IP Adapter
1.0.0
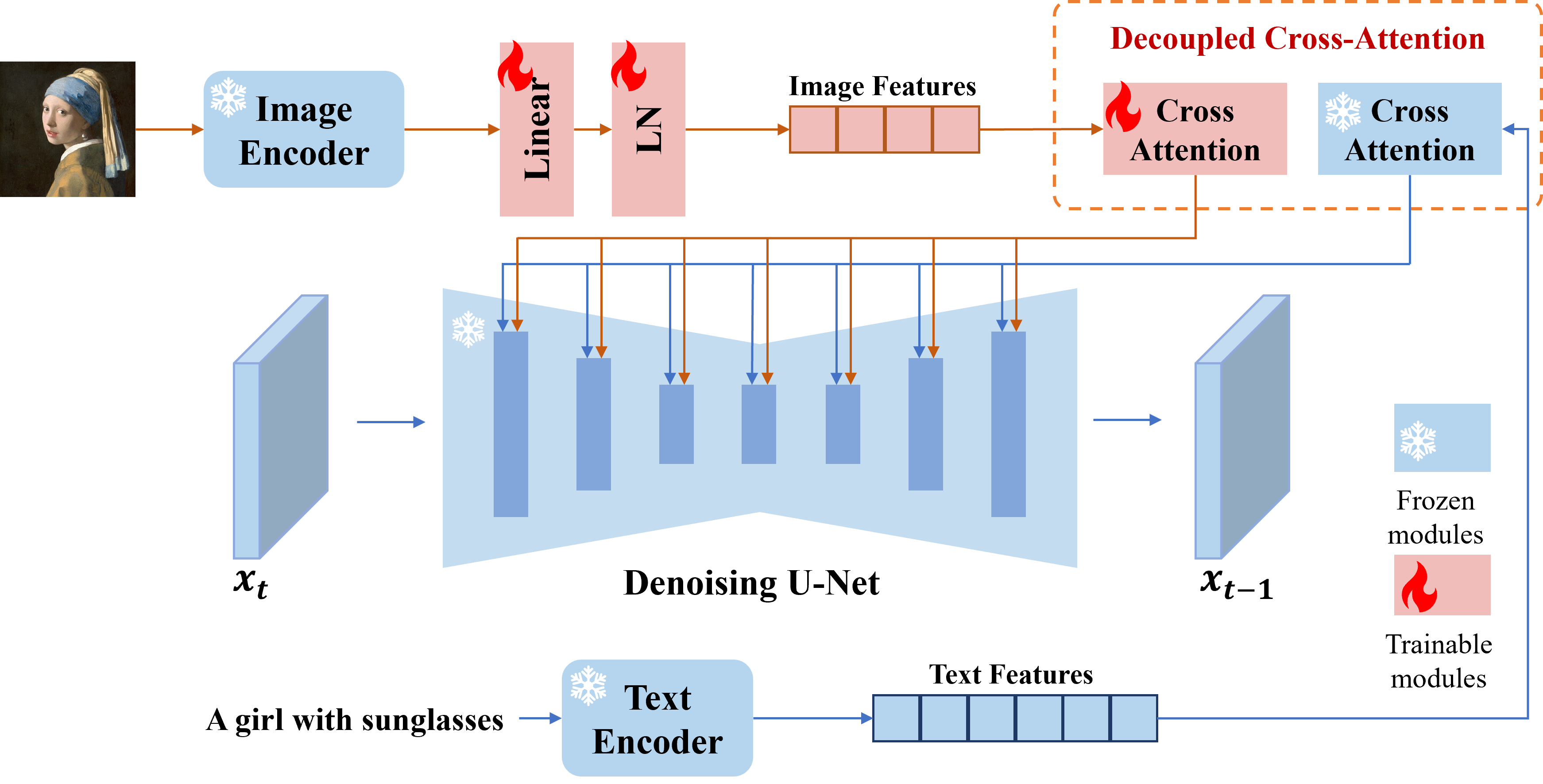
Мы представляем адаптер IP, эффективный и легкий адаптер для достижения возможностей привлечения изображения для предварительно обученных моделей диффузии текста до изображения. Адаптер IP с параметрами только 22 метра может достичь сопоставимой или даже лучшей производительности с тонкой настройкой модели приглашения изображения. Адаптер IP может быть обобщен не только для других пользовательских моделей, настраиваемых из той же базовой модели, но и до управляемой генерации с использованием существующих управляемых инструментов. Кроме того, приглашение изображения также может хорошо работать с текстовой подсказкой для выполнения мультимодального генерации изображений.
