Huawei UK University Challenge Competition 2021
1.0.0

Ведущий команды: Кахраман Костас
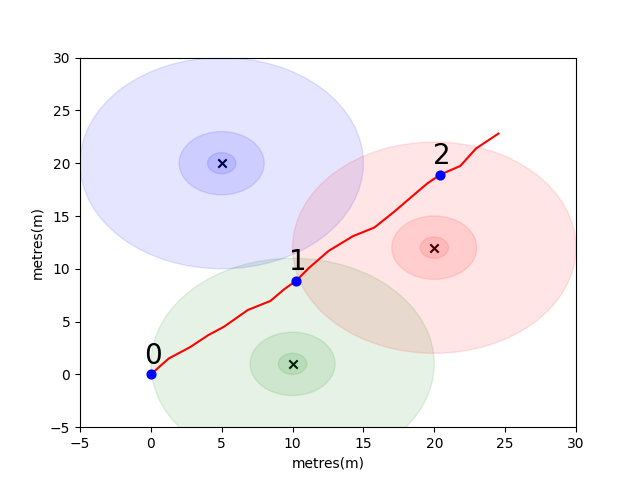
Чтобы вы начали, мы собрали простую проблему, чтобы представить некоторые ключевые концепции позиционирования в помещении. Рассмотрим следующую среду: пользователь путешествует в открытом пространстве в присутствии 3 эмиттеров Wi -Fi (мы называем данные, созданные этим пользователем траекторией). У каждого излучателя есть уникальный MAC -адрес. Пользователь оснащен смартфоном, который периодически сканирует среду Wi -Fi и записывает RSSI каждого обнаруженного Mac (в DB).
Для этой модели мы использовали стандартную модель размножения свободного пространства логарифмических потерей для каждого из излучателей. Это упрощенная модель, которая хорошо работает в свободном пространстве, но ломается в реальных внутренних средах со стенами и другими препятствиями, которые могут отскочить сигналы вокруг более сложным образом. В целом мы ожидаем увидеть резкое падение RSSI на расстоянии, так как фиксированная энергия излучающей антенны распространяется на растущую область, когда волна распространяется. На диаграмме под каждой кружкой обозначается капля 10 дБ.
Пользователь ходит на северо-восток с точки (0,0), и там телефон делает три сканирования окружающей среды. Данные, записанные при каждом сканировании, показаны ниже.
scan 0 -> {'green': -60, 'blue': -66, 'red': -67}
scan 1 -> {'green': -58, 'blue': -61, 'red': -60}
scan 2 -> {'green': -66, 'blue': -62, 'red': -59}
Сложные и локально уникальные свойства среды Wi -Fi делают его очень полезным для систем позиционирования в помещении. Например, в приведенном ниже scan 1 измеряет данные примерно в центре прориса трех излучателей, и в этой среде нет другого места, где можно было бы прочитать, что зарегистрирует аналогичные значения RSSI. Учитывая набор сканов или «отпечаток пальцев» из независимых траекторий, мы заинтересованы в расчете, насколько они похожи в пространстве Wi -Fi, поскольку это указывает на то, насколько они близки в реальном пространстве.
Ваша первая задача состоит в том, чтобы написать функцию для расчета евклидово расстояния и метрики расстояния на Манхэттене между каждым из сканирования в траектории выборки, которую мы ввели выше. Использование данных из одной траектории - это хороший способ проверить качество показателя сходства, поскольку мы можем получить довольно точные оценки истинного расстояния, используя данные из межтегического измерения телефона (IMU), которое используется мертвым расплатой пешеходов. (PDR) Модуль.
def euclidean ( fp1 , fp2 ):
raise NotImplementedError
def manhattan ( fp1 , fp2 ):
raise NotImplementedError # solution of the above functions
from scipy . spatial import distance
def euclidean ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . euclidean ( fp1 , fp2 )
def manhattan ( fp1 , fp2 ):
fp1 = list ( fp1 . values ())
fp2 = list ( fp2 . values ())
return distance . cityblock ( fp1 , fp2 ) import json
import numpy as np
import matplotlib . pyplot as plt
from metrics import eval_dist_metric
with open ( "intro_trajectory_1.json" ) as f :
traj = json . load ( f )
## Pre-calculate the pair indexes we are interested in
keys = []
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
# only calculate the upper triangle
if fp1 [ 'step_index' ] > fp2 [ 'step_index' ]:
keys . append (( fp1 [ 'step_index' ], fp2 [ 'step_index' ]))
## Get the distances from PDR
true_d = {}
for step1 in traj [ 'steps' ]:
for step2 in traj [ 'steps' ]:
key = ( step1 [ 'step_index' ], step2 [ 'step_index' ])
if key in keys :
true_d [ key ] = abs ( step1 [ 'di' ] - step2 [ 'di' ])
euc_d = {}
man_d = {}
for fp1 in traj [ 'fps' ]:
for fp2 in traj [ 'fps' ]:
key = ( fp1 [ 'step_index' ], fp2 [ 'step_index' ])
if key in keys :
euc_d [ key ] = euclidean ( fp1 [ 'profile' ], fp2 [ 'profile' ])
man_d [ key ] = manhattan ( fp1 [ 'profile' ], fp2 [ 'profile' ])
print ( "Euclidean Average Error" )
print ( f' { eval_dist_metric ( euc_d , true_d ):.2f } ' )
print ( "Manhattan Average Error" )
print ( f' { eval_dist_metric ( man_d , true_d ):.2f } ' ) Euclidean Average Error
9.29
Manhattan Average Error
4.90
Если вы правильно реализовали функции, вы должны были увидеть, что средняя ошибка для евклидовой метрики составила 9.29 а Манхэттен составлял всего 4.90 . Таким образом, для этих данных манхэттенское расстояние является лучшей оценкой истинного расстояния.
Это, конечно, очень упрощенная модель. Действительно, не существует прямой связи между значениями RSSI и расстоянием свободного пространства таким образом. Как правило, когда мы создаем наши собственные оценки расстояния, мы использовали известные расстояния PDR изнутри траектории, чтобы соответствовать числовой оценке к оценке физического расстояния.
Для вашей основной задачи мы хотели бы, чтобы вы разработали свой собственный показатель, чтобы оценить реальную дистанцию между двумя сканами, основанными исключительно на их отпечатках пальцев Wi-Fi. Мы предоставим вам реальные данные краудсорсинга, собранные в начале 2021 года из одного торгового центра. Данные будут содержать 114661 сканирование отпечатков пальцев и 879824 расстояния между сканами. Расстояния станут нашей лучшей оценкой истинного расстояния, учитывая дополнительную информацию, которую мы будем учитывать.
