дата | ключевые слова | Институт | Бумага | Публикация | Другие |
|---|---|---|---|---|---|
| 2024-09-08 | MSQA / MSNN | Бигаи | Мультимодальные рассуждения в трехмерных сценах | Neurips '24 | проект |
| 2024-06-10 | 3D-дно / 3D-папа | Умич | 3D-Grand: набор данных в миллион масштабирования для 3D-LLMS с лучшим заземлением и меньшей галлюцинацией | Arxiv | проект |
| 2024-06-03 | Spatialrgpt-Bench | UCSD | Spatialrgpt: обоснованные пространственные рассуждения в языковых моделях зрения | Neurips '24 | GitHub |
| 2024-1-18 | Сценарий | Бигаи | Сценарий: масштабирование обучения 3D-зрению для понимания сцены | Arxiv | GitHub |
| 2023-12-26 | Embodiedscan | Шанхайская лаборатория | Embodiedscan: целостный мультимодальный набор трехмерного восприятия в направлении воплощенного ИИ | Arxiv | GitHub |
| 2023-12-17 | M3dbench | Университет Фудана | M3DBench: давайте настаивать на крупных моделях с многомодальными 3D-подсказками | Arxiv | GitHub |
| 2023-11-29 | - | Глубокий | Оценка VLMS для многопрофильной аннотации 3D-объектов на основе баллов | Arxiv | GitHub |
| 2023-09-14 | Перекрестная ручка | Unibo | Глядя на слова и точки с вниманием: эталон для последовательности текста к форме | ICCV '23 | GitHub |
| 2022-10-14 | Sqa3d | Бигаи | SQA3D: расположенный вопрос, отвечающий на 3D -сцены | ICLR '23 | GitHub |
| 2021-12-20 | Скандал | Рикен Айп | Scanqa: 3D -вопрос ответа на понимание пространственной сцены | CVPR '23 | GitHub |
| 2020-12-3 | Scan2cap | Тумана | Scan2cap: контекстные сведения о плотных подписке при сканировании RGB-D | CVPR '21 | GitHub |
| 2020-8-23 | Ссылка3д | Стэнфорд | Ссылка3D: Нейронные слушатели для мелкозернистой идентификации 3D-объекта в сценах реального мира | ECCV '20 | GitHub |
| 2019-12-18 | Сканир | Тумана | ScanRefer: 3D-локализация объекта при сканировании RGB-D с использованием естественного языка | ECCV '20 | GitHub |
Ваши вклад всегда приветствуются!
Я буду держать несколько запросов на притяжение открытыми, если я не уверен, что они потрясающие для 3D LLMS, вы могли бы проголосовать за них, добавив? им.
Если у вас есть какие -либо вопросы об этом самоуверенном списке, свяжитесь с нами по адресу [email protected] или идентификатор WeChat: MXZ1997112.
Если вы найдете этот репозиторий полезным, пожалуйста, рассмотрите возможность ссылаться на эту статью:
@misc{ma2024llmsstep3dworld,
title={When LLMs step into the 3D World: A Survey and Meta-Analysis of 3D Tasks via Multi-modal Large Language Models},
author={Xianzheng Ma and Yash Bhalgat and Brandon Smart and Shuai Chen and Xinghui Li and Jian Ding and Jindong Gu and Dave Zhenyu Chen and Songyou Peng and Jia-Wang Bian and Philip H Torr and Marc Pollefeys and Matthias Nießner and Ian D Reid and Angel X. Chang and Iro Laina and Victor Adrian Prisacariu},
year={2024},
journal={arXiv preprint arXiv:2405.10255},
}Это репо вдохновлено Awesome-llm


