dalle flow
1.0.0


Человек в петле ? Рабочий процесс для создания HD -изображений из текста
Dall · E Flow-это интерактивный рабочий процесс для генерации изображений высокой четкости из текстовой подсказки. Во-первых, он использует Dall · E-Mega, Glid-3 XL и стабильную диффузию для генерации кандидатов на изображение, а затем вызывает клип-сервис, чтобы оценить кандидатов в подсказке. Предпочтительный кандидат питается Glid-3 XL для диффузии, которая часто обогащает текстуру и фон. Наконец, кандидат увеличивается до 1024x1024 через Swinir.
Dall · E Flow построен с Jina в архитектуре клиентского сервера, которая дает ему высокую масштабируемость, не блокирующую потоковую передачу и современный питонический интерфейс. Клиент может взаимодействовать с сервером через GRPC/WebSocket/HTTP с TLS.
Почему человек в петле? Генеративное искусство - это творческий процесс. В то время как недавние достижения Dall · e выпустят творчество людей, наличие единого проплемента-выпуска UX/UI блокирует воображение до одной возможности, что плохо, независимо от того, насколько хорош этот единственный результат. Dall · E Flow является альтернативой одностроительству, путем формализации генеративного искусства в качестве итерационной процедуры.
Dall · E Flow находится в архитектуре клиентского сервера.
grpcs://api.clip.jina.ai:2096 (требует jina >= v3.11.0 ), вам нужно сначала получить токен доступа отсюда. См. Используйте клип как сервис для получения более подробной информации.flow_parser.py .grpcs://dalle-flow.dev.jina.ai . Все подключения сейчас с шифрованием TLS, пожалуйста, откройте ноутбук в Google Colab.p2.x8large .ViT-L/14@336px от клипа-сервиса, steps 100->200 .















































Использование клиента очень просто. Следующие шаги лучше всего выполнять в ноутбуке Юпитера или в Google Colab.
Вам нужно сначала установить Docarray и Jina:
pip install " docarray[common]>=0.13.5 " jinaМы предоставили демо -сервер для вас, чтобы играть:
️ Из -за массовых запросов наш сервер может быть задержкой в ответ. Тем не менее, мы очень уверены в том, чтобы поддерживать высокое время. Вы также можете развернуть свой собственный сервер, следуя инструкции здесь.
server_url = 'grpcs://dalle-flow.dev.jina.ai'Теперь давайте определим подсказку:
prompt = 'an oil painting of a humanoid robot playing chess in the style of Matisse'Давайте отправим его на сервер и визуализируем результаты:
from docarray import Document
doc = Document ( text = prompt ). post ( server_url , parameters = { 'num_images' : 8 })
da = doc . matches
da . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Здесь мы генерируем 24 кандидата, 8 из Dalle-Mega, 8 от Glid3 XL и 8 из стабильной диффузии, это определено в num_images , что занимает около 2 минут. Вы можете использовать меньшее значение, если оно слишком длинное для вас.

24 кандидата отсортированы по клипсу как услугу, с индексом 0 в качестве лучшего кандидата, оцениваемого по клипу. Конечно, вы можете думать по -другому. Обратите внимание на номер в верхнем левом углу? Выберите тот, который вам нравится больше всего и получите лучший вид:
fav_id = 3
fav = da [ fav_id ]
fav . embedding = doc . embedding
fav . display ()
Теперь давайте отправим выбранных кандидатов на сервер для распространения.
diffused = fav . post ( f' { server_url } ' , parameters = { 'skip_rate' : 0.5 , 'num_images' : 36 }, target_executor = 'diffusion' ). matches
diffused . plot_image_sprites ( fig_size = ( 10 , 10 ), show_index = True ) Это даст 36 изображений на основе выбранного изображения. Вы можете позволить модели больше импровизировать, давая skip_rate почти нулевое значение или почти одно значение, чтобы привести к своему близости к данному изображению. Вся процедура занимает около 2 минут.

Выберите изображение, которое вам нравится больше всего, и приведите его поближе:
dfav_id = 34
fav = diffused [ dfav_id ]
fav . display ()
Наконец, отправьте на сервер для последнего шага: увеличение до 1024 x 1024px.
fav = fav . post ( f' { server_url } /upscale' )
fav . display ()Вот и все! Это один . Если не удовлетворен, повторите процедуру.

Кстати, Docarray-это мощная и простая в использовании структуру данных для неструктурированных данных. Это супер продуктивно для ученых данных, которые работают в кросс-/мультимодальной области. Чтобы узнать больше о Docarray, пожалуйста, ознакомьтесь с документами.
Вы можете разместить свой собственный сервер, следуя инструкции ниже.
Поток Dall · E нуждается в одном GPU с 21 ГБ VRAM на пике. Все услуги втиснуты в этот графический процессор, это включает (примерно)
config.yml , 512x512)Следующие разумные трюки могут быть использованы для дальнейшего сокращения VRAM:
Это требует не менее 50 ГБ свободного места на жестком диске, в основном для загрузки предварительных моделей.
Требуется высокоскоростный интернет. Медленный/нестабильный интернет может выбросить время -аут при загрузке моделей.
Среда только для процессора не тестируется и, вероятно, не будет работать. Google Colab, вероятно, бросает OOM, следовательно, также не будет работать.

Если вы установили JINA, вышеупомянутая блок -схема может быть сгенерирована через:
# pip install jina
jina export flowchart flow.yml flow.svgЕсли вы хотите использовать стабильную диффузию, вам сначала нужно будет зарегистрировать учетную запись на веб -сайте HuggingFace и согласиться с условиями для модели. После входа в систему вы можете найти версию модели, необходимой здесь:
Compvis / sd-v1-5-inpainting.ckpt
В разделе «Загрузить вес» нажмите на ссылку для sd-v1-x.ckpt . Последние веса на момент письма являются sd-v1-5.ckpt .
Пользователи Docker : поместите этот файл в папку с именем ldm/stable-diffusion-v1 и переименовать его model.ckpt . Следуйте приведенным ниже инструкциям, потому что SD не включен по умолчанию.
Нативные пользователи : поместите этот файл в dalle/stable-diffusion/models/ldm/stable-diffusion-v1/model.ckpt после завершения остальных шагов в разделе «Запуск национально». Следуйте приведенным ниже инструкциям, потому что SD не включен по умолчанию.
Мы предоставили предварительно построенное изображение Docker, которое можно напрямую.
docker pull jinaai/dalle-flow:latestМы предоставили DockerFile, который позволяет запускать сервер из коробки.
Наш DockerFile использует CUDA 11.6 в качестве базового изображения, вы можете настроить его в соответствии с вашей системой.
git clone https://github.com/jina-ai/dalle-flow.git
cd dalle-flow
docker build --build-arg GROUP_ID= $( id -g ${USER} ) --build-arg USER_ID= $( id -u ${USER} ) -t jinaai/dalle-flow .Здание займет 10 минут со средней скоростью в Интернете, что приведет к изображению докера 18 ГБ.
Чтобы запустить его, просто сделайте:
docker run -p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowВ качестве альтернативы, вы также можете запустить с некоторыми рабочими процессами, включенными или отключенными для предотвращения сбоев вне памяти. Для этого пройдите одну из этих переменных среды:
DISABLE_DALLE_MEGA
DISABLE_GLID3XL
DISABLE_SWINIR
ENABLE_STABLE_DIFFUSION
ENABLE_CLIPSEG
ENABLE_REALESRGAN
Например, если вы хотите отключить рабочие процессы Glid3xl, запустите:
docker run -e DISABLE_GLID3XL= ' 1 '
-p 51005:51005
-it
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flow-v $HOME/.cache:/root/.cache избегает повторяющейся загрузки модели при каждом запуска Docker.-p 51005:51005 -ваш общедоступный порт. Убедитесь, что люди могут получить доступ к этому порту, если вы служите публично. Второй партии - это порт, определенный в Flow.yml.ENABLE_STABLE_DIFFUSION .ENABLE_CLIPSEG .ENABLE_REALESRGAN . Стабильная диффузия может быть включена только в том случае, если вы загрузили веса и сделаете их доступными в виде виртуального громкости при включении экологического флага ( ENABLE_STABLE_DIFFUSION ) для SD .
Вы должны были ранее поместить веса в папку с именем ldm/stable-diffusion-v1 и маркировали их model.ckpt . Замените YOUR_MODEL_PATH/ldm ниже на пути в вашей собственной системе, чтобы поднять веса в изображение Docker.
docker run -e ENABLE_STABLE_DIFFUSION= " 1 "
-e DISABLE_DALLE_MEGA= " 1 "
-e DISABLE_GLID3XL= " 1 "
-p 51005:51005
-it
-v YOUR_MODEL_PATH/ldm:/dalle/stable-diffusion/models/ldm/
-v $HOME /.cache:/home/dalle/.cache
--gpus all
jinaai/dalle-flowВы должны увидеть экран, как после запуска:
Обратите внимание, что, в отличие от бега, бег внутри Docker может дать менее яркий ProgressBar, цветные журналы и отпечатки. Это связано с ограничениями терминала в контейнере Docker. Это не влияет на фактическое использование.
Запуск изначально требует некоторых ручных шагов, но часто его легче отладить.
mkdir dalle && cd dalle
git clone https://github.com/jina-ai/dalle-flow.git
git clone https://github.com/jina-ai/SwinIR.git
git clone --branch v0.0.15 https://github.com/AmericanPresidentJimmyCarter/stable-diffusion.git
git clone https://github.com/CompVis/latent-diffusion.git
git clone https://github.com/jina-ai/glid-3-xl.git
git clone https://github.com/timojl/clipseg.gitУ вас должна быть следующая структура папок:
dalle/
|
|-- Real-ESRGAN/
|-- SwinIR/
|-- clipseg/
|-- dalle-flow/
|-- glid-3-xl/
|-- latent-diffusion/
|-- stable-diffusion/
cd dalle-flow
python3 -m virtualenv env
source env/bin/activate && cd -
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pip install numpy tqdm pytorch_lightning einops numpy omegaconf
pip install https://github.com/crowsonkb/k-diffusion/archive/master.zip
pip install git+https://github.com/AmericanPresidentJimmyCarter/[email protected]
pip install basicsr facexlib gfpgan
pip install realesrgan
pip install https://github.com/AmericanPresidentJimmyCarter/xformers-builds/raw/master/cu116/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl &&
cd latent-diffusion && pip install -e . && cd -
cd stable-diffusion && pip install -e . && cd -
cd SwinIR && pip install -e . && cd -
cd glid-3-xl && pip install -e . && cd -
cd clipseg && pip install -e . && cd -Есть пара моделей, которые нам нужно загрузить для Glid-3-XL, если вы используете это:
cd glid-3-xl
wget https://dall-3.com/models/glid-3-xl/bert.pt
wget https://dall-3.com/models/glid-3-xl/kl-f8.pt
wget https://dall-3.com/models/glid-3-xl/finetune.pt
cd - И clipseg , и RealESRGAN требуют, чтобы вы установили правильный путь папки кеша, обычно что -то вроде $ home/.
cd dalle-flow
pip install -r requirements.txt
pip install jax~=0.3.24 Теперь вы находитесь под dalle-flow/ , запустите следующую команду:
# Optionally disable some generative models with the following flags when
# using flow_parser.py:
# --disable-dalle-mega
# --disable-glid3xl
# --disable-swinir
# --enable-stable-diffusion
python flow_parser.py
jina flow --uses flow.tmp.ymlВы должны немедленно увидеть этот экран:

При первом старте потребуется ~ 8 минут для загрузки Dall · E Mega Model и других необходимых моделей. Работа запуска должно занять всего ~ 1 минуту, чтобы достичь сообщения успеха.
Когда все будет готово, вы увидите:
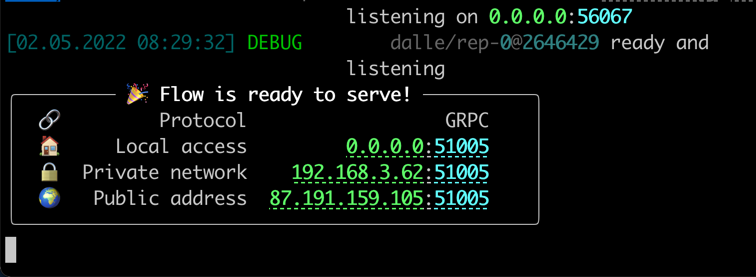
Поздравляю! Теперь вы должны иметь возможность запустить клиента.
Вы можете изменить и расширить поток сервера, как вам нравится, например, изменяя модель, добавляя постоянство или даже авто-публикацию в Instagram/Opensea. С Jina и Docarray вы можете легко сделать Dall · E Flow Cloud Contination и готовым к производству.
Чтобы уменьшить использование VRAM, вы можете использовать CLIP-as-service в качестве внешнего исполнителя, свободно доступного по grpcs://api.clip.jina.ai:2096 .
Во -первых, убедитесь, что вы создали токен доступа с веб -сайта Console или CLI в следующем
jina auth token create < name of PAT > -e < expiration days > Затем вам необходимо изменить конфигурации, связанные с исполнителем ( host , port , external , tls и grpc_metadata ) с flow.yml .
...
- name : clip_encoder
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [gateway]
...
- name : rerank
uses : jinahub+docker://CLIPTorchEncoder/latest-gpu
host : ' api.clip.jina.ai '
port : 2096
uses_requests :
' / ' : rank
tls : true
external : true
grpc_metadata :
authorization : " <your access token> "
needs : [dalle, diffusion] Вы также можете использовать flow_parser.py для автоматического генерации и запуска потока с использованием CLIP-as-service в качестве внешнего исполнителя:
python flow_parser.py --cas-token " <your access token>'
jina flow --uses flow.tmp.yml
️ grpc_metadataдоступна только после Jinav3.11.0. Если вы используете более старую версию, пожалуйста, обновите до последней версии.
Теперь вы можете использовать бесплатный CLIP-as-service в своем потоке.
Dall · E Flow поддерживается Jina AI и лицензируется в соответствии с Apache-2.0. Мы активно нанимаем инженеров ИИ, инженеров из решений для создания следующей нейронной поисковой экосистемы в открытом исходном коде.


