Reading_groups
1.0.0
Сила вычислений : многие доказательства показывают, что достижения в области машинного обучения в значительной степени обусловлены вычислениями, а не исследованиями, пожалуйста, обратитесь к «горькому уроку», и часто возникают явления появления и гомогенизации. Исследования показали, что использование вычислений искусственного интеллекта удваивается примерно каждые 3,4 месяца, в то время как повышение эффективности удваивается только каждые 16 месяцев. Среди них количество расчета в основном обусловлено вычислительной мощностью, в то время как эффективность обусловлена исследованиями. Это означает, что рост вычислений исторически доминировал в машинном обучении и его подполя. Это дополнительно доказано появлением GPT-4. Несмотря на это, нам все еще нужно обратить внимание на то, будет ли в будущем более подорванная архитектура, такая как S4. Большинство нынешних горячих точек NLP основаны на более продвинутом LLM (~ 100B,
Для получения дополнительных документов LLM, пожалуйста, обратитесь к здесь и здесь.
Документы ( грубая категория )
ресурс
【Тестирование на GPT-4, ограничение】 Спарки искусственного общего интеллекта: ранние эксперименты с GPT-4
【Инструкторы документов, включая SFT, PPO и т. Д., Одна из наиболее важных статей】 Модели обучения языковые модели для следования инструкциям с обратной связью человека
【Масштабируемый надзор: как люди могут продолжать улучшать свои модели после того, как их модели превышают свои собственные задачи? 】 Измерение прогресса по масштабируемому надзору за большими языковыми моделями
【Определение выравнивания, произведенное DeepMind】 Выравнивание языковых агентов
Общий помощник по языку в качестве лаборатории для выравнивания
[Ретро -бумага, модель, поиск с использованием CCA+] Улучшение языковых моделей путем извлечения из триллионов токенов
Чико настраивающие языковые модели от человеческих предпочтений
Обучение полезного и безвредного помощника по подкреплению обучения на отзыве человека
【Большая модель на китайском и английском языке, превышающая GPT-3】 GLM-130B: открытая двуязычная предварительно обученная модель
【Оптимизация целей предварительного обучения】 UL2: Объединяющие парадигмы обучения языку
【Новые критерии выравнивания, модельные библиотеки и новые методы】 - это обучение подкреплению (не) для обработки естественного языка?
【MLM без меток [Маски] с помощью технологии】 Дефицит представления в масках для моделирования языка
【Текст на обучение изображению. Отвечает на словарный запас нуждается и противостоит определенным атакам】 Языковое моделирование с пикселями
Lexmae: Lexicon-Bottlenecked Pretringaing для крупномасштабного поиска
Incoder: генеративная модель для заполнения и синтеза кода
[Поиск по текстовым изображениям для предварительной тренировки на языке]
Немонотоническая самопертимирующая языковая модель
【Сравнение и тонкая настройка негативной обратной связи с помощью дизайна Propt】 Цепочка задним числом выравнивает языковые модели с обратной связью
【Модель воробья】 Улучшение выравнивания диалоговых агентов через целевые человеческие суждения
[Используйте небольшие параметры модели, чтобы ускорить тренировочный процесс большой модели (не начиная с нуля)] Участие в растущих моделях для эффективного обучения трансформаторам
[Полупараметрическая модель слияния знаний Moe для множества источников знаний] Знание в контексте: к знающим полупараметрическим языковым моделям
[Метод слияния для слияния нескольких подготовленных моделей на разных наборах данных] Слияние знаний данных путем слияния весов языковых моделей
[Очень вдохновляет, что механизм поиска заменяет общую архитектуру FFN в трансформаторе (× 2,54 время), чтобы отделить знания, хранящиеся в модели модели]
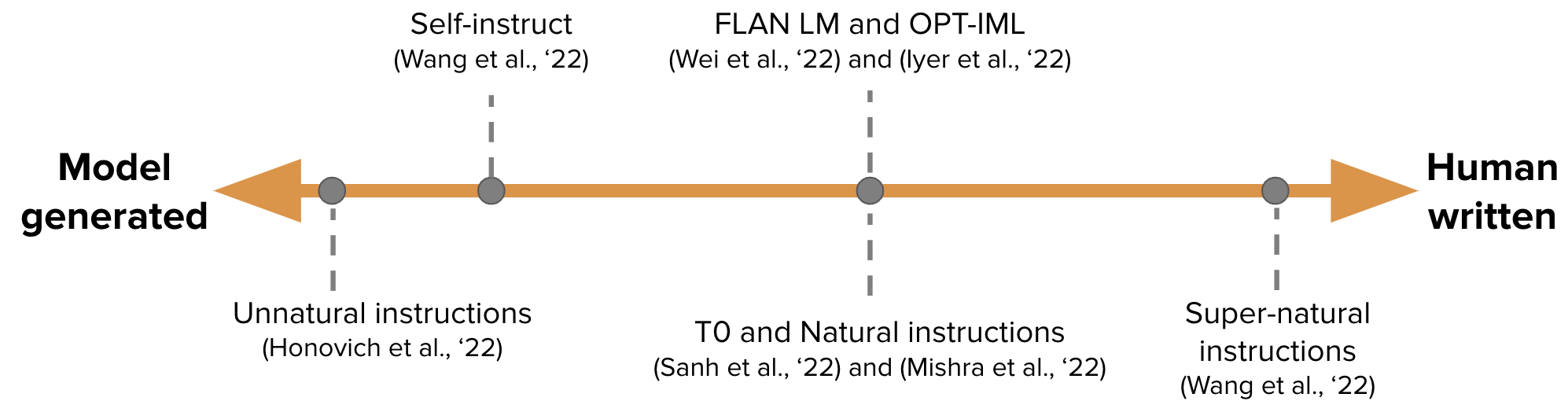