# install latest diffusers
pip install diffusers==0.22.1
# install ip-adapter
pip install git+https://github.com/tencent-ailab/IP-Adapter.git
# download the models
cd IP-Adapter
git lfs install
git clone https://huggingface.co/h94/IP-Adapter
mv IP-Adapter/models models
mv IP-Adapter/sdxl_models sdxl_models
# then you can use the notebook
Вы можете скачать модели отсюда. Чтобы запустить демонстрацию, вы также должны загрузить следующие модели:









Лучшая практика
scale=1.0 и text_prompt="" (или некоторые общие текстовые подсказки, например, «Лучшее качество», вы также можете использовать любую отрицательную текстовую подсказку). Если вы снизите scale , могут быть сгенерированы более разнообразные изображения, но они могут не столь столь же соответствовать приглашению изображения.scale , чтобы получить наилучшие результаты. В большинстве случаев настройка scale=0.5 может получить хорошие результаты. Для версии SD 1.5 мы рекомендуем использовать модели сообщества для создания хороших изображений.Адаптер IP для не-квадратных изображений
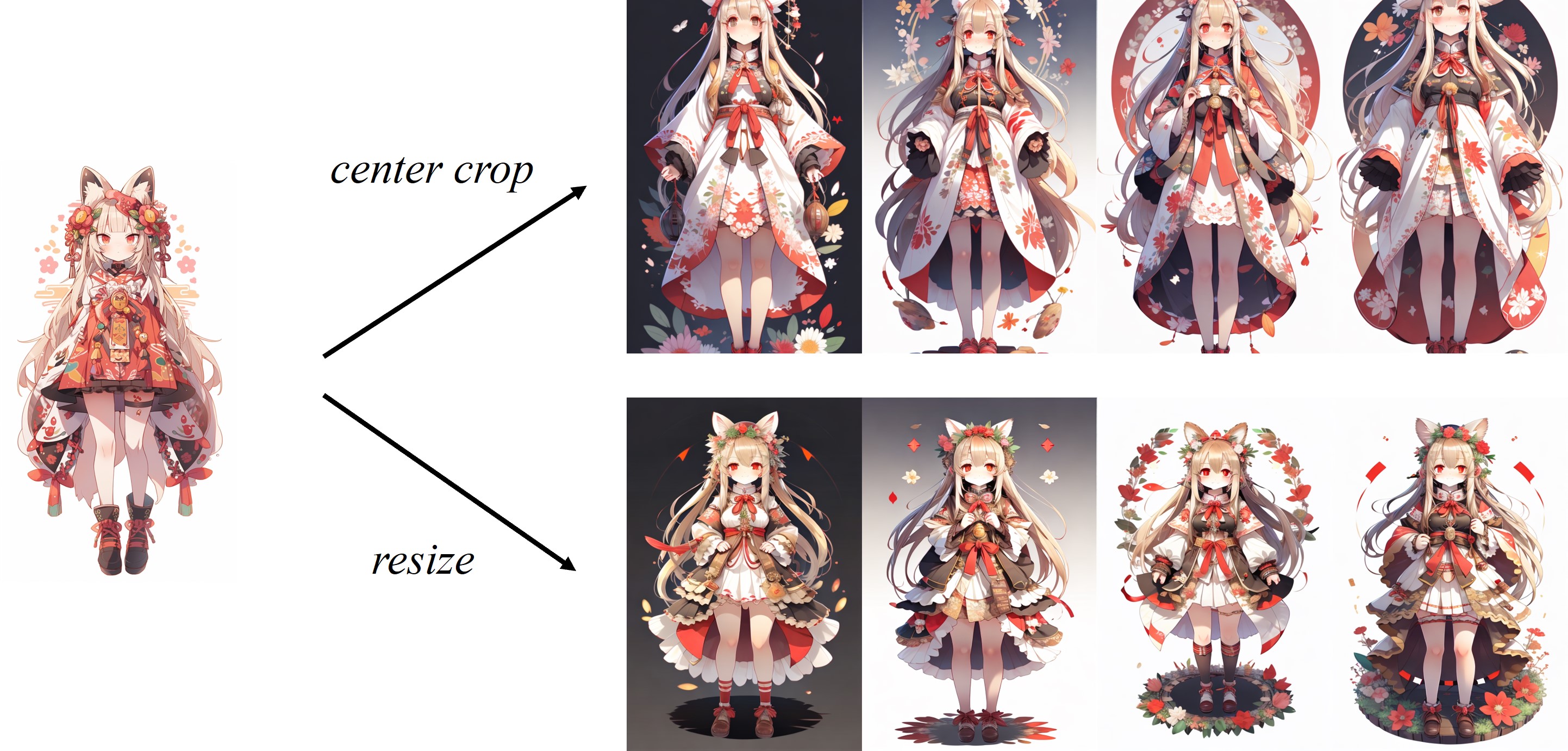
Поскольку изображение обрезано в процессоре изображения по умолчанию, IP-адаптер работает лучше всего для квадратных изображений. Для не квадратных изображений он пропустит информацию за пределами центра. Но вы можете просто изменить размер до 224x224 для не-квадратных изображений, сравнение выглядит следующим образом:
Сравнение IP-adapter_xl с Reimagine XL показано следующим образом:

Улучшения в новой версии (2023.9.8) :
Для обучения вы должны установить Accelerate и сделать свой собственный набор данных в файл JSON.
accelerate launch --num_processes 8 --multi_gpu --mixed_precision "fp16"
