Noise Reduction
1.0.0

О проекте
Технический стек
Структура файла
Начиная
Результаты и демонстрация
Будущая работа
Участники
Благодарности и ресурсы
Лицензия
Шум должен быть удален, который естественным образом индуцируется, как и не экологический шум, который удаляется с помощью обозначения сигнала. Отправьте эту документацию также в этот блог о снижении шумоподавления искусственного интеллекта
Используется библиотека Librosa для аудиозантуляции.
Для аудиосиментов мы использовали Scipy
Matplotlib используется для манипулирования данными и визуализации сигнала.
Остальное является Numpy для математических операций, волна для работы в волновом файле.
Noise Reduction ├───docs ## Documents and Images │ └───Input Audio file ├─── Project Details │ | │ ├─── │ │ ├───Research papers │ │ ├───Linear Algebra │ │ ├───Neural networks & Deep Learning │ │ ├───Project Documentation │ │ ├───AI Noise Reduction Blog │ │ ├───AI Noise Reduction Report │ │ └───Code Implementation │ │ ├───AI Noise Reduction.py │ │ ├───audio.wav │ │ ├───Resources
Протестировано на Windows
git clone https://github.com/dhriti03/noise-reduction.gitcd rower-reduction
В вашем ноутбуке установите определенные библиотеки
PIP установить волну PIP установить Librosa PIP установить scipy.io PIP установить matplotlib.pyplot
*Это оригинальный аудиофайл *  *После добавления шума *
*После добавления шума *  *Окончательный аудиосигнал после удаления шума *
*Окончательный аудиосигнал после удаления шума *  *Блок -схема для проекта *
*Блок -схема для проекта * 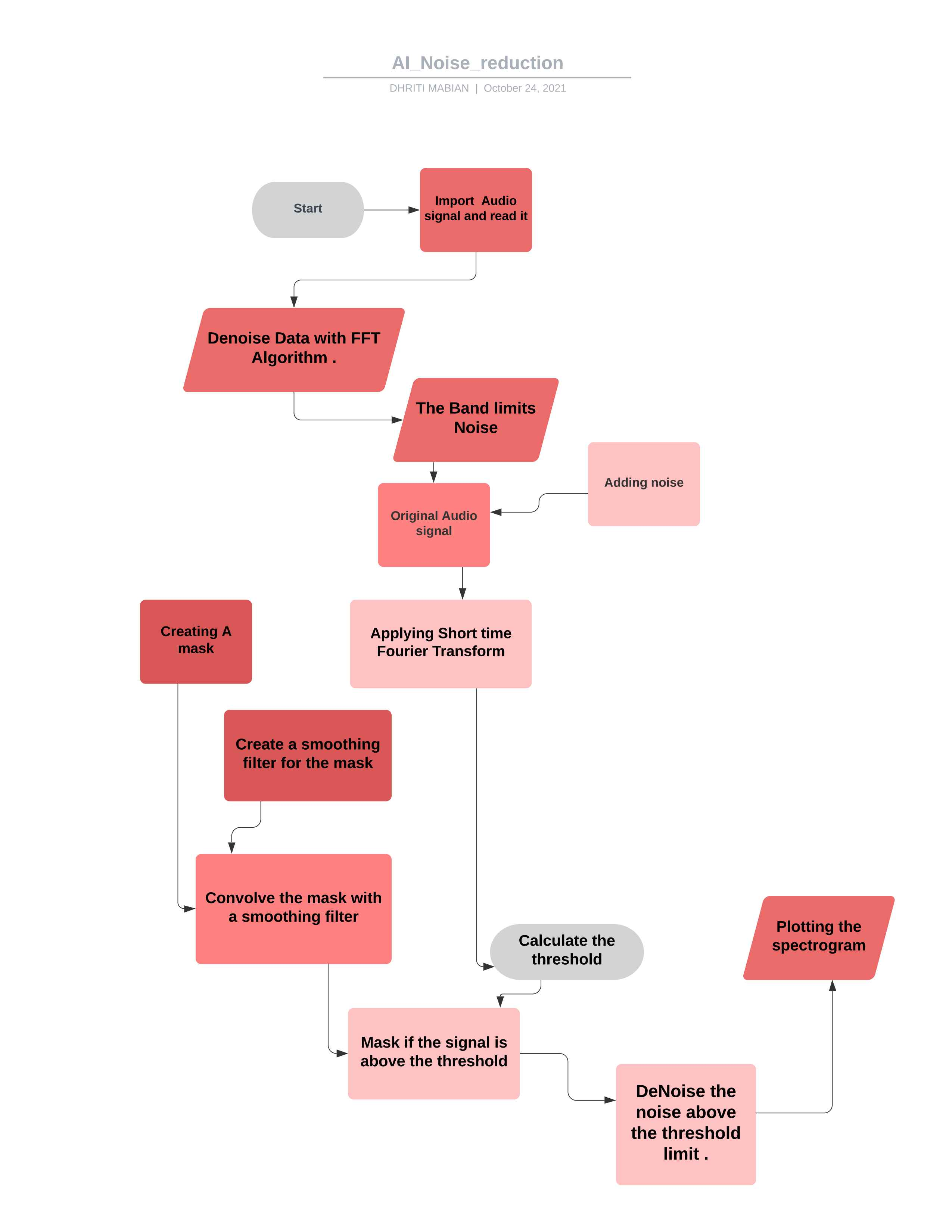
По манипулированию кодом в соответствии с вашими требованиями, вы можете использовать его для управления большинством аудиосписок. ## Теория
FFT рассчитывается над шумовой аудиоклитикой
Статистика рассчитывается по БПФ шума (по частоте)
Порог рассчитывается на основе статистики шума (и желаемой чувствительности алгоритма)
Маска определяется путем сравнения сигнала БПФ с порогом
Маска сглаживается фильтром по частоте и времени
Маска прикреплена к БПФ сигнала и перевернута
Импорт ipython из scipy.io import wavfileimport scipy.signalimport numpy в качестве npimport matplotlib.pyplot как pltimport librosaimport Wave%matplotlib inline
Здесь мы импортируем библиотеки, такие как ipython lib, используемый для создания комплексной среды для интерактивных и исследовательских вычислений.