Мы предоставим тестовый набор пар отпечатков пальцев, и вам нужно будет написать функцию, которая расскажет нам, насколько они друг от друга.
Эта функция может быть столь же простой, как вариация на одном из метрик, которые мы ввели выше, или так же сложное, как полное решение для машинного обучения, которое по -разному учится на расстоянии различных MAC -адресов (или комбинаций MAC -адресов) в разных ситуациях.
Несколько окончательных моментов для рассмотрения:
Данные собираются как три файла для вас.
task1_fingerprints.json содержит всю информацию отпечатков пальцев для проблемы. То есть каждая запись представляет собой реальное сканирование излучателей Wi -Fi в области торгового центра. Вы обнаружите, что те же MAC -адреса будут присутствовать во многих отпечатках пальцев.
task1_train.csv содержит действительные пары обучения, чтобы помочь вам разработать/тренировать ваш алгоритм. Каждая пара id1-id2 имеет помеченное наземное расстояние истины (в метрах), и каждый идентификатор соответствует отпечаткам пальцев от task1_fingerprints.json .
task1_test.csv - это тот же формат, что и task1_train.csv , но у него нет смещений. Это то, что мы хотели бы, чтобы вы предсказывали, используя информацию о необработанном отпечатке пальцев.
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
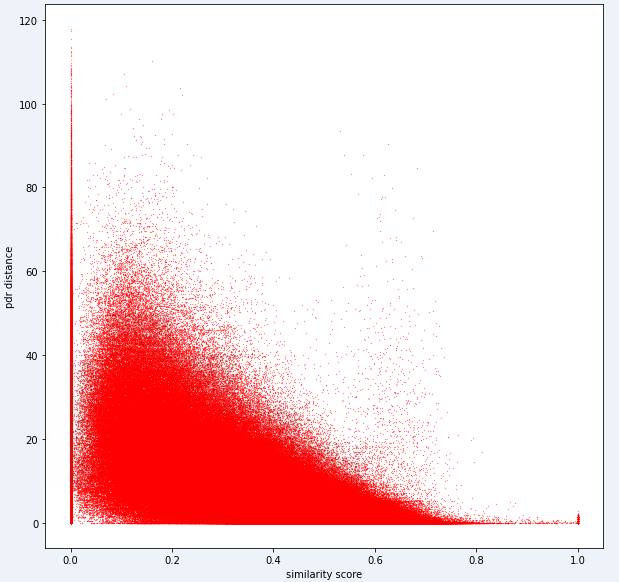
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]])В конечном счете, идеальная модель должна быть в состоянии найти точное отображение между высоким размером пространства отпечатков пальцев (1 отпечаток пальца может содержать много измерений) и 1 -размерное расстояние. Может быть полезно построить расстояние PDR (от учебных данных) против некоторой вычисленной метрики сходства, чтобы увидеть, обнаруживает ли метрика очевидная тенденция. Высокое сходство должно коррелировать с низким расстоянием.
Ниже приведена одна метрика расстояния, которую мы используем внутренне для этой задачи. Вы можете видеть, что даже для этой метрики у нас есть значительное количество шума.
Из -за этого уровня шума наш показатель оценки для задачи 1 будет предвзят к точности.
Ваше представление должно использовать точные идентификаторы из файла test1_test.csv и заполнить третий (в настоящее время пустой) столбец смещения с расчетным расстоянием (в метрах) для этой пары отпечатков пальцев.
def my_distance_function ( fp1 , fp2 ):
raise NotImplementedError output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
fp1 = fps [ id1 ]
fp2 = fps [ id2 ]
distance_estimate = my_distance_function ( fp1 , fp2 )
output_data . append ([ id1 , id2 , distance_estimate ])
with open ( "MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )Шаги в первой задаче могут быть обобщены следующим образом.
Эти шаги показаны на изображении ниже.

Мы использовали Python 3.6.5 для создания файла приложения. Мы включили несколько дополнительных модулей, которые не были включены в пример файла, приведенный в начале конкурса. Эти модули могут быть указаны как:
| Моллы | Задача |
|---|---|
| Tensorflow | Глубокое обучение |
| Панды | Анализ данных |
| Scipy | Расстояние вычислений |
Мы начали с установки этих модулей в качестве первого шага.
## 1.1 Installing modules
!p ip install tensorflow == 2.6 . 2
!p ip install scipy
!p ip install pandas На этом этапе мы установили связанное случайное семя, которое будет использоваться для получения повторяемых результатов. Таким образом, мы предоставили детерминированный путь, в котором мы получаем одинаковый результат в каждом пробеге. Однако, согласно нашим наблюдениям, результаты, полученные с разными компьютерами, могут немного отличаться (± 1%)
## 1.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )
import tensorflow as tf
tf . random . set_seed ( seed_value )
import tensorflow as tf
session_conf = tf . compat . v1 . ConfigProto ( intra_op_parallelism_threads = 1 , inter_op_parallelism_threads = 1 )
sess = tf . compat . v1 . Session ( graph = tf . compat . v1 . get_default_graph (), config = session_conf ) В этом разделе мы загружаем данные, которые будем использовать. Мы взяли код и объяснения из данного файла примера ( Task1-IPS-Challenge-2021.ipynb ).
task1_fingerprints.json содержит всю информацию отпечатков пальцев для проблемы. То есть каждая запись представляет собой реальное сканирование излучателей Wi -Fi в области торгового центра. Вы обнаружите, что те же MAC -адреса будут присутствовать во многих отпечатках пальцев.
task1_train.csv содержит действительные пары обучения, чтобы помочь вам разработать/тренировать ваш алгоритм. Каждая пара id1-id2 имеет помеченное наземное расстояние истины (в метрах), и каждый идентификатор соответствует отпечаткам пальцев от task1_fingerprints.json .
task1_test.csv - это тот же формат, что и task1_train.csv , но у него нет смещений.
## 1.3 Loading the data
import csv
import json
import os
from tqdm import tqdm
path_to_data = "for_contestants"
with open ( os . path . join ( path_to_data , "task1_fingerprints.json" )) as f :
fps = json . load ( f )
with open ( os . path . join ( path_to_data , "task1_train.csv" )) as f :
train_data = []
train_h = csv . DictReader ( f )
for pair in tqdm ( train_h ):
train_data . append ([ pair [ 'id1' ], pair [ 'id2' ], float ( pair [ 'displacement' ])])
with open ( os . path . join ( path_to_data , "task1_test.csv" )) as f :
test_h = csv . DictReader ( f )
test_ids = []
for pair in tqdm ( test_h ):
test_ids . append ([ pair [ 'id1' ], pair [ 'id2' ]]) 879824it [05:16, 2778.31it/s]
5160445it [01:00, 85269.27it/s]
На этом этапе мы выполняем извлечение функций, используя две функции. Функция feature_extraction_file просто вытаскивает соответствующие значения отпечатков пальцев (в парах) из файла JSON и отправляет их в функцию feature_extraction для выполнения вычислений.
