paper2slides
1.0.0
Преобразовать любые арксивские бумаги в слайды, используя большие языковые модели (LLMS)! Этот инструмент полезен для быстрого захвата основных идей исследовательских работ.
Некоторые примеры сгенерированных слайдов являются: Word2VEC, GAN, Transformer, Vit, цепь мыслей, Star, DPO и ученого ИИ. См. Многие другие примеры сгенерированных слайдов в демонстрации.
Сценарий будет загружать файлы из Интернета (ARXIV), отправлять информацию в API OpenAI и компилируется локально. Пожалуйста, будьте осторожны с общим содержанием и потенциальными рисками. Если у вас есть конкретный идентификатор ARXIV, который вас интересует и не хотите запускать код самостоятельно, дайте мне знать в «обсуждениях», и я был бы рад добавить слайды в демо -список.
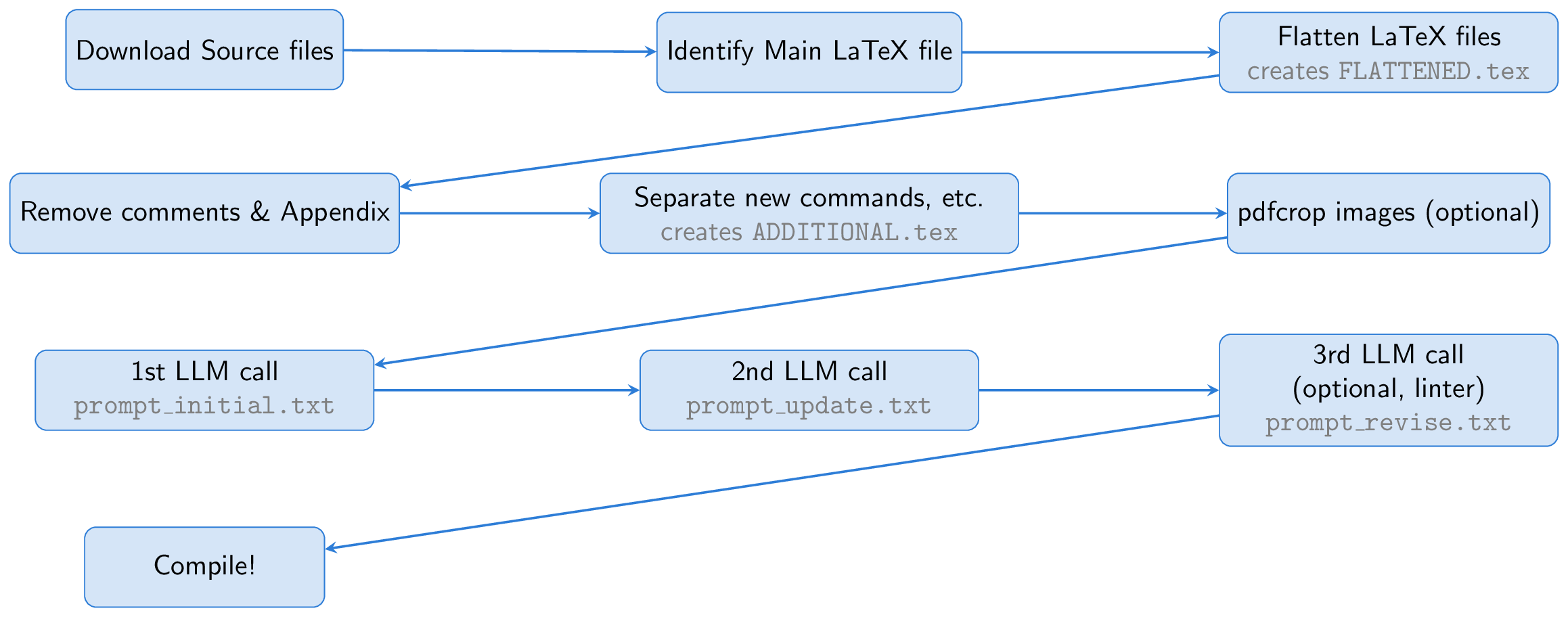
Процесс начинается с загрузки исходных файлов бумаги Arxiv. Основной латексный файл идентифицируется и сглаживается, объединяя все входные файлы в один документ ( FLATTENED.tex ). Мы предварительно обрабатываем этот объединенный файл, удалив комментарии и приложение. Этот предварительный файл, наряду с инструкциями по созданию хороших слайдов, является основой нашей подсказки.