【Автоматическое генерирование данных настройки инструкций для обучения GPT-3】 Самоубийство: выравнивание языковой модели с самого сгенерированными инструкциями
- 
На пути к условно -зависимым моделям в масках
【Итеративно откалибровать несовершенно сгенерированные независимых корректоров, последующая статья Шона Веллека】 Генерация последовательностей, обучаясь самокорректировке
[Непрерывное обучение: добавьте PROPT для новой задачи, а ProPT предыдущей задачи и большая модель остаются неизменными] Прогрессивные подсказки: постоянное обучение для языковых моделей без забывания
[EMNLP 2022, Непрерывное обновление модели] MEMPROMPT: Редактирование приглашения с помощью памяти с отзывом пользователей
【Новая нейронная архитектура (фолнет), которая содержит логическую индукцию первого порядка.
Ganlm: предварительное обучение Encoder-Decoder с помощью вспомогательного дискриминатора
【Модель преривания языка на основе моделей пространства состояний, превышающая Bert】 предварительную подготовку без внимания
[Рассмотрим обратную связь человека во время предварительного обучения]
[Meta's Llama Model, 7B-65B, поезда, более меченные небольшие модели, чем обычно, достигая оптимальной эффективности в рамках различных бюджетов по выводу] Llama: открытые и эффективные языковые модели фундамента
[Обучение большим языковым моделям для самоотдачи и объяснения сгенерированного кода с помощью небольшого количества примеров, но они использовались сейчас, обучая большие языковые модели для самооборота
Как далеко могут зайти верблюды?
Лима: меньше для выравнивания
【Tree of Deful, все больше и больше похоже на альфаго】 преднамеренное решение проблем с большими языковыми моделями
【Метод многоэтапного рассуждения для применения ICL очень вдохновляет】 React: Синергирование рассуждений и действия в языковых моделях
【Cot непосредственно генерирует код программы, а затем позволяет Python Interpreter выполнять】 Программа мыслей, подсказывающая: отделение вычислений от рассуждений для численных задач рассуждения
[Большая модель непосредственно генерирует контекст доказательств], а не извлекать: большие языковые модели являются сильными контекстными генераторами
【Модель написания с 4 конкретными операциями】 Peer: модель совместной языка
【Сочетание Python, исполнителей SQL и больших моделей】 Связанные языковые модели на символических языках
[Получить код генерации документов] DOCPROMPTING: Сгенерирование кода, получая документы
[В следующей серии будет много статей в «Заземлении+LLM».
【Способность к самолете (подтверждено с использованием Python) Данные обучения】 Языковые модели могут научить себя лучше программировать лучше
Связанные статьи: Специализация меньших языковых моделей в направлении многоэтапных рассуждений
Звезда: рассуждения о начальной загрузке с рассуждениями, от Neurips 22 (генерируйте данные COT для модели точной настройки), что вызывает серию статей COT, обучающие небольшие модели.
Похожие идеи [дистилляция знаний] Учите модели мелких языков в разуме и обучении путем дистилляции контекста
Подобные идеи Kaist и Siang Ren Group
Модели [COT Data Data Trains Data Trains Decplosization и решающие проблемы по отдельности] дистилляция многоэтапных возможностей рассуждений крупных языковых моделей в более мелкие модели посредством семантических разложений
【Пусть небольшие модели изучают способности к кожу
【Большая модель Учите малую модельную кроватку】 Большие языковые модели рассуждают учителя
[Большая модель генерирует доказательства (чтение), а затем выполняет небольшую выборку с закрытой книгой и ответом]
[Методы индуктивных рассуждений естественного языка]
[GPT-3 используется для аннотации данных (например, эмоциональная классификация)] Является ли GPT-3 хорошим аннотатором данных?