В функции feature_extraction , если эти два отпечатка пальцев отличаются друг от друга с точки зрения размера и устройств, которые они содержат, все устройства, включенные в два отпечатка пальцев, объединяются, образуя общую последовательность без повторения. В каждом массиве мы делаем эти два массива идентичными (с точки зрения устройств, которые они включают), присваивая значение 0 не коррективным устройствам. Этот процесс объясняется примером на следующем изображении.
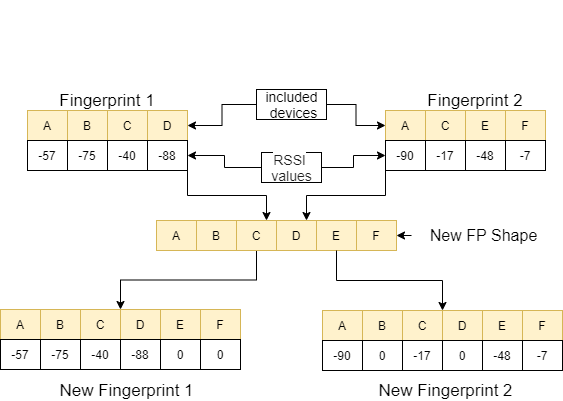
Расстояние между этими двумя отпечатками пальцев, которые сделаны схожими, рассчитывается с использованием 11 различных методов [1]. Эти методы:
Затем эти значения направлены на функцию feature_extraction_file и сохраняются как файл CSV в этой функции. Другими словами, отпечатки пальцев различных размеров превращаются в 11-функциональный файл CSV в результате этого процесса. Модель, которая будет использоваться, обучается и протестирована с этими недавно созданными функциями.
## 1.4 Feature Extraction
def feature_extraction_file ( data , name , flag ):
features = [[ "braycurtis" ,
"canberra" ,
"chebyshev" ,
"cityblock" ,
"correlation" ,
"cosine" ,
"euclidean" ,
"jensenshannon" ,
"minkowski" ,
"sqeuclidean" ,
"wminkowski" , "real" ]]
for i in tqdm (( data ), position = 0 , leave = True ):
fp1 = fps [ i [ 0 ]]
fp2 = fps [ i [ 1 ]]
feature = feature_extraction ( fp1 , fp2 )
if flag :
feature . append ( i [ 2 ])
else : feature . append ( 0 )
features . append ( feature )
with open ( name , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( features )
#print(features) ## 1.4 Feature Extraction
def feature_extraction ( fp1 , fp2 ):
mac = set ( list ( fp1 . keys ()) + list ( fp2 . keys ()))
mac = { i : 0 for i in mac }
f1 = mac . copy ()
f2 = mac . copy ()
for key in fp1 :
f1 [ key ] = fp1 [ key ]
for key in fp2 :
f2 [ key ] = fp2 [ key ]
f1 = list ( f1 . values ())
f2 = list ( f2 . values ())
braycurtis = scipy . spatial . distance . braycurtis ( f1 , f2 )
canberra = scipy . spatial . distance . canberra ( f1 , f2 )
chebyshev = scipy . spatial . distance . chebyshev ( f1 , f2 )
cityblock = scipy . spatial . distance . cityblock ( f1 , f2 )
correlation = scipy . spatial . distance . correlation ( f1 , f2 )
cosine = scipy . spatial . distance . cosine ( f1 , f2 )
euclidean = scipy . spatial . distance . euclidean ( f1 , f2 )
jensenshannon = scipy . spatial . distance . jensenshannon ( f1 , f2 )
minkowski = scipy . spatial . distance . minkowski ( f1 , f2 )
sqeuclidean = scipy . spatial . distance . sqeuclidean ( f1 , f2 )
wminkowski = scipy . spatial . distance . wminkowski ( f1 , f2 , 1 , np . ones ( len ( f1 )))
output_data = [ braycurtis ,
canberra ,
chebyshev ,
cityblock ,
correlation ,
cosine ,
euclidean ,
jensenshannon ,
minkowski ,
sqeuclidean ,
wminkowski ]
output_data = [ 0 if x != x else x for x in output_data ]
return output_data В этой задаче есть сканирование отпечатков пальцев, которые имеют сигналы RRSI из окружающей среды Wi -Fi в торговом центре. First Challange хочет, чтобы мы оценили расстояние между двумя сканами отпечатков пальцев, что является задачей регрессии. Мы использовали Ann (искусственные нейронные сети), которая вдохновлена биологической нейронной сетью. Энн состоит из трех слоев; Входной слой, скрытые слои (более одного) и выходной слой. Энн начинает с входного уровня, который включает в себя обучающие данные (с функциями), передает данные в первый скрытый слой, где данные рассчитываются по весам первого скрытого уровня. В скрытых слоях есть итерация расчета весов на входы, а затем применить их функцию активации [2]. Поскольку наша проблема заключается в регрессии, наш последний слой - единственный выходной нейрон: его выходом является прогнозируемым расстояниями между парами сканирования отпечатков пальцев. Наш первый скрытый слой имеет 64, а второй имеет 128 нейронов. Вся архитектура этой модели разделяется следующим образом. 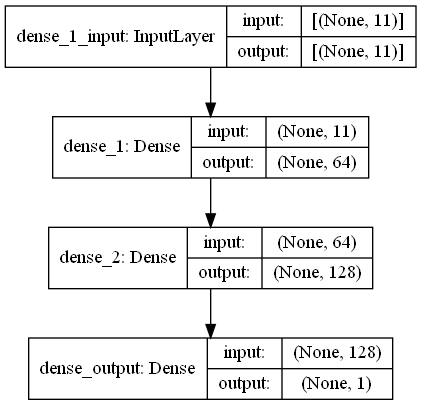
Мы выполняем глубокое обучение, используя две функции. Функция create_model формирует обучающие данные для обучения модели и определяет структуру модели. Функция model_features создает модель с указанной структурой. Созданная модель сохраняется для использования после обучения функцией create_model .
