kubeai
helm-chart-models-0.9.0
Получите вывод, работая на Kubernetes: LLMS, Enterdings, Speech-Text.
✅ Замена замены OpenAI с совместимостью с API
⚖ масштаб от нуля, Autocale на основе нагрузки
? Подавайте модели генерации текста (LLMS, VLMS и т. Д.)
Речь к текстовым API
? Встроение/векторный API
Multi-Platform: только CPU, GPU, TPU
? Модель кэширования с общими файловыми системами (EFS, Filestore и т. Д.)
Нулевые зависимости (не зависят от Istio, Knative и т. Д.)
Пользовательский интерфейс (OpenWebui)
? Управляет модельными серверами OSS (VLLM, Ollama, PargeWhisper, Infinity)
✉ Вывод потока/партии с помощью интеграций обмена сообщениями (Kafka, Pubsub и т. Д.)
Цитаты из сообщества:
многоразовое, хорошо абстрактное решение для запуска LLMS - Mike Ensor
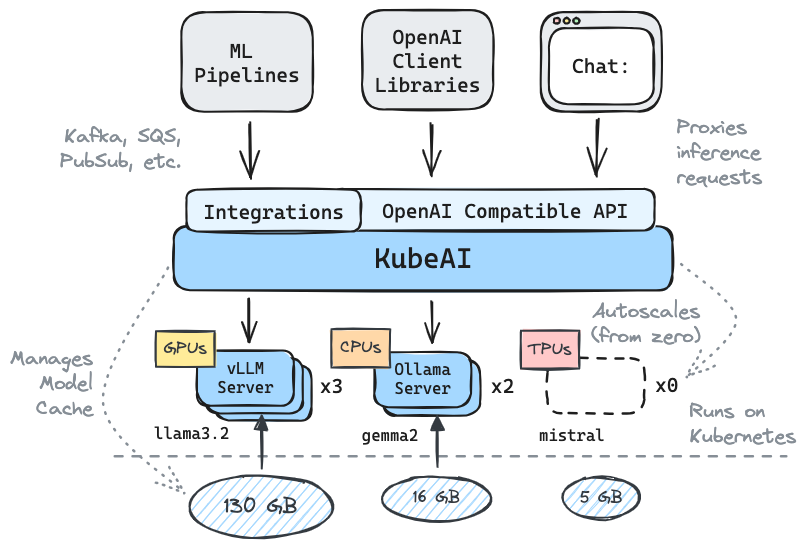
Kubeai обслуживает OpenAI, совместимый с HTTP API. Администраторы могут настроить модели ML с помощью kind: Model Kubernetes пользовательские ресурсы. Kubeai можно рассматривать как оператор модели (см. Оператор), который управляет серверами VLLM и Ollama.
Создайте локальный кластер, используя добрый или Minikube.
# You might need to stop and remove the existing machine:
podman machine stop
podman machine rm
# Init and start a new machine:
podman machine init --memory 6144 --disk-size 120
podman machine startkind create cluster # OR: minikube startДобавьте репозиторий Kubeai Helm.
helm repo add kubeai https://www.kubeai.org
helm repo updateУстановите Kubeai и подождите, пока все компоненты будут готовы (могут занять минуту).
helm install kubeai kubeai/kubeai --wait --timeout 10mУстановите несколько предопределенных моделей.
cat << EOF > kubeai-models.yaml
catalog:
gemma2-2b-cpu:
enabled: true
minReplicas: 1
qwen2-500m-cpu:
enabled: true
nomic-embed-text-cpu:
enabled: true
EOF
helm install kubeai-models kubeai/models
-f ./kubeai-models.yamlПрежде чем перейти к следующим шагам, запустите часы на стручках в автономном терминале, чтобы увидеть, как Kubeai развертывает модели.
kubectl get pods --watch Поскольку мы устанавливаем minReplicas: 1 для модели Gemma вы должны увидеть модель, уже появившись.
Начните локальный порт-первой, до встроенного чата пользовательского интерфейса.
kubectl port-forward svc/openwebui 8000:80Теперь откройте свой браузер для Localhost: 8000 и выберите модель Gemma, чтобы начать общаться.
Если вы вернетесь в браузер и начнете чат с QWEN2, вы заметите, что сначала потребуется время. Это связано с тем, что мы устанавливаем minReplicas: 0 для этой модели, и Kubeai необходимо раскрутить новый POD (вы можете проверить с помощью kubectl get models -oyaml qwen2-500m-cpu ).
Ознакомьтесь с нашей документацией на kubeai.org, чтобы найти информацию о:
Список известных усыновителей:
| Имя | Описание | Связь |
|---|---|---|
| Телескоп | Телескоп использует Kubeai для мультирегионного крупномасштабного вывода LLM. | tryteLescope.ai |
| Google Cloud Distributed Edge | Kubeai включен в качестве эталонной архитектуры для вывода на краю. | LinkedIn, Gitlab |
| Лямбда | Вы можете попробовать Kubeai в облаке разработчика Lambda AI. Смотрите учебник Lambda и видео. | Лямбда |
Если вы используете Kubeai и хотите, чтобы вас перечислили в качестве усыновителя, сделайте PR.
# Implemented #
/v1/chat/completions
/v1/completions
/v1/embeddings
/v1/models
/v1/audio/transcriptions
# Planned #
# /v1/assistants/*
# /v1/batches/*
# /v1/fine_tuning/*
# /v1/images/*
# /v1/vector_stores/* Примечание: Kubeai родился в результате проекта под названием Lingo, который был простым прокси Kubernetes LLM с базовым автоматическим масштабом. Мы перезапустили проект как Kubeai (конец 2024 года) и расширили дорожную карту до того, что он является сегодня.
? Не забудьте бросить нам звезду на GitHub и следить за репо, чтобы оставаться в курсе!
Дайте нам знать о функциях, которые вы заинтересованы в том, чтобы увидеть или обратиться с вопросами. Посетите наш канал Discord, чтобы присоединиться к обсуждению!
Или просто обратитесь на LinkedIn, если хотите подключиться:


