streaming
v0.9.1
Мы создали StreamingDataset для обучения на больших наборах данных из облачного хранилища максимально быстрым, дешевым и масштабируемым.
Он специально разработан для многоузвучных, распределенных тренировок для больших моделей-максимизирует гарантии правильности, производительность и простоту использования. Теперь вы можете эффективно тренироваться в любом месте, независимо от места обучения данных. Просто транслируйте в нужных данных, когда вам это нужно. Чтобы узнать больше о том, почему мы создали StreamingDataset, прочитайте наш блог объявлений.
StreamingDataset совместим с любым типом данных, включая изображения, текст, видео и мультимодальные данные .
При поддержке крупных поставщиков облачных хранилищ (AWS, OCI, GCS, Azure, DataBricks и любые совместимые с S3 хранилище объекта, такие как CloudFlare R2, Coreweave, Backblaze B2 и т. Д.), И разработанный в качестве замены для вашего Pytorch Classet. , StreamingDataset плавно интегрируется в существующие учебные рабочие процессы.

Потоковая передача может быть установлена с pip :
PIP Установите MosaICML-потери
Преобразовать свой набор данных в одном из наших поддерживаемых потоковых форматов:
Формат MDS (Mosaic Data Shard), который может кодировать и декодировать любой объект Python
CSV / TSV
Jsonl
Импорт Numpy как NPFROM PIL Import Image от потокового потока Import MDSWRITER# локальный или удаленный каталог для хранения сжатых выходных файлов dadata_dir = 'path-to-dataset'# Словарный сопоставление вход , 'class': 'int'}# Shard Compression, если AnsyCompression = 'ZSTD'# Сохраните образцы в качестве осколков с использованием mdswriterwith mdswriter (out = data_dir, columns = columns, compression = compression). ): sample = {'image': image.fromarray (np.random.randint (0, 256, (32, 32, 3), np.uint8)), 'class': np.random.randint (10),,
} out.write (образец)Загрузите свой набор потоковой передачи в облачное хранилище по вашему выбору (AWS, OCI или GCP). Ниже приведен один пример загрузки каталога в ведро S3 с использованием CLI AWS.
$ aws s3 cp-рекурсивный путь к датазету s3: // my-bucket/path-to-dataset
от torch.utils.data import DataLoaderFrom Streaming Import StreamingDataset# удаленный путь, где полный набор данных постоянно является StoredRemote = 'S3: // My-Bucket/Path-to-Dataset'# Local Working Dir, где набор данных кэширован во время операции = '/tmp /path-to-dataset '# Создание потокового набора данных DataSetDataset = StreamingDataset (local = local, remote = remote, shuffle = true)# Давайте посмотрим, что находится в примере# 1337 ... Sample = DataSet [1337] IMG = Sample [' Image '] cls = sample [' class ']# create pytorch DataLoaderDataloAder = dataLoader (набор данных)
Начало работы, примеры, ссылки API и другая полезная информация можно найти в наших документах.
У нас есть сквозные учебники для обучения модели на:
CIFAR-10
FaceSynthetics
Syntheticnlp
У нас также есть стартовый код для следующих популярных наборов данных, которые можно найти в streaming каталоге:
| Набор данных | Задача | Читать | Писать |
|---|---|---|---|
| Laion-400M | Текст и изображение | Читать | Писать |
| Webvid | Текст и видео | Читать | Писать |
| C4 | Текст | Читать | Писать |
| Энвики | Текст | Читать | Писать |
| Куча | Текст | Читать | Писать |
| ADE20K | Сегментация изображения | Читать | Писать |
| Cifar10 | Классификация изображений | Читать | Писать |
| Коко | Классификация изображений | Читать | Писать |
| ImageNet | Классификация изображений | Читать | Писать |
Чтобы начать обучение по этим наборам данных:
Преобразовать необработанные данные в формат .mds, используя соответствующий скрипт из каталога convert .
Например:
$ python -m Streaming.multimodal.convert.webvid -in <csv file> -out <mds output Directory>
Импортируйте класс наборов данных, чтобы начать обучение модели.