## 1.5 Model
import scipy . spatial
import pandas as pd
import numpy as np
import matplotlib . pyplot as plt
from tensorflow import keras
from tensorflow . keras . models import Sequential
from tensorflow . keras . layers import Dense
#from keras.utils.vis_utils import plot_model
% matplotlib inline
def model_features ( i , ii ):
model = Sequential ()
model . add ( Dense ( i , input_shape = ( 11 , ), activation = 'relu' , name = 'dense_1' ))
model . add ( Dense ( ii , activation = 'relu' , name = 'dense_2' ))
model . add ( Dense ( 1 , activation = 'linear' , name = 'dense_output' ))
model . compile ( optimizer = 'adam' , loss = 'mse' , metrics = [ 'mae' ])
model . summary ()
#plot_model(model, to_file='model_plot.png', show_shapes=True, show_layer_names=True)
#print(model.get_config())
return model
def create_model ( name ):
df = pd . read_csv ( name )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X )
y_train = np . array ( df [ df . columns [ - 1 ]])
model = model_features ( 64 , 128 )
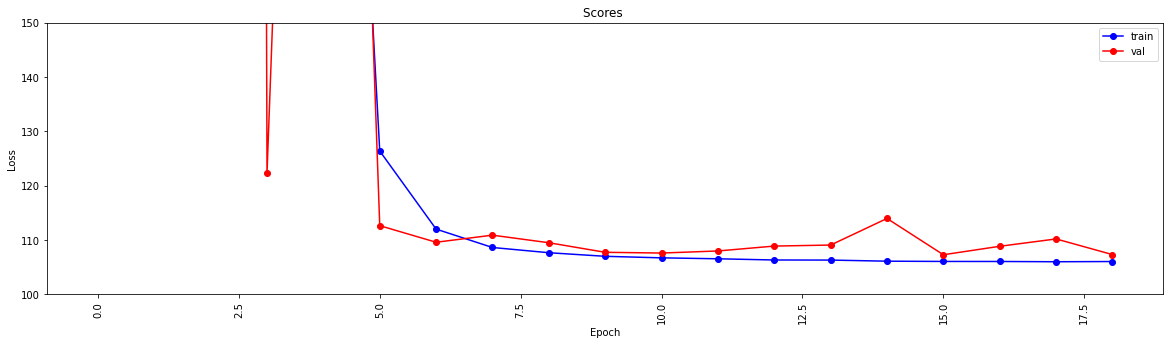
history = model . fit ( X_train , y_train , epochs = 19 , validation_split = 0.5 ) #,batch_size=1)
loss = history . history [ 'loss' ]
val_loss = history . history [ 'val_loss' ]
my_xticks = list ( range ( len ( loss )))
plt . figure ( figsize = ( 20 , 5 ))
plt . plot ( my_xticks , loss , linestyle = '-' , marker = 'o' , color = 'b' , label = "train" )
plt . plot ( my_xticks , val_loss , linestyle = '-' , marker = 'o' , color = 'r' , label = "val" )
plt . title ( "Scores " )
plt . legend ( numpoints = 1 )
plt . ylabel ( "Loss" )
plt . xlabel ( "Epoch" )
plt . xticks ( rotation = 90 )
plt . ylim ([ 100 , 150 ])
plt . show ()
madelname = "./THEMODEL"
model . save ( madelname )
print ( "Model Created!" )
Эта функция проверяет, проходили ли данные обучения и тестирования извлечение функций. Если у них нет, это создает эти файлы и модель, вызывая соответствующие функции. После обработки модели и всех извлечений функций она форматирует тестовые данные для получения конечных результатов.
## 1.6 Checking the inputs
from numpy import inf
from numpy import nan
def create_new_files ( train , test ):
model_path = "./THEMODEL/"
my_train_file = 'new_train_features.csv'
my_test_file = 'new_test_features.csv'
if os . path . isfile ( my_train_file ) :
pass
else :
print ( "Please wait! Training data feature extraction is in progress... n it will take about 10 minutes" )
feature_extraction_file ( train , my_train_file , 1 )
print ( "TThe training feature extraction completed!!!" )
if os . path . isfile ( my_test_file ) :
pass
else :
print ( "Please wait! Testing data feature extraction is in progress... n it will take about 100-120 minutes" )
feature_extraction_file ( test , my_test_file , 0 )
print ( "The testing feature extraction completed!!!" )
if os . path . isdir ( model_path ):
pass
else :
print ( "Please wait! Creating the deep learning model... n it will take about 10 minutes" )
create_model ( my_train_file )
print ( "The model file created!!! n n n " )
model = keras . models . load_model ( model_path )
df = pd . read_csv ( my_test_file )
df . replace ([ np . inf , - np . inf ], np . nan , inplace = True )
df = df . fillna ( 0 )
X_train = df [ df . columns [ 0 : - 1 ]]
X_train = np . array ( X_train )
y_train = np . array ( df [ df . columns [ - 1 ]])
predicted = model . predict ( X_train )
print ( "Please wait! Creating resuşts... " )
return predicted Этот шаг запускает функции извлечения и процессы создания моделей и позволяет начать все процессы. Таким образом, используя идентификаторы из файла test1_test.csv , он заполняет третий столбец (смещение) с расчетным расстоянием для этих пар отпечатков пальцев, и сохраняет этот файл в каталоге с именем TASK1-MySubmission.csv .
## 1.7 Submission
distance_estimate = create_new_files ( train_data , test_ids )
count = 0
output_data = [[ "id1" , "id2" , "displacement" ]]
for id1 , id2 in tqdm ( test_ids ):
output_data . append ([ id1 , id2 , distance_estimate [ count ][ 0 ]])
count += 1
print ( "Process finished. Preparing result file ..." )
with open ( "TASK1-MySubmission.csv" , "w" , newline = '' ) as f :
writer = csv . writer ( f )
writer . writerows ( output_data )
print ( "The results are ready. n See MySubmission.csv" ) Please wait! Creating the deep learning model...