Из библиотеки scipy.io используется для манипулирования данными и визуализацией данных с использованием широкого диапазона команд Python.
Numpy содержит многомерные структуры данных матрицы и матрицы. Его можно использовать для выполнения ряда математических операций на массивах, таких как тригонометрические, статистические и алгебраические процедуры, таким образом, очень полезная библиотека.
Библиотека matplotlib.pyplot помогает понять огромный объем данных с помощью различных визуализаций.
Librosa использовала, когда мы работаем с аудиодадами, как в генерации музыки (с использованием LSTM), автоматическим распознаванием речи. Он предоставляет строительные блоки, необходимые для создания систем поиска музыкальной информации.
%matplotlib inline , чтобы включить встроенный график, где графики/графики будут отображаться чуть ниже ячейки, где написаны команды построения построения. Он обеспечивает интерактивность с бэкэнд на Frontends, как ноутбук Jupyter.
wav_loc = r '/home/ushouse_reduction/downloads/wave/file.wav'rate, data = wavfile.read (wav_loc, mmap = false)
Здесь мы забираем местоположение пути файла WAW, а затем читаем этот файл waw с модулем WaveFile , который находится из библиотеки scipy.io . с параметрами (имя файла - строка или ручка открытия файла, который представляет собой файл ввода wav.) Затем (MMAP: Bool, необязательный, если читать данные как отображение памяти (по умолчанию: false).
def fftnoise (f): f = np.array (f, dtype = "комплекс") np = (len (f) - 1) // 2phase = np.random.rand (np) * 2 * np.piphases = np .cos (фазы) + 1j * np.sin (фазы) f [1: np + 1] * = phasesf [-1: -1 -np: -1] = np.conj (f [1: np + 1] ) return np.fft.ifft (f) .Real
Здесь мы сначала определяем функцию шума FFT вкратце, быстрое преобразование Фурье (FFT) - это алгоритм, который вычисляет дискретное преобразование Фурье (DFT) последовательности или его обратное (IDFT). Анализ Фурье преобразует сигнал из своего исходного домена (часто времени или пространства) в представление в частотной области и наоборот. DFT получается путем разложения последовательности значений на компоненты разных частот.
Использование быстрого преобразования Фурье и определение функции комплекса типа данных и, наконец, вычисление реальной части функции. В этом свободное месторождение между минимальной частотой и максимальной частотой устанавливаются на 1 и нежелательны отдыхают.