от потоковой передачи. Multimodal Import StreamingInsideWebvidDataset = StreamingInsideWebvid (local = local, remote = remote, shuffle = true)
Легко экспериментировать с смесями наборов данных с Stream . Отбор выборки набора данных можно контролировать в относительной (пропорции) или абсолютной (повторные или образцы термины). Во время потоковой передачи различные наборы данных транслируются, перетасовываются и смешаны плавно в свое время.
# mix C4, github code, and internal datasets streams = [ Stream(remote='s3://datasets/c4', proportion=0.4), Stream(remote='s3://datasets/github', proportion=0.1), Stream(remote='gcs://datasets/my_internal', proportion=0.5), ] dataset = StreamingDataset( streams=streams, samples_per_epoch=1e8, )
Уникальная особенность нашего решения: образцы находятся в том же порядке независимо от количества графических процессоров, узлов или работников процессора. Это облегчает:
Воспроизводить и отладить тренировки и шипы потерь
Загрузите контрольную точку, обученную 64 графическим процессорам и отладки на 8 графических процессоров с воспроизводимостью
См. Рисунок ниже - Обучение модели на 1, 8, 16, 32 или 64 графических процессоров дает ту же кривую потерь (вплоть до ограничений математики с плавающей запятой!)
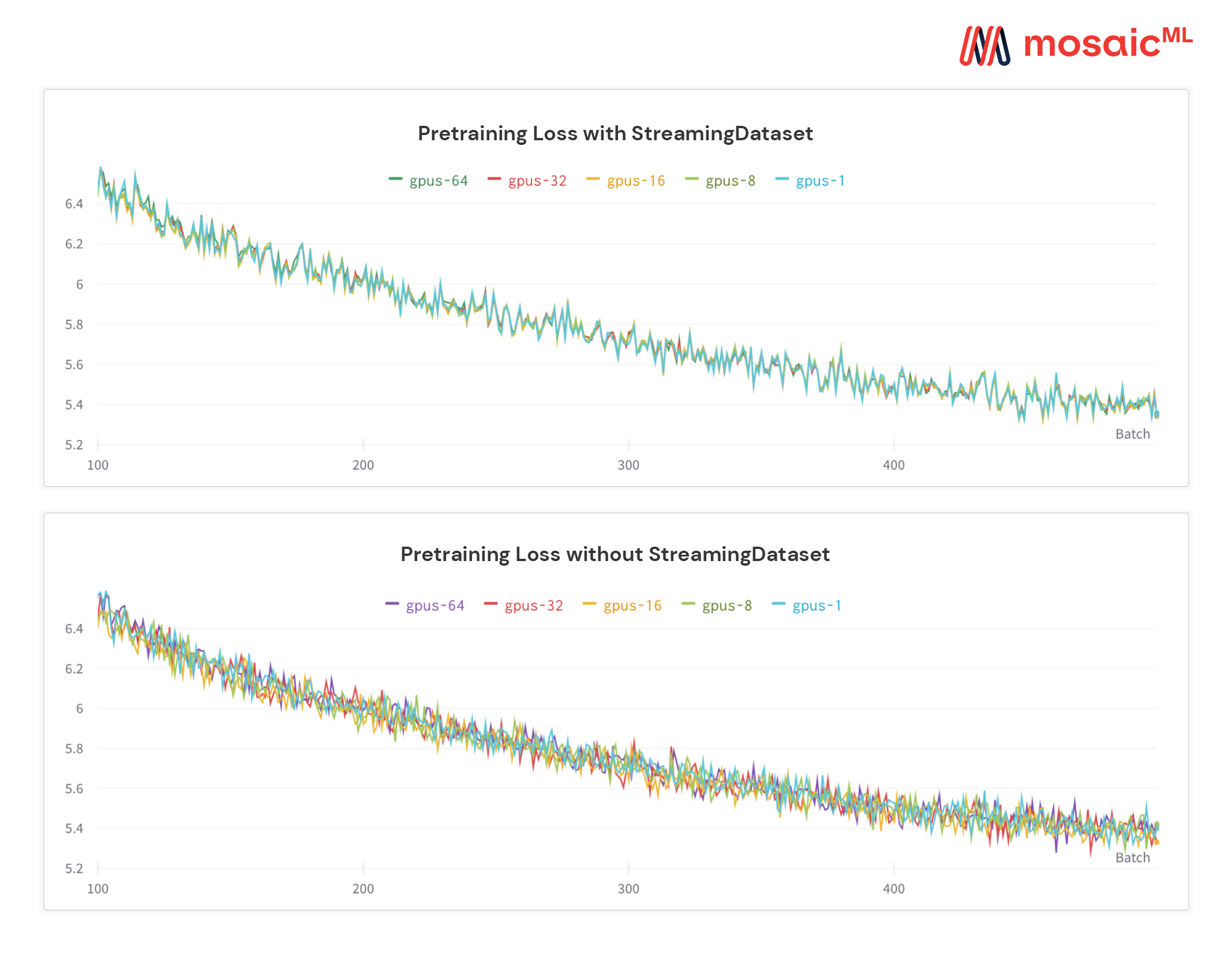