【Модели для увеличения данных на основе многозадачности обучения для меньшего увеличения данных
【Процедурная работа по планированию, не заинтересованная в том, что это было нейро-символическое процедурное планирование с подсказкой здравого смысла
[Цель: генерируйте фактические правильные статьи для запросов, заземляя большой веб -корпус
【Сочетание результатов симулятора внешней физики в контексте】 Mind's Eye: обоснование модели на основе языка посредством симуляции
[Получите задачу улучшения котенок, чтобы сделать знания интенсивным] Интеррионет
【Сравните потенциальные (бинарные) знания в неконтролируемой модели языка распознавания】 Обнаружение скрытых знаний в языковых моделях без надзора
[Перси Лян Группа, доверенная поисковая система, только 51,5% сгенерированных предложений полностью поддерживаются цитатами] Оценка проверки в генеративных поисковых системах
Проблема прогрессивного хит-хинта улучшает рассуждения в крупных языковых моделях
Принцип самоуправление языковых моделей с нуля с минимальным человеческим надзором
Оценить LLM-как сужу
[На мой взгляд, это одна из самых важных статей. Обучение и ширина и глубина архитектуры, такие как ширина и глубина.
[Одна из других важных статей, шиншилла, в условиях ограниченных вычислений, оптимальная модель не является самой большой моделью, а меньшей моделью, обученной большим количеством данных (60-70b)] Обучение вычислительно-оптимальному крупному языку модели
[Какие цели архитектуры и оптимизации помогают обобщению с нулевой выборкой] Какая языковая модель архитектура и предварительная объективная работа лучше всего подходит для обобщения с нулевым выстрелом?
【Grokking «Epiphany» процесса обучения запоминание-> Формирование схемы-> Очистка】 Меры прогресса для грокинга посредством механистической интерпретации
[Изучите характеристики модели, основанной на поиске и обнаружите, что оба имеют ограниченную рассуждения] могут решить языковые модели?
[Оценка оценки взаимодействия с языком человека-ай
Какой алгоритм обучения в контексте?
【Модель Редактирование, это горячая тема】 Мяветь массового редактирования в трансформаторе
[Чувствительность модели к нерелевантному контексту, добавляя не относящуюся к делу информации в примеры в приглашении и добавление инструкций, которые игнорируют нерелевантный контекст, частично разрешают] Модели больших языков могут быть легко отвлечены с нерелевантным контекстом
【Ноль-выстрел покажет предвзятость и токсичность в соответствии с чувствительными проблемами】 На втором месте давайте не будем думать шаг за шагом!
【Компляция большой модели обладает межязычными возможностями】 Языковые модели-это многоязычная цепочка соображений
[Чем ниже путаница различных последовательностей быстрого приглашения, тем лучше
[Задача разрешения бинарности крупных моделей, это предложение затруднено, и нет явления масштабирования]. Большие языковые модели не являются нулевыми коммуникаторами (https://github.com/google/big-bench/tree/main/bigbench/ Bendmark_tasks/ Implicity)
【Пробуждение на основе сложности для многоэтапных рассуждений
Что имеет значение в структурированной обрезке моделей генеративных языков?
[Набор данных Ambibench, неоднозначность задачи: модель масштабирования RLHF работает лучше всего в устранении устранения задач. Тонкая настройка более полезна, чем несколько выстрелов.
【Тест GPT-3, включая память, калибровку, смещение и т. Д.】 Подает GPT-3 быть надежным
[Исследование OSU, какая часть COT эффективна для эффективности] для понимания подсказки о цепочке мыслей: эмпирическое исследование того, что имеет значение
[Исследование по межязычному модели дискретных подсказок] Может ли дискретная извлечение информации подсказывать обобщение между языковыми моделями?
【Скорость памяти - логарифмическая линейная связь с размером модели, длиной префикса и частотой повторения в обучении】 Количественная оценка запоминания в моделях нейронного языка
【Это очень вдохновляющее, разлагают проблему на подставки посредством итерации GPT и ответьте на нее】 Измерение и сужение пробела композиционности в языковых моделях
[Аналогичный тест GPT-3, аналогичный вопросам разведки государственных служащих].