Предоставление местоположения файла
Чтение файла WAV
-32767 до +32767 является правильным аудио (быть симметричным), а 32768 означает, что звук обрезал в этой точке
Wav-file-16-битный целый ряд, диапазон составляет [-32768, 32767], что делятся на 32768 (2^15), даст правильный диапазон двойного комплекса [-1, 1]
def band_limited_noise (min_freq, max_freq, samples = 1024, samprerate = 1): freqs = np.abs (np.fft.fftfreq (образцы, 1 / выборка)) f = np.zeros (образцы) f > = min_freq, freqs <= max_freq)] = 1 возврат fftnoise (f)
Функция или временные ряды, преобразование Фурье, ограничено конечным диапазоном частот или длины волн.
Определение FREQ со стандартным FREQ с ограничением MIN и MAX.
NOUSH_LEN = 2 # secondSnoise = BAND_LIMITED_NOISE (min_freq = 4000, max_freq = 12000, samples = len (data), smplore = rate)*10noise_clip = ushome [: rate*ushy_len] audio_clip_band_limited = data+ushom
Блок белого шума с ограниченной полосой определяет двухсторонний спектр, где единицы ГЗ.
где максимум 12000 и мин, 4000, сравнивается WRT, шум и предоставленные данные.
Здесь мы обрезаем сигнал шума, имея продукт скорости и ленты сигнала шума.
таким образом, добавляя шум и заданные данные
По сути, добавление шума расширяет размер обучающего набора данных.
Случайный шум добавляется к входным переменным, делая их различными каждый раз, когда он подвергается воздействию модели.
Добавление шума к входным образцам является простой формой увеличения данных.
Добавление шума означает, что сеть менее способна запоминать образцы обучения, потому что они меняются все время,
в результате чего меньшие веса сети и более надежную сеть, которая имеет более низкую ошибку обобщения.
Импорт срока от времени импорта Timedelta как TD
Время импорта Этот модуль обеспечивает различные функции, связанные с по времени. Для связанных функций см. Также модули DateTime и календарь. класс datetime.timedelta
Продолжительность, выражающая разницу между двумя экземплярами даты, времени или даты, с разрешением микросекунды.
def _stft (y, n_fft, hop_length, win_length): return librosa.stft (y = y, n_fft = n_fft, hop_length = hop_length, win_length = win_length)
Короткое время преобразования Фурье может использоваться для количественной оценки изменения частоты и фазового содержания нестационарного сигнала с течением времени.
Длина прыга должна относиться к количеству образцов между последовательными кадрами. Для анализа сигнала длина прыга должна быть меньше, чем размер кадра, так что кадры перекрываются.
Параметры ynp.ndarray [shape = (n,)], реальное входное сигнал
n_fftint> 0 [скаляр]
Длина оконного сигнала после прокладки с помощью нулей. Количество строк в матрице STFT D составляет (1 + n_fft/2) . Значение по умолчанию, n_fft = 2048 образцов, соответствует физической продолжительности 93 миллисекунд при скорости дискретизации 22050 Гц, то есть скорость дискретизации по умолчанию в Librosa. Это значение хорошо адаптировано для музыкальных сигналов. Однако при обработке речи рекомендуемое значение составляет 512, что соответствует 23 миллисекундам при скорости дискретизации 22050 Гц. В любом случае, мы рекомендуем установить N_FFT на мощность двух для оптимизации скорости алгоритма быстрого преобразования Фурье (FFT).
hop_lengthint> 0 [скаляр]
Количество пробы аудио между соседними столбцами STFT.
Меньшие значения увеличивают количество столбцов в D, не влияя на разрешение частоты STFT.
Если не указано, по умолчанию win_length // 4 (см. Ниже).
win_lengthint <= n_fft [скаляр]
Каждый кадр звука находится в окне win_length, а затем сочетается с нулями в соответствии с N_FFT .
Меньшие значения улучшают временное разрешение STFT (то есть способность различать импульсы, которые находятся близко расположены во времени) за счет разрешения частоты (то есть способность различать чистые тона, которые находятся близко на частоте). Этот эффект известен как частотный компромисс локализации по времени и должен быть скорректирован в соответствии со свойствами входного сигнала y.
Если не указано, по умолчанию win_length = n_fft .
вернуть librosa.istft (y, hop_length, win_length)
Обратное краткосрочное преобразование Фурье (ISTFT). Согласно сложной стоимости SPECTROGRAM STFT_MATRIX к временной серии путем минимизации средней квадратной ошибки между STFT_MATRIX и STFT Y, как описано в
В общем, функция окон, длина прыжков и другие параметры должны быть такими же, как в STFT, что в основном приводит к совершенной реконструкции сигнала от немодифицированной STFT_MATRIX.
def _amp_to_db (x): return librosa.core.amplitude_to_db (x, ref = 1,0, amin = 1e-20, top_db = 80.0)
1. Совместите спектрограмму амплитуды в DB-масштабированную спектрограмму. Это эквивалентно Power_TO_DB (S ** 2), но предоставляется для удобства.