Это может быть дорого - и раздражать - ждать возобновления вашей работы, пока ваш DataLoader вращается после аппаратного сбоя или всплеска потери. Благодаря нашему детерминированному обращению, StreamingDataset позволяет возобновить тренировку за считанные секунды, а не часы, в середине долгого тренировок.
Минимизация задержки возобновления может сэкономить тысячи долларов в виде вычетных сборов и простального графического процессора по сравнению с существующими решениями.
Наш формат MDS сокращает постороннюю работу до кости, что приводит к ультра-низко-низкому задержке образца и более высокой пропускной способности по сравнению с альтернативами для рабочих нагрузок, узких, заполненных DataLoader.
| Инструмент | Пропускная способность |
|---|---|
| StreamingDataset | ~ 19000 IMG/с |
| ImageFolder | ~ 18000 IMG/с |
| WebDataset | ~ 16000 IMG/с |
Показанные результаты взяты из обучения ImageNet + RESNET-50, собранные более 5 повторений после того, как данные кэшируются после первой эпохи.
Сходимость модели от использования StreamingDataset так же хороша, как и использование локального диска, благодаря нашему алгоритму перетасовки.
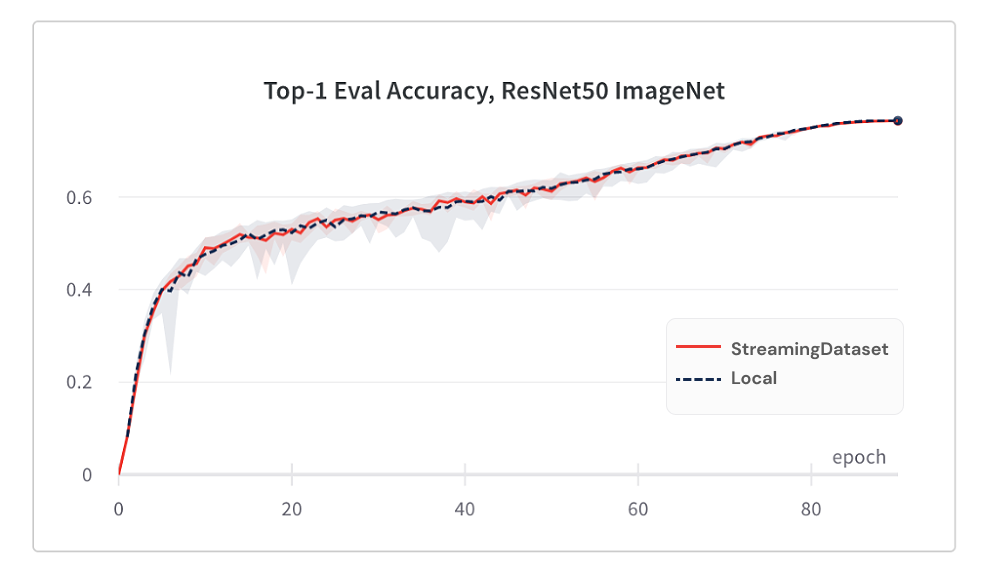
Ниже приведены результаты обучения ImageNet + RESNET-50, собранные более 5 повторений.