【Краткое текстовое обучение, длинное текстовое тестирование, оценка адаптивности переменной модели】 Экстраполатируемый трансформатор длиной
[Когда не доверять языковым моделям: изучение эффективности и ограничений параметрических и непараметрических воспоминаний
【ICL-это еще одна форма обновления градиента】 Почему GPT может научиться в контексте?
GPT-3 психопат?
[Исследование процесса обучения модели OPT в разных размерах и показало, что путаница является показателем траекторий обучения ICL].
[EMNLP 2022, предварительно обученный чистый английский корпус содержит другие языки, а возможности межязывания модели могут исходить из утечки данных].
[Перепрофилирование семантических априоров и использование информации в Propt-это способность Surge].
【Результаты EMNLP 2022】 Какую языковую модель для обучения, если у вас есть один миллион графических часов?
[Представление технологии CFG во время рассуждений значительно улучшает способность малых моделей малых моделей].
【Обучите свою собственную модель ламы с GPT-4 OpenAI, и я могу только сказать, что восхищаюсь вами】 Настройка инструкции с GPT-4
Рефлексия: автономный агент с динамической памятью и саморефлексией
【Персонализированное быстрое обучение в стиле, Opt】 Расширяемые подсказки для языковых моделей
[Ускорение крупного модели декодирования, используя прямой консенсус между небольшими моделями и большими моделями, которые будут использоваться несколько раз за раз, в конце концов, вход будет очень медленным, если он будет длинный] ускорение крупного языкового декодирования со специализированной выборкой
[Используйте мягкую подсказку, чтобы уменьшить снижение возможностей ICL, вызванную тонкой настройкой, тонкой настройки на первом этапе, настраивая второй этап], сохраняя встроенные способности к обучению в модели с большой языком тонкой настройки
【Задачи семантического анализа, методы выбора выборки ICL, кодекс и T5-кар
【Новый метод оптимизации для генерации текста】 Модели создания языка на расстоянии общего расстояния
[Оценка неопределенности условной генерации с использованием семантической кластеризации в сочетании с множественными результатами выборки для оценки энтропии кластеров] Семантическая неопределенность: лингвистические инварианты для оценки неопределенности в генерации естественного языка
Настройка: улучшение нулевых способностей к обучению более мелких языковых моделей
【Очень вдохновляющий метод генерации текста в рамках свободного текста ограничения】 управляемое генерацию текста с языковыми ограничениями
[При генерации прогнозов используйте сходство для выбора фразы вместо токена SoftMax] Непараметрическое моделирование языка маскировки
[Метод ICL для длинного текста] Параллельный контекст Windows улучшает встроенное обучение крупных языковых моделей
【Образец инструктажа модели, генерирующей ICL сама по себе】 Самоубийственные модели больших языков для QA с открытым доменом
【Механизмы передачи и внимания позволяют ICL ввести больше образцов аннотаций】 Структурированное подсказка: масштабирование в контексте обучения до 1000 примеров
Калибровка импульса для генерации текста
【Два метода выбора образцов ICL, эксперименты на основе OPT и GPTJ】 Тщательное курирование данных стабилизирует в контексте обучения
【Анализ показателей оценки лилового (Pillutla et al.)】 О полезности встроений, кластеров и строк для оценки генерации текста
Rampeagator: несколько выстрелов из 8 примеров
[Три сапблера, Zhuge Liang] Самоустренность улучшает цепочку мышления в языковых моделях
[Инвертирование, вход и метка генерируют инструкции для условий] Угадайте инструкцию!
【LLM по обратному деривации.
【Методы поиска - сценарии безопасности в процессе создания доказательств】 Foveate, атрибут и рационализируйте: к безопасному и заслуживающему доверия ИИ
[Оценка достоверности фрагментов, извлеченных с помощью текстовой информации, основанной на поиске луча] Как поиск луча улучшает оценку доверия на уровне пролета при маркировке генеративной последовательности?