it will take about 10 minutes
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 64) 768
_________________________________________________________________
dense_2 (Dense) (None, 128) 8320
_________________________________________________________________
dense_output (Dense) (None, 1) 129
=================================================================
Total params: 9,217
Trainable params: 9,217
Non-trainable params: 0
_________________________________________________________________
Epoch 1/19
13748/13748 [==============================] - 30s 2ms/step - loss: 2007233.6250 - mae: 161.3013 - val_loss: 218.8822 - val_mae: 11.5630
Epoch 2/19
13748/13748 [==============================] - 27s 2ms/step - loss: 24832.6309 - mae: 53.9385 - val_loss: 123437.0859 - val_mae: 307.2885
Epoch 3/19
13748/13748 [==============================] - 26s 2ms/step - loss: 4028.0859 - mae: 29.9960 - val_loss: 3329.2024 - val_mae: 49.9126
Epoch 4/19
13748/13748 [==============================] - 27s 2ms/step - loss: 904.7919 - mae: 17.6284 - val_loss: 122.3358 - val_mae: 6.8169
Epoch 5/19
13748/13748 [==============================] - 25s 2ms/step - loss: 315.7050 - mae: 11.9098 - val_loss: 404.0973 - val_mae: 15.2033
Epoch 6/19
13748/13748 [==============================] - 26s 2ms/step - loss: 126.3843 - mae: 7.8173 - val_loss: 112.6499 - val_mae: 7.6804
Epoch 7/19
13748/13748 [==============================] - 27s 2ms/step - loss: 112.0149 - mae: 7.4220 - val_loss: 109.5987 - val_mae: 7.1964
Epoch 8/19
13748/13748 [==============================] - 26s 2ms/step - loss: 108.6342 - mae: 7.3271 - val_loss: 110.9016 - val_mae: 7.6862
Epoch 9/19
13748/13748 [==============================] - 26s 2ms/step - loss: 107.6721 - mae: 7.2827 - val_loss: 109.5083 - val_mae: 7.5235
Epoch 10/19
13748/13748 [==============================] - 27s 2ms/step - loss: 107.0110 - mae: 7.2290 - val_loss: 107.7498 - val_mae: 7.1105
Epoch 11/19
13748/13748 [==============================] - 29s 2ms/step - loss: 106.7296 - mae: 7.2158 - val_loss: 107.6115 - val_mae: 7.1178
Epoch 12/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.5561 - mae: 7.2039 - val_loss: 107.9937 - val_mae: 6.9932
Epoch 13/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.3344 - mae: 7.1905 - val_loss: 108.8941 - val_mae: 7.4530
Epoch 14/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.3188 - mae: 7.1927 - val_loss: 109.0832 - val_mae: 7.5309
Epoch 15/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.1150 - mae: 7.1829 - val_loss: 113.9741 - val_mae: 7.9496
Epoch 16/19
13748/13748 [==============================] - 26s 2ms/step - loss: 106.0676 - mae: 7.1788 - val_loss: 107.2984 - val_mae: 7.2192
Epoch 17/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0614 - mae: 7.1733 - val_loss: 108.8553 - val_mae: 7.4640
Epoch 18/19
13748/13748 [==============================] - 28s 2ms/step - loss: 106.0113 - mae: 7.1790 - val_loss: 110.2068 - val_mae: 7.6562
Epoch 19/19
13748/13748 [==============================] - 27s 2ms/step - loss: 106.0519 - mae: 7.1791 - val_loss: 107.3276 - val_mae: 7.0981
INFO:tensorflow:Assets written to: ./THEMODELassets
Model Created!
The model file created!!!
Please wait! Creating resuşts...
100%|████████████████████████████████████████████████████████████████████| 5160445/5160445 [00:08<00:00, 610910.29it/s]
Process finished. Preparing result file ...
The results are ready.
See MySubmission.csv
Учитывая, что теперь у нас есть показатель для оценки дистанции Wi -Fi, наша следующая задача - отделить траектории от торгового центра (другой торговый центр, который используется в первом вызове!) На отдельных этажах, к которым они принадлежат. Вы можете сделать это по -разному , но мы настоятельно предложили бы подход графика кластеризации.
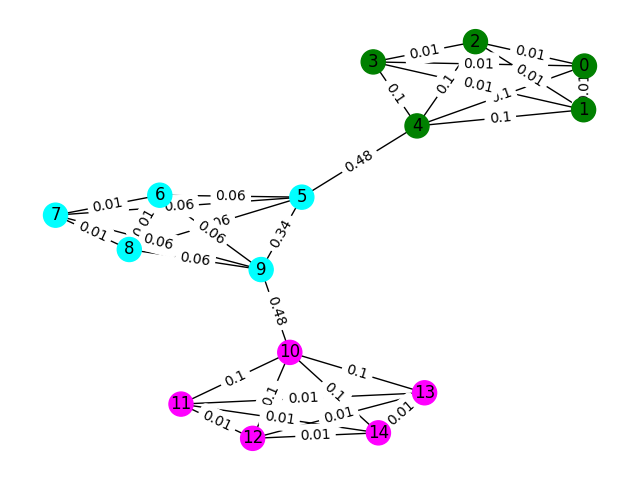
Рассмотрим каждый отпечаток пальца Wi -Fi в данных как узел на графике, и что мы можем сформировать край с другими отпечатками пальцев на графике, оценивая сходство любых двух отпечатков пальцев. Мы можем назначить высокий вес на края, где мы имеем высокое сходство между отпечатками пальцев и низким весом (или нет краем) между теми, которые не похожи. Теоретически, совершенно точный показатель сходства тривиально отделяет этажи, поскольку мы могли бы исключить все края больше, чем около 4 метров (примерно высота 1 этажа здания). В действительности вполне вероятно, что мы сделаем ложные края между этажами, и нам нужно будет каким -то образом сломать эти края.
Начнем с простого примера. Рассмотрим график ниже, где цвета узла показывают истинную классификацию пола отпечатков пальцев, и края отражают, что, по нашему мнению, эти узлы существуют на одном этаже. Для этого упражнения мы предварительно прозвучали каждое преимущество с его «оценкой между. Как правило, это выявляет ребра, которые указывают на высокую связь и могут быть кандидатами на удаление.
В этом примере используйте оценку Edge Sweetness, чтобы обнаружить графические коммутины. Верните список списков, где каждый сублист содержит идентификаторы узлов сообществ. Обратите внимание, что это просто для того, чтобы помочь вам понять проблему и не учитывать фактическое решение.
def detect_communities ( Graph ):
## This function should return a list of lists containing
## the node ids of the communities that you have detected.
eb_score = nx . edge_betweenness_centrality ( G )
raise NotImplementedError import networkx as nx
from metrics import check_result
G = nx . read_adjlist ( "graph.adjlist" )
communities = detect_communities ( G )
if check_result ( communities ):
print ( "Correct!" )
else :
print ( "Try again" ) Образец обучения данных для этой проблемы представляет собой набор из 106981 отпечатков пальцев ( task2_train_fingerprints.json ) и некоторые ребра между ними. Мы предоставили файлы, которые указывают три различных типа краев, которые должны рассматриваться по -разному.
task2_train_steps.csv Указывает ребра, которые соединяют последующие шаги в траектории. Эти края должны быть очень доверяют, поскольку они указывают на уверенность, что два отпечатка пальцев были записаны с того же этажа.
task2_train_elevations.csv указывает противоположность шагам. Эти возвышения указывают на то, что отпечатки пальцев почти определенно с другого пола. Таким образом, вы можете экстраполировать это, если отпечаток пальца
task2_train_estimated_wifi_distances.csv -это предварительные расстояния, которые мы рассчитали с использованием нашего собственного метрики расстояния. Этот показатель несовершенен, и поэтому мы знаем, что многие из этих краев будут неверными (то есть они соединят два этажа вместе). Мы предполагаем, что первоначально вы используете ребра в этом файле для построения вашего начального графика и вычисления некоторого решения. Однако, если вы получите высокий балл по Task1, вы можете рассмотреть возможность вычисления собственных расстояний Wi -Fi для создания графика.