tutorial_train.py
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5/"
--image_encoder_path="{image_encoder_path}"
--data_json_file="{data.json}"
--data_root_path="{image_path}"
--mixed_precision="fp16"
--resolution=512
--train_batch_size=8
--dataloader_num_workers=4
--learning_rate=1e-04
--weight_decay=0.01
--output_dir="{output_dir}"
--save_steps=10000
После завершения обучения вы можете преобразовать веса со следующим кодом:
import torch
ckpt = "checkpoint-50000/pytorch_model.bin"
sd = torch . load ( ckpt , map_location = "cpu" )
image_proj_sd = {}
ip_sd = {}
for k in sd :
if k . startswith ( "unet" ):
pass
elif k . startswith ( "image_proj_model" ):
image_proj_sd [ k . replace ( "image_proj_model." , "" )] = sd [ k ]
elif k . startswith ( "adapter_modules" ):
ip_sd [ k . replace ( "adapter_modules." , "" )] = sd [ k ]
torch . save ({ "image_proj" : image_proj_sd , "ip_adapter" : ip_sd }, "ip_adapter.bin" )Этот проект стремится положительно повлиять на область генерации изображений, управляемого AI. Пользователям предоставляется свобода создания изображений, используя этот инструмент, но они должны соблюдать местные законы и использовать их ответственным образом. Разработчики не несут никакой ответственности за потенциальное неправильное использование со стороны пользователей.
Если вы найдете Adapter IP-адаптер для ваших исследований и приложений, пожалуйста, цитируйте использование этого Bibtex:
@article { ye2023ip-adapter ,
title = { IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models } ,
author = { Ye, Hu and Zhang, Jun and Liu, Sibo and Han, Xiao and Yang, Wei } ,
booktitle = { arXiv preprint arxiv:2308.06721 } ,
year = { 2023 }
}