SPT: полупараметрическая настройка быстрого приглашения для многозадачности побуждает к обучению
【Обсуждение из извлеченной резюме Gold Label】 Текстовое обобщение с Oracle ожиданием
【Метод обнаружения OOD на основе марсианского расстояния】 Обнаружение выезда и селективное образование для моделей условного языка для моделей условного языка
[Внимательный модуль интегрирует подсказку для прогнозирования ансамбля на уровне выборки] Вместо быстрого слияния: метод передачи знаний, специфичный для образца, для настройки нескольких выстрелов для настройки быстрого выстрела
【Запрос для нескольких задач путем разложения и дистилляции в одну подсказку】 Многозадачная настройка приглашения обеспечивает параметры, эффективное переносное обучение
[Индикаторы оценки пошагового рассуждения, сгенерированного текста, можно использовать в качестве темы, чтобы поделиться в следующий раз] Roscoe: набор метрик для оценки пошаговых рассуждений
[Вероятность калибровки последовательности улучшает поколение условного языка]
【Метод текстовой атаки на основе оптимизации градиентов】 Textgrad: повышение оценки надежности в NLP с помощью градиентной оптимизации
[GMM моделирование границ классификации решений ICL для калибровки] Прототипическая калибровка для нескольких выстрелов в изучении языковых моделей
【Проблема переписывания и метод агрегирования ICL на основе графиков】 Спросите меня о чем угодно: простая стратегия для подсказки языковых моделей
[База данных для выбора хороших кандидатов в качестве ICL из нездоровых примеров Pools] Селективная аннотация делает языковые модели лучшими несколькими учащимися
Rimpleboosting: черная коробка классификация с десятью проходами
Забалодованные атаки с обращением внимания на трансформеры
【Заглавный маска автоматический выбор метки метки】 Предварительно обученные языковые модели могут быть полностью нулевыми учениками
[Сжатие длины входного вектора FID и переупорядочить его при выводе в рейтинг документов] FID-Light: эффективная и эффективная генерация текста с поиском-аугированным
【Объяснение о генерации больших моделей】 Pinto: верный язык
【Найдите подмножество воздействий перед тренировкой】 orca: интерпретация поощренных языковых моделей с помощью доказательств в океане в океане предварительной подготовки данных
[Основной проект, нацеленный на инструкции, генерирует первую стадию и двухэтапную фильтрацию сортировки] Модели больших языков-это инженеры на уровне человека
Отсутствие знаний для смягчения рисков конфиденциальности в языковых моделях
Редактирование моделей с помощью арифметики задачи
[Не вводите инструкции и образцы каждый раз, конвертируйте их в модули с параметрами,] Подсказка: настройка инструкций с гипернезой для эффективного обобщения с нулевым выстрелом
[Метод генерации дисплея ICL без ручного выбора образца] Z-ICL: Zero-Shot In-Context Learning с псевдо-демоинструкциями
[Инструкция по задании и текст сгенерируют внедрение] Один встроенный, любая задача: текстовые встроенные инструкции:
【Большая модель обучения маленькой модели Cot】 Нож: дистилляция знаний со свободным текстом-рациональными
[Проблема несоответствия между исходным и целевым сегментацией слова модели генерации извлечения информации]. Последовательность токенизации имеет значение для генеративных моделей на удаленных задачах NLP
Парсел: единая структура естественного языка для алгоритмических рассуждений
[Выбор образца ICL, выбор первого этапа и сортировка второй фазы] самоадаптивное обучение в контексте
[Интенсивное чтение, читаемый приглашенный метод отбора неконтролируемого отбора, GPT-2] к человеческому прочтению настройки быстрого настройки: «Сияние» Кубрика-хороший фильм, а тоже хорошая подсказка тоже
【Проверка наборов данных Prontoqa. Способность к выводу вывода и обнаруживает, что способность планирования все еще ограничена】 языковые модели могут (что-то вроде). Причина: систематический формальный анализ цепочки цепочки мыслей
【Набор данных рассуждения】 WikiWhy: Ответ и объяснение причинно-следственных вопросов
【Набор данных рассуждений】 Улица: многозадачный структурированное рассуждение и объяснение
【Набор данных о расчетах, сравнивая предварительную тренировку OPT и тонкую настройку, включая модели с тонкой настройкой кровью】】 Предупреждение: адаптация языковых моделей к задачам рассуждений
[Сводка недавних рассуждений команды Чжан Нингю из Университета Чжэцзян] Рассказывание с подсказкой на языковой модели: опрос
[Сводка технологий генерации текста и направления команды Сяо Янхуа в Фудане] Используя знания и рассуждения для генерации естественного языка, подобного человеку: краткий обзор
[Сводка недавних статей по рассуждениям, Цзе Хуанг из UIUC] к рассуждениям в крупных языковых моделях: опрос
【Обзор задач, наборов данных и методов математических рассуждений и DL】 Обзор глубокого обучения для математических рассуждений
Обследование обработки естественного языка для программирования
Набор данных моделирования вознаграждения:
Red-teaming数据集,harmless vs. helpful, RLHF +scale更难被攻击(另一个有效的技术是CoT fine-tuning):
【知识】+【推理】+【生成】
如果对您有帮助,请star支持一下,欢迎Pull Request~
主观整理,时间上主要从ICLR 2023 Rebuttal期间开始的,包括ICLR,ACL,ICML等预印版论文。
不妥之处或者建议请指正! Dongfang Li, [email protected]