Ваш график может быть на одном из двух уровней детализации, либо уровня траектории, либо уровня отпечатков пальцев, вы можете выбрать, какое представление вы хотите использовать, но в конечном итоге мы хотим знать кластеры траектории . Уровень траектории будет иметь каждый узел в качестве траектории, а края между узлами будут происходить, если бы отпечатки пальцев в их траекториях имели высокое сравнение. Уровень отпечатков пальцев будет иметь каждый отпечаток пальца в качестве узла. Вы можете искать идентификатор траектории отпечатка пальца, используя task2_train_lookup.json для преобразования между представлениями.
Чтобы помочь вам отладить и обучить ваше решение, мы предоставили основную правду для некоторых траекторий в task2_train_GT.json . В этом файле клавиши являются идентификаторами траектории (так же, как в task2_train_lookup.json ), а значения являются реальным идентификатором пола здания.
Тестовый набор - это тот же формат, что и учебный набор (для отдельного здания мы не собирались сделать его таким простым;)), но мы не включили эквивалентный файл истинности. Это будет удержано, чтобы позволить нам забить ваше решение.
Указывает на рассмотрение
В этом разделе мы представим какой -то пример кода для открытия файлов и построения оба типа графика.
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/train"
with open ( os . path . join ( path_to_data , "task2_train_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_train_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_train_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_train_lookup.json" )
gt_path = os . path . join ( path_to_data , "task2_train_GT.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f )
with open ( gt_path ) as f :
gt = json . load ( f )
Это один из способов построить график на уровне отпечатков пальцев, где каждый узел на графике представляет собой отпечаток пальца. У нас есть добавленные веса, которые соответствуют предполагаемым/истинным расстояниям по краям Wi -Fi и PDR соответственно. Мы также добавили края высоты, чтобы указать эту связь. Возможно, вы захотите явно применять, что при разработке вашего решения нет ни одного из этих краев (или какого -либо достоверного края высоты между траекториями).
G = nx . Graph ()
for id1 , id2 , dist in tqdm ( steps ):
G . add_edge ( id1 , id2 , ty = "s" , weight = dist )
for id1 , id2 , dist in tqdm ( wifi ):
G . add_edge ( id1 , id2 , ty = "w" , weight = dist )
for id1 , id2 in tqdm ( elevs ):
G . add_edge ( id1 , id2 , ty = "e" )График траектории, возможно, не так прост, как вам нужно думать о способе представления многих связей Wi -Fi между траекториями. На примере графика ниже мы просто воспринимаем среднее расстояние как вес, но действительно ли это лучшее представление?
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])Ваше представление должно быть файлом CSV, в котором траектории, которые, по вашему мнению, находятся на одном этаже, имеют свой индекс в том же ряду, отделенном запятыми. Каждый новый кластер будет введен в новую строку.
Например, см. Случайный вход ниже.
import random
random_data = []
n_clusters = random . randint ( 50 , 100 )
for i in range ( 0 , n_clusters ):
random_data . append ([])
for traj in set ( fp_lookup . values ()):
cluster = random . randint ( 0 , n_clusters - 1 )
random_data [ cluster ]. append ( traj )
with open ( "MyRandomSubmission.csv" , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( random_data )Шаги в задаче 2 могут быть обобщены следующим образом:
Node2vec .TASK2-Mysubmission.csv ) готовится в соответствии с траекторией идентификаторов.Эти шаги показаны на изображении ниже.

Мы использовали Python 3.6.5 для создания файла приложения. Мы включили несколько дополнительных модулей, которые не были включены в пример файла, приведенный в начале конкурса. Эти модули могут быть указаны как:
| Моллы | Задача |
|---|---|
| Scikit-learn | Машинное обучение и подготовка данных |
| Node2Vec | Масштабируемое обучение функции для сетей |
| Numpy | Математические операции |
Мы начали с установки этих модулей в качестве первого шага.
## 2.1 Installing modules
!p ip install node2vec
!p ip install scikit - learn
!p ip install numpy На этом этапе мы установили связанное случайное семя, которое будет использоваться для получения повторяемых результатов. Таким образом, мы предоставили детерминированный путь, в котором мы получаем одинаковый результат в каждом пробеге. Однако, согласно нашим наблюдениям, результаты, полученные на разных компьютерах, могут немного отличаться (± 1%)
## 2.2 Setting Random Seeds
seed_value = 0
import os
os . environ [ 'PYTHONHASHSEED' ] = str ( seed_value )
import random
random . seed ( seed_value )
import numpy as np
np . random . seed ( seed_value )В этом разделе загружаются файлы, приведенные для тестовых данных.
wifi берет идентификаторы и веса из task2_test_estimated_wifi_distances.csv .steps принимает идентификаторы и веса из файла task2_test_steps.csv .elevs переменная принимает идентификаторы из файла task2_test_elevations.csv .fp_lookup получает идентификаторы и траектории из файла task2_test_lookup.json . Мы не предпочли метода пересчета расчетных расстояний, указанных в Wi -Fi, с моделью, которую мы получили в Task1, поскольку результаты, полученные из этого процесса, не имели существенного различия. Вот почему мы не использовали файл task2_test_fingerprints.json в нашей конечной работе.
## 2.3 Loading the data
import os
import json
import csv
import networkx as nx
from tqdm import tqdm
path_to_data = "task2_for_participants/test"
with open ( os . path . join ( path_to_data , "task2_test_estimated_wifi_distances.csv" )) as f :
wifi = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
wifi . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'estimated_distance' ])])
with open ( os . path . join ( path_to_data , "task2_test_elevations.csv" )) as f :
elevs = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
elevs . append ([ line [ 'id1' ], line [ 'id2' ]])
with open ( os . path . join ( path_to_data , "task2_test_steps.csv" )) as f :
steps = []
reader = csv . DictReader ( f )
for line in tqdm ( reader ):
steps . append ([ line [ 'id1' ], line [ 'id2' ], float ( line [ 'displacement' ])])
fp_lookup_path = os . path . join ( path_to_data , "task2_test_lookup.json" )
with open ( fp_lookup_path ) as f :
fp_lookup = json . load ( f ) 3773297it [00:19, 191689.25it/s]
2767it [00:00, 52461.27it/s]
139537it [00:00, 180082.01it/s]
Мы принимаем среднее расстояние как вес при создании графика траектории. Мы использовали пример, приведенный для задачи 2 ( Task2-IPS-Challenge-2021.ipynb ) для этого процесса. Мы сохранили полученный график ( B ) в качестве списка смежности в каталоге (как my.adjlist ).