Одна ключевая идея состоит в том, чтобы использовать Beamer для создания слайдов, позволяя нам оставаться полностью в латексной экосистеме. Этот подход по существу превращает задачу в упражнение по суммированию: преобразование длинной латексной бумаги в латекс Beamer. LLM может сделать вывод содержания фигур из их подписей и включать их в слайды, устраняя необходимость в возможностях зрения.
Чтобы помочь LLM, мы создаем файл с именем ADDITIONAL.tex , который содержит все необходимые пакеты, определения newcommand и другие настройки латекса, используемые в статье. Включая этот файл с input{ADDITIONAL.tex} в приглашении сокращает его и делает генерирующие слайды более надежными, особенно для теоретических работ со многими пользовательскими командами.
LLM генерирует код Beamer из источника Latex, но, поскольку у первого запуска могут возникнуть проблемы, мы просим LLM самостоятельно осматривать и уточнить вывод. При желании третий шаг включает в себя использование Linter для проверки сгенерированного кода, при этом результаты возвращаются в LLM для дальнейших исправлений (этот этап Линтера был вдохновлен ученом ИИ). Наконец, код Beamer собирается в PDF -презентацию с использованием PDFLATEX.
Сценарий all.zsh автоматизирует весь процесс, обычно заканчивая менее чем за несколько минут с GPT-4O для одной бумаги.
Требования:
requests библиотекуarxivopenaiarxiv-latex-cleanerpdflatexШаги для установки:
Клонировать это хранилище:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slidesУстановите необходимые пакеты Python:
pip install requests arxiv openai arxiv-latex-cleaner Убедитесь, что pdflatex установлен и доступен на пути вашей системы. При желании проверьте, можете ли вы скомпилировать образец test.tex с помощью pdflatex test.tex . Проверьте, правильно ли test.pdf . При желании работают chktex и pdfcrop .
Установите свой ключ API OpenAI:
export OPENAI_API_KEY= ' your-api-key ' all.sh ScriptЭтот скрипт автоматизирует процесс загрузки бумаги ARXIV, его обработки и преобразования в презентацию Beamer.
bash all.sh < arxiv_id > Замените <arxiv_id> на желаемый идентификатор бумаги Arxiv. Идентификатор может быть идентифицирован из URL: ID для https://arxiv.org/abs/xxxx.xxxx IS xxxx.xxxx .
Вы также можете запустить сценарии Python индивидуально для большего контроля.
Скачать и обрабатывать исходные файлы arxiv
python arxiv2tex.py < arxiv_id > Этот скрипт загружает исходные файлы указанной бумаги ARXIV, извлекает их и обрабатывает основной латексный файл. Результаты будут сохранены в source/<arxiv_id>/FLATTENED.tex и source/<arxiv_id>/ADDITIONAL.tex .
Преобразовать латекс в Beamer
python tex2beamer.py --arxiv_id < arxiv_id > Этот скрипт считывает обработанные латексные файлы и готовит слайды Beamer. Здесь мы используем API OpenAI. Мы звоняем дважды, сначала, чтобы генерировать код Beamer, а затем самостоять код Beamer. При желании используйте следующие флаги: --use_linter и --use_pdfcrop . Подсказки, отправленные в LLM, и ответ от LLM будут сохранены в tex2beamer.log . Журнал Linter будет сохранен в source/<arxiv_id>/linter.log .
Преобразовать Beamer в PDF
python beamer2pdf.py < arxiv_id >Этот скрипт собирает файл Beamer в PDF -презентацию.
Подсказки сохраняются в prompt_initial.txt , prompt_update.txt и prompt_revise.txt , но не стесняйтесь настроить их на ваши потребности. Они содержат заполнителя под названием PLACEHOLDER_FOR_FIGURE_PATHS . Это будет заменено на пути фигуры, используемые в бумаге. Мы хотим убедиться, что пути правильно используются в коде Beamer. LLM часто совершает ошибки, поэтому мы явно включаем это в приглашение.
Уровень успеха в моем опыте составляет около 90 процентов (компиляция может потерпеть неудачу, или в некоторых случаях путь изображения может быть неправильным). Если вы сталкиваетесь с какими -либо проблемами или у вас есть какие -либо предложения по улучшению, пожалуйста, сообщите мне, что сообщите мне!