вернуть librosa.core.db_to_amplitude (x, ref = 1,0)
Преобразовать спектрограмму масштабируемой DB в спектрограмму амплитуды.
Это эффективно инвертирует amplitude_to_db:
DB_TO_AMPLUITY (S_DB) ~ = 10,0 (0,5* (S_DB + log10 (ref)/10)) **
def plot_spectrogram (сигнал, заголовок): рис, ax = plt.subplots (figsize = (20, 4)) cax = ax.matshow (сигнал, происхождение = "нижний", аспект = "auto", cmap = plt.cm. Сейсмик, vmin = -1 * np.max (np.abs (сигнал)), vmax = np.max (np.abs (сигнал)),
)Построение спекктограммы сигналом в качестве входа.
Класс оси содержит большинство элементов рисунка: ось, тик, линия2D, текст, многоугольник и т. Д., И устанавливает систему координат.
Он обеспечивает несколько цветных карт в matplotlib, доступных через эту функцию .o Найдите хорошее представление в 3D -пространстве для вашего набора данных.
Fig.colorbar (cax) ax.set_title (заголовок)
Лучший способ увидеть, что происходит, - это добавить цветовую бабу (plt.colorbar (), после создания графика рассеяния). Вы заметите, что ваши значения Out от 0 до 10000 все ниже самой низкой части стержня, где вещи очень светло -зеленые.
В целом, значения ниже Vmin будут окрашены с самым низким цветом, а значения выше Vmax получат самый высокий цвет.
Если вы установите Vmax меньше, чем Vmin, они будут поменяться. Хотя, в зависимости от точной версии Matplotlib и точных функций, вызванных, Matplotlib может дать предупреждение об ошибке. Итак, лучше всего установить Vmin всегда ниже, чем Vmax.
def plot_statistics_and_filter (mean_freq_noise, std_freq_noise, ushom_thresh, smoothing_filter): Fig, ax = plt.subplots (ncols = 2, figsize = (20, 4))) plt_std, = ax [0] .plot (std_freq_noise, label = " шума ")
plt_std, = ax [0] .plot (ushobe_thresh, label = "шумовый порог (по частоте)") ax [0] .set_title ("порог для маски")
ax [0] .legend () cax = ax [1] .matshow (smoking_filter, origin = "lower") Fig.colorbar (cax) ax [1] .set_title («Фильтр для сглаживания маски»)Установки основные статистические данные о снижении шума.
Отношение сигнал/шум (SNR или S/N)-это мера, используемая в науке и технике, которая сравнивает уровень желаемого сигнала с уровнем фонового шума.
SNR определяется как отношение сигнальной мощности к мощности шума, часто выражаемое в децибелах.
Соотношение выше 1: 1 (больше 0 дБ) указывает на больший сигнал, чем шум.
Настройка порочной частоты для маскировки шума.
Порог маскировки относится к процессу, в котором один звук становится неразборчивым из -за присутствия другого звука.
Таким образом, порог маскировки - это уровень звукового давления звука, необходимого для того, чтобы сделать звук слышен в присутствии другого шума, называемого «маскированием»
таким образом добавил порог.
Шумовые сигналы с размытым шумом с различными фильтрами с низким проходом
Применить настраиваемые фильтры к изображениям (2D свертка)
Определите Removenoise ( #, чтобы среднее сигнал (напряжение) части положительного склона (подъема) треугольной волны, чтобы попытаться удалить как можно больше шума. Audio_Clip, # Эти зажимы-это параметры, на которых мы делаем соответствующие Operations ushom_clip, n_grad_freq = 2, # Сколько частотных каналов сглаживаться с помощью mask.n_grad_time = 4, # сколько каналов времени сглаживают с помощью mask.n_fft = 2048, # Номер аудиокадры между STFT Colubs.win_length = 2048, # Каждый кадр звука находится в окне `windows ()`. n_std_thresh = 1,5, # Сколько стандартных отклонений громче, чем среднее db шума (на каждом частотном уровне), чтобы считать Signalprop_decrease = 1,0, # В какую степень вы должны уменьшить шум (1 = все, 0 = none) verbose = false , # флаг позволяет писать регулярные выражения, которые выглядят презентабельновисуально = false, # Будь то, чтобы построить шаги алгоритма):
Определите Removenoise ( для среднего сигнала (напряжение) части положительного уклона (подъем) треугольной волны, чтобы попытаться удалить как можно больше шума.