## 2.3 Generating the Trajectory graph.
B = nx . Graph ()
# Get all the trajectory ids from the lookup
valid_nodes = set ( fp_lookup . values ())
for node in valid_nodes :
B . add_node ( node )
# Either add an edge or append the distance to the edge data
for id1 , id2 , dist in tqdm ( wifi ):
if not B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . add_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )],
ty = "w" , weight = [ dist ])
else :
B [ fp_lookup [ str ( id1 )]][ fp_lookup [ str ( id2 )]][ 'weight' ]. append ( dist )
# Compute the mean edge weight
for edge in B . edges ( data = True ):
B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ] = sum ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ]) / len ( B [ edge [ 0 ]][ edge [ 1 ]][ 'weight' ])
# If you have made a wifi connection between trajectories with an elev, delete the edge
for id1 , id2 in tqdm ( elevs ):
if B . has_edge ( fp_lookup [ str ( id1 )], fp_lookup [ str ( id2 )]):
B . remove_edge ( fp_lookup [ str ( id1 )],
fp_lookup [ str ( id2 )])
nx . write_adjlist ( B , "my.adjlist" ) 100%|████████████████████████████████████████████████████████████████████| 3773297/3773297 [00:27<00:00, 135453.95it/s]
100%|██████████████████████████████████████████████████████████████████████████████████████| 2767/2767 [00:00<?, ?it/s]
Прежде чем предоставить список смежности в качестве входных данных в алгоритмы машинного обучения, мы конвертируем узлы в вектор. В нашей работе мы использовали Node2VEC в качестве методологии алгоритма встроенного графика, предложенная Grover & Leskovec в 2016 году [3]. Node2VEC-это полупроницаемый алгоритм для изучения функций узлов в сети. Node2VEC создается на основе методики Skip-Gram, которая представляет собой подход NLP, мотивированный на концепции структуры распределения. Примечание к идее, если различные слова, используемые в аналогичных контекстах, они, вероятно, имеют аналогичное значение, и между ними существует очевидная связь. Техника Skip-Gram использует центральное слово (вход) для прогнозирования соседей (вывода) при вычислении вероятностей окружающей среды на основе данного размера окна (смежная последовательность элементов до после центра), другими словами n-граммы. В отличие от подхода NLP, система Node2VEC не питается словами, которые имеют линейную структуру, а узлы и ребра, которые имеют распределенную графическую структуру. Эта многомерная структура делает встраивания сложными и вычислительно дорогими, но Node2VEC использует отрицательную выборку с оптимизацией стохастического градиентного спуска (SGD), чтобы справиться с ним. В дополнение к этому, подход случайной прогулки используется для обнаружения образцов соседних узлов исходного узла в нелинейной структуре.
В нашем исследовании мы впервые выполнили векторное представление отношений узлов в низком пространстве путем моделирования с Node2VEC с заданного расстояния двух узлов (веса). Затем мы использовали выход Node2VEC (графические встраивания), который имеет векторы узлов, для подачи традиционного алгоритма кластеризации K-средних.
Параметры, которые мы используем в NOD2VEC, могут быть указаны следующим образом:
| Гиперпараметр | Ценить |
|---|---|
| размеры | 32 |
| walk_length | 15 |
| num_walks | 100 |
| работники | 1 |
| семя | 0 |
| окно | 10 |
| min_count | 1 |
| batch_words | 4 |
Модель Node2VEC принимает список смежности в качестве входа и выводит вектор 32 размера. В этой части файл node.py создается и запускается в Jupyter Notebook . Есть две причины, по которым предпочтительнее работать внешне, а не в ноутбуке Jupyter.
Node2vec - очень дорогой вычислительный метод, ошибка переполнения ОЗУ вполне возможна, если запустить в ноутбуке Jupyter. Создание и запуск модели Node2vec снаружи избегает этой ошибки. Ячейка ниже создает файл с именем node.py. Этот файл создает модель Node2VEC. Эта модель принимает список смежности ( my.adjlist ) в качестве входного и создает 32-мерный векторный файл в качестве вывода ( vectors.emb ).
Важный! Приведенный ниже код должен быть запущен в дистрибутивах Linux (протестирован в Google Colab и Ubuntu).
# 2.4 Converting nodes to vectors
# A folder named tmp is created. This folder is essential for the node2vec model to use less RAM.
try :
if not os . path . exists ( "tmp" ):
os . makedirs ( "tmp" )
except OSError :
print ( "The folder could not be created! n Please manually create the " tmp " folder in the directory" )
node = """
# importing related modules
from node2vec import Node2Vec
import networkx as nx
#importing adjacency list file as B
B = nx.read_adjlist("my.adjlist")
seed_value=0
# Specifying the input and hyperparameters of the node2vec model
node2vec = Node2Vec(B, dimensions=32, walk_length=15, num_walks=100, workers=1,seed=seed_value,temp_folder = './tmp')
#Assigning/specifying random seeds
import os
os.environ['PYTHONHASHSEED']=str(seed_value)
import random
random.seed(seed_value)
import numpy as np
np.random.seed(seed_value)
# creation of the model
model = node2vec.fit(window=10, min_count=1, batch_words=4,seed=seed_value)
# saving the output vector
model.wv.save_word2vec_format("vectors.emb")
# save the model
model.save("vectorMODEL")
"""
f = open ( "node.py" , "w" )
f . write ( node )
f . close ()
! PYTHONHASHSEED = 0 python3 node . py После создания нашего векторного файла мы читаем этот файл ( vectors.emb ). Этот файл состоит из 33 столбцов. Первый столбец - это номер узла (IDS), и остается векторным значениями. Сортируя весь файл по первым столбцам, мы возвращаем узлы в их первоначальный заказ. Затем мы удаляем этот столбец ID, который мы больше не будем использовать. Итак, мы даем окончательную форму наших данных. Наши данные готовы к использованию в приложениях машинного обучения.
