rl 6 nimmt
1.0.0
6 nimmt! это отмеченная наградами карточная игра для двух-десяти игроков с 1994 года. Цитата Википедии:
В игре есть 104 карты, каждая из которых имеет число и от одного до семи символов голов быка, которые представляют штрафные очки. Раунд из десяти ходов разыгрывается, где все игроки помещают одну карту по своему выбору на стол. Расположенные карты расположены на четыре ряда в соответствии с фиксированными правилами. Если поместить в ряд, в котором уже есть пять карт, то игрок получает эти пять карт, которые считаются штрафными очками, которые составляются в конце раунда.
6 nimmt! является конкурентной игрой неполной информации и большого количества стохастичности. Играть хорошо требует немало планирования. Одновременная игра поддается игре и блефу, в то время как некоторая долгосрочная стратегия необходима для того, чтобы избежать заканчивающихся в сложных позициях в конечной игре.
Мы внедрили слегка упрощенную версию 6 Nimmt! Как спортивная среда Openai. В отличие от оригинальной игры, когда играет на более низкую карту, чем последняя карта на всех стеке, игрок не может свободно выбрать, какой стек заменить, но вместо этого всегда будет принимать стек с наименьшим количеством штрафных очков.
До сих пор мы реализовали следующие агенты:
В качестве первого теста мы провели простой самостоятельный турнир. Начиная с пяти неподготовленных агентов, мы сыграли в общей сложности 4000 игр. Для каждой игры мы случайным образом выбирали два, три или четыре агента для игры (и учиться). Каждые 400 игр мы клонировали наиболее эффективного агента и выгнали некоторых из самых плохой. В конце концов мы просто сохранили лучший экземпляр каждого типа агента.
Результаты по всем играм:
| Агент | Игры сыграли | Средний балл | Выиграть дробь | Эло |
|---|---|---|---|---|
| Альфа0,5 | 2246 | -7.79 | 0,42 | 1806 |
| МСС | 2314 | -8.06 | 0,40 | 1745 |
| Застенчивый | 1408 | -12.28 | 0,18 | 1629 |
| D3QN | 1151 | -13.32 | 0,17 | 1577 |
| Случайный | 1382 | -13.49 | 0,19 | 1556 |
Так производительность (измеренная в ELO) моделей, разработанных в течение турнира:
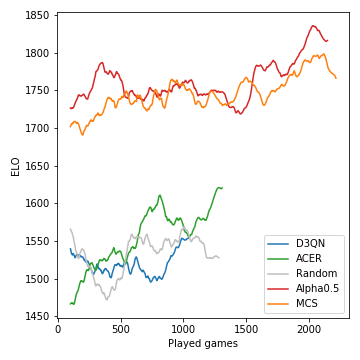
Поиск дерева Монте-Карло имеет решающее значение и приводит к сильным игрокам. С другой стороны, без модели RL-агенты изо всех сил пытаются даже явно превосходить случайную базовую линию. Из -за стохастического характера игры, вероятности победы и различия в Эло не так радикальны, как, скажем, для шахмат. Обратите внимание, что мы не настроили ни одного из многих гиперпараметров.
После этой фазы самостоятельной работы агент Alpha0.5 столкнулся с Merle, одним из лучших 6 Nimmt! Игроки в нашей группе друзей, для 5 игр. Это оценки:
| Игра | 1 | 2 | 3 | 4 | 5 | Сумма |
|---|---|---|---|---|---|---|
| Мерл | -10 | -16 | -11 | -3 | -4 | -44 |
| Альфа0,5 | -1 | -3 | -14 | -8 | -6 | -32 |
Предполагая, что у вас установлена Anaconda, клонировать репо
git clone [email protected]:johannbrehmer/rl-6nimmt.git
и создать виртуальную среду с
conda env create -f environment.yml
conda activate rl
Как самостоятельный игрок, так и игры между человеческим игроком и обученными агентами продемонстрированы в Simple_tournament.ipynb.
Собрано Иоганн Бремер и Марсель Гутсше.