audio_clip,
Эти клипы являются параметрами, используемыми, для которых мы выполняем соответствующие операции
NOWSE_CLIP, N_GRAD_FREQ = 2 Сколько частотных каналов сглаживаться с помощью маски.
n_grad_time = 4, сколько времени каналов сглаживаться с маской.
n_fft = 2048
Номер звук кадров между столбцами STFT.
win_length = 2048, каждый кадр звука находится в окне window() . Окно n_fft длиной win_length
hop_length = 512, номер аудио кадров между столбцами STFT.
n_std_thresh = 1,5 Сколько стандартных отклонений громче, чем среднее дБ шума (на каждом уровне частоты), чтобы рассматриваться
prop_decrease = 1,0, в какой степени вы должны уменьшить шум (1 = все, 0 = нет)
словес = ложь,
Флаг позволяет писать регулярные выражения, которые выглядят презентабельно Visual = FALSE, #Будьте на графике шагов алгоритма):
hook_stft = _stft (ushom_clip, n_fft, hop_length, win_length) ushom_stft_db = _amp_to_db (np.abs (ushobe_stft)))
STFT по шуму
преобразовать в дБ
mean_freq_noise = np.mean (ishoom_stft_db, axis = 1) std_freq_noise = np.std (ishow_stft_db, axis = 1) ushoble_thresh = mean_freq_noise + std_freq_noise * n_std_thresh
Рассчитать статистику по шуму
Здесь мы для шума породы мы добавляем среднее значение и стандартный шум и N_STD -шум.
sig_stft = _stft (audio_clip, n_fft, hop_length, win_length) sig_stft_db = _amp_to_db (np.abs (sig_stft))
STFT по сигналу
mask_gain_db = np.min (_amp_to_db (np.abs (sig_stft)))))))
Рассчитать ценность для маскировки DB
Smokeing_filter = np.outer (np.concatenate (
[np.linspace (0, 1, n_grad_freq + 1, endpoint = false), np.linspace (1, 0, n_grad_freq + 2),
]
) [1: -1], np.concatenate (
[np.linspace (0, 1, n_grad_time + 1, endpoint = false), np.linspace (1, 0, n_grad_time + 2),
]
) [1: -1],
) Smokeing_filter = Smoothing_filter / np.sum (smokeing_filter)Создайте сглаживающий фильтр для маски во времени и частоте
db_thresh = np.repeat (np.reshape (ushous_thresh, [1, len (mean_freq_noise)]), np.shape (sig_stft_db) [1], axis = 0,
) .TРассчитайте порог для каждой частоты/временного корзина
sig_mask = sig_stft_db <db_thresh
маска для сигнала
sig_mask = scipy.signal.fftconvolve (sig_mask, smoothing_filter, mode = "То же") sig_mask = sig_mask * prop_decrease
Маска свертка с фильтром сглаживания
# Mask the Signalsig_stft_db_masked = (sig_stft_db * (1 - sig_mask)+ np.ones (np.shape (mask_gain_db)) * mask_gain_db * sig_mask) # mask realsig_imaged = np.imag (sig_stft) _to_amp (sig_stft_db_masked) * np.sign (sig_stft)) + (1j * sig_imag_masked)
Замаскировать сигнал
# Восстановить SignalRecovered_signal = _istft (sig_stft_amp, hop_length, win_length) recorded_spec = _amp_to_db (np.abs (_stft (recorded_signal, n_fft, hop_length, win_length))
)восстановить сигнал
Таким образом, примените маску, если сигнал выше порога
сглаживать маску сглаживающим фильтром
Применение алгоритма снижения шума для уже загруженного файла WAV.
Применение БПФ в живой записи аудиосигнала.
Еще более глубокая реализация ИИ для шумоподавления.
Применение алгоритма снижения шума для различных форматов аудиофайлов.
Аудио -сигнал в прямом эфире с микрофоном и ESP32 и, таким образом, получит файл WAV для дальнейшей вычисления и обработки сигналов.
Дхрити Мабиан
Приял Аванкар
*Sra vjti_eklavya 2021
Шреяс Атре
Резкий шах
Мужество
Метод шумоподавления
Взял шаблон у Мартина Хайнца
Тим Сейнбург
Лицензия