| Инструмент | Топ-1 точность |
|---|---|
| StreamingDataset | 76,51% +/- 0,09 |
| ImageFolder | 76,57% +/- 0,10 |
| WebDataset | 76,23% +/- 0,17 |
StreamingDataset перетасовывается по всем образцам, назначенным узлу, тогда как альтернативные растворы только образцы перетасовки в меньшем пуле (в пределах одного процесса). Переталкивание через более широкий бассейн распределяет прилегающие образцы больше. Кроме того, наш алгоритм перетасовки сводит к минимуму выпавшие образцы. Мы обнаружили, что обе эти перетасовывающие особенности выгодны для конвергенции модели.
Доступ к данным, которые вам нужны, когда вам это нужно.
Даже если образец еще не загружен, вы можете получить доступ к dataset[i] чтобы получить образец i . Загрузка сразу же начнется, и результат будет возвращен, когда она будет сделана - аналогично набору данных Pytorch в стиле карты с образцами, пронумерованными последовательно и доступными в любом порядке.
DataSet = StreamingDataset (...) Sample = DataSet [19543]
StreamingDataset будет счастливо повторить любое количество образцов. Вам не нужно навсегда удалять образцы, чтобы набор данных делился на запеченное количество устройств. Вместо этого, каждая эпоха по разным выборам образцов повторяется (нет, не выброшенная), так что каждое устройство обрабатывает одинаковый счет.
DataSet = StreamingDataset (...) dl = dataLoader (набор данных, num_workers = ...)
Динамически удалить наименьшее недавно используемые осколки, чтобы поддерживать использование диска в соответствии с указанным пределом. Это включено путем установки аргумента streamingdataset cache_limit . Смотрите Руководство по перетасовке для получения более подробной информации.
dataset = StreamingDataset( cache_limit='100gb', ... )
Вот несколько проектов и экспериментов, в которых использовался StreamingDataset. Есть что добавить? Напишите [email protected] или присоединяйтесь к нашему сообществу Slack.
Biomedlm: модель крупной языковой домены для биомедицины Mosaicml и Stanford CRFM
Моизаичные диффузионные модели: обучение стабильной диффузии из затрат на царапину <160 тыс. Долл. США
LLMS Mosaic: качество GPT-3 за <500 тыс. Долл. США
Mosaic Resnet: яростно быстрая тренировка компьютерного зрения с Mosaic Resnet и Composer
Mosaic deeplabv3: 5x быстрее обучение сегментации изображений с рецептами mosaicml
… Больше! Следите за обновлениями!
Мы приветствуем любые взносы, запросы или проблемы.
Чтобы начать вносить свой вклад, см. Наша страница.
PS: Мы нанимаем!
Если вам нравится этот проект, дайте нам звезду и проверьте другие наши проекты:
Композитор - современная библиотека Pytorch, которая упрощает масштабируемое, эффективное обучение нейронной сети.
Примеры MOSAICML - Справочные примеры для быстрого обучения моделей ML быстро и к высокой точности - с кодом стартового кода для моделей GPT / большой язык, стабильной диффузии, BERT, Resnet -50 и DeepLabv3
Mosaicml Cloud -наша тренировочная платформа, созданная для минимизации затрат на обучение для LLMS, диффузионных моделей и других крупных моделей-с множественной облакой оркестровки, легкого масштабирования с несколькими узлами и оптимизации под рукой для ускорения времени обучения
@misc{mosaicml2022streaming,
author = {The Mosaic ML Team},
title = {streaming},
year = {2022},
howpublished = {url{<https://github.com/mosaicml/streaming/>}},
} 