# 2.4 Reshaping data
vec = np . loadtxt ( "vectors.emb" , skiprows = 1 )
print ( "shape of vector file: " , vec . shape )
print ( vec )
vec = vec [ vec [:, 0 ]. argsort ()];
vec = vec [ 0 : vec . shape [ 0 ], 1 : vec . shape [ 1 ]] shape of vector file: (11162, 33)
[[ 9.1200000e+03 3.9031842e-01 -4.7147268e-01 ... -5.7490986e-02
1.3059708e-01 -5.4280665e-02]
[ 6.5320000e+03 -3.5591956e-02 -9.8558587e-01 ... -2.7217887e-02
5.6435770e-01 -5.7787680e-01]
[ 5.6580000e+03 3.5879680e-01 -4.7564098e-01 ... -9.7607370e-02
1.5506668e-01 1.1333219e-01]
...
[ 2.7950000e+03 1.1724627e-02 1.0272172e-02 ... -4.5596390e-04
-1.1507459e-02 -7.6738600e-04]
[ 4.3380000e+03 1.2865483e-02 1.2103912e-02 ... 1.6619096e-03
1.3672550e-02 1.4605848e-02]
[ 1.1770000e+03 -1.3707868e-03 1.5238028e-02 ... -5.9994194e-04
-1.2986251e-02 1.3706315e-03]]
Задача-2-это проблема кластеризации. Предпосылка, которую мы должны решить при решении этой проблемы, - это сколько кластеров мы должны разделить. Для этого мы попробовали разные номера кластеров и сравнили результаты, которые мы получили. На графике ниже показано сравнение количества кластеров и полученного балла. Как видно из этого графика, количество кластеров непрерывно увеличивалось между 5 и 21, с некоторыми колебаниями исключений и стабилизировалось после 21. По этой причине мы сосредоточились на количестве кластеров между 21 и 23 в нашем исследовании.
# 2.5 Determine the number of clusters
import numpy as np
import matplotlib . pyplot as plt
import seaborn as sns
import matplotlib
% matplotlib inline
sns . set_style ( "whitegrid" )
agglom = [ 24.69 , 28.14 , 28.14 , 28.14 , 30 , 33.33 , 40.88 , 38.70 , 40 , 40 , 40 , 29.12 , 45.85 , 45.85 , 48.00 , 50.17 , 57.83 , 57.83 , 57.83 ]
plt . figure ( figsize = ( 10 , 5 ))
plt . plot ( range ( 5 , 24 ), agglom )
matplotlib . pyplot . xticks ( range ( 5 , 24 ))
plt . title ( 'Number of clusters and performance relationship' )
plt . xlabel ( 'Number of clusters' )
plt . ylabel ( 'Score' )
plt . show ()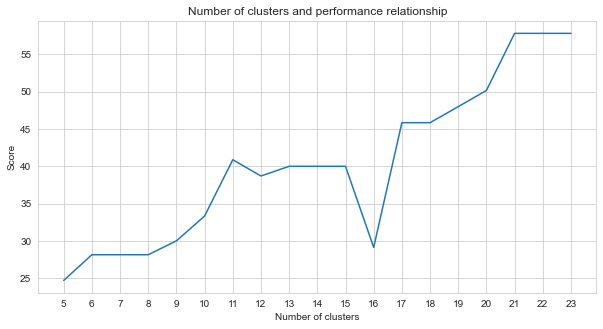
Среди неконтролируемых методов машинного обучения, которые мы пробовали (такие как K-средние, агломеративные кластеризации, распространение аффинности, средний сдвиг, спектральная кластеризация, DBSCAN, оптика, береза, мини-бат. с 23 кластерами.
K-Means-это алгоритм кластеризации, который является одним из основных и традиционных методов неконтролируемого машинного обучения, которые делают предположения для поиска однородных или естественных групп элементов (кластеров) с использованием немеплевых данных. Кластеры должны устанавливать точки (узлы в наших данных), сгруппированные вместе, которые имеют конкретное сходство. K-Means требует целевого количества центроидов, которое относится к тому, сколько групп следует разделить данные. Алгоритм начинается с группы случайно распределенных центроидов, а затем продолжает итерации, чтобы найти лучшие позиции из них. Алгоритм присваивает точки/узлы назначенным центроидам, используя в кластере сумму квадратов члена очков, это продолжает обновлять и перемещать и перемещать [4]. В нашем примере количество центроидов отражает количество этажей. Следует отметить, что это не предоставляет информацию о порядке пола.
Ниже приложение K-средних было сделано для 23 кластеров.
# 2.5 Best result
from sklearn import cluster
import time
ML_results = []
k_clusters = 23
algorithms = {}
algorithms [ 'KMeans' ] = cluster . KMeans ( n_clusters = k_clusters , random_state = 10 )
second = time . time ()
for model in algorithms . values ():
model . fit ( vec )
ML_results = list ( model . labels_ )
print ( model , time . time () - second ) KMeans(n_clusters=23, random_state=10) 1.082334280014038
Выход алгоритма машинного обучения определяет, к какому кластеру принадлежат отпечатки пальцев. Но то, что от нас требуется, - это кластерировать траектории. Следовательно, эти отпечатки пальцев преобразуются в их аналоги траектории с использованием переменной fp_lookup . Этот вывод обрабатывается в файл TASK2-Mysubmission.csv .
## 2.6 Submission
result = {}
for ii , i in enumerate ( set ( fp_lookup . values ())):
result [ i ] = ML_results [ ii ]
ters = {}
for i in result :
if result [ i ] not in ters :
ters [ result [ i ]] = []
ters [ result [ i ]]. append ( i )
else :
ters [ result [ i ]]. append ( i )
final_results = []
for i in ters :
final_results . append ( ters [ i ])
name = "TASK2-Mysubmission.csv"
with open ( name , "w" , newline = '' ) as f :
csv_writer = csv . writer ( f )
csv_writer . writerows ( final_results )
print ( name , "file is ready!" ) TASK2-Mysubmission.csv file is ready!
[1] P. Virtanen и Scipy 1.0. Scipy 1.0: фундаментальные алгоритмы для научных вычислений в Python. Природные методы, 17: 261--272, 2020.
[2] А. Герон, практическое машинное обучение с Scikit-Learn, Keras и Tensorflow: концепции, инструменты и методы для создания интеллектуальных систем. O'Reilly Media, 2019
[3] А. Гровер, Дж. Лесковек. ACM SIGKDD Международная конференция по обнаружению знаний и добыче данных (KDD), 2016.
[4] Jin X., Han J. (2011) Кластеризация K-средних. В кн.: Саммут С., Уэбб Ги (ред.) Энциклопедия машинного обучения. Спрингер, Бостон, Массачусетс. https://doi.org/10.1007/978-0-387-30164-8_425


