GPTCache
v0.1.44
Сбросьте свой API LLM в 10 раз?, Ускорение скорости в 100x ⚡
? GPTCache был полностью интегрирован? ️ Langchain! Вот подробные инструкции по использованию.
? Было выпущено изображение Docker Docker GPTCache Server, что означает, что любой язык сможет использовать GPTCache!
? Этот проект подвергается быстрому развитию, и, как таковой, API может быть изменен в любое время. Для получения наиболее актуальной информации, пожалуйста, обратитесь к последней документации и выпуску.
Примечание. Поскольку количество больших моделей растет взрывоопасно, а их форма API постоянно развивается, мы больше не добавляем поддержки для новых API или моделей. Мы поощряем использование API Get и Set в GPTCache, вот демонстрационный код: https://github.com/zilliztech/gptcache/blob/main/examples/adapter/api.py
pip install gptcache
CHATGPT и различные крупные языковые модели (LLMS) имеют невероятную универсальность, что позволяет разработать широкий спектр приложений. Однако по мере того, как ваше приложение растет в популярности и сталкивается с более высокими уровнями трафика, расходы, связанные с вызовами API LLM, могут стать существенными. Кроме того, услуги LLM могут демонстрировать медленное время отклика, особенно при работе со значительным количеством запросов.
Чтобы решить эту проблему, мы создали GPTCache, проект, посвященный созданию семантического кеша для хранения ответов LLM.
Примечание :
python --versionpython -m pip install --upgrade pip . # clone GPTCache repo
git clone -b dev https://github.com/zilliztech/GPTCache.git
cd GPTCache
# install the repo
pip install -r requirements.txt
python setup.py installЭти примеры помогут вам понять, как использовать точное и похожее сопоставление с кэшированием. Вы также можете запустить пример на Colab. И больше примеров вы можете обратиться к Bootcamp
Прежде чем запустить пример, убедитесь, что переменная среды openai_api_key установлена путем выполнения echo $OPENAI_API_KEY .
Если он еще не установлен, его можно установить с помощью export OPENAI_API_KEY=YOUR_API_KEY on unix/linux/macos systems или set OPENAI_API_KEY=YOUR_API_KEY в системах Windows.
Важно отметить, что этот метод эффективен только временно, поэтому, если вы хотите постоянный эффект, вам необходимо изменить файл конфигурации переменной среды. Например, на Mac вы можете изменить файл, расположенный по адресу
/etc/profile.
import os
import time
import openai
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
question = 'what‘s chatgpt'
# OpenAI API original usage
openai . api_key = os . getenv ( "OPENAI_API_KEY" )
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Если вы задаете CHATGPT то же самое два вопроса, ответ на второй вопрос будет получен из кэша, не запрашивая CHATGPT снова.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
print ( "Cache loading....." )
# To use GPTCache, that's all you need
# -------------------------------------------------
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()
# -------------------------------------------------
question = "what's github"
for _ in range ( 2 ):
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )После получения ответа от Chatgpt в ответ на несколько подобных вопросов ответы на последующие вопросы могут быть извлечены из кэша без необходимости снова запросить CHATGPT.
import time
def response_text ( openai_resp ):
return openai_resp [ 'choices' ][ 0 ][ 'message' ][ 'content' ]
from gptcache import cache
from gptcache . adapter import openai
from gptcache . embedding import Onnx
from gptcache . manager import CacheBase , VectorBase , get_data_manager
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
print ( "Cache loading....." )
onnx = Onnx ()
data_manager = get_data_manager ( CacheBase ( "sqlite" ), VectorBase ( "faiss" , dimension = onnx . dimension ))
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
)
cache . set_openai_key ()
questions = [
"what's github" ,
"can you explain what GitHub is" ,
"can you tell me more about GitHub" ,
"what is the purpose of GitHub"
]
for question in questions :
start_time = time . time ()
response = openai . ChatCompletion . create (
model = 'gpt-3.5-turbo' ,
messages = [
{
'role' : 'user' ,
'content' : question
}
],
)
print ( f'Question: { question } ' )
print ( "Time consuming: {:.2f}s" . format ( time . time () - start_time ))
print ( f'Answer: { response_text ( response ) } n ' )Вы всегда можете передать параметр температуры, запрашивая услугу или модель API.
Диапазон
temperatureсоставляет [0, 2], значение по умолчанию составляет 0,0.Более высокая температура означает более высокую вероятность пропуска поиска и запроса на большую модель напрямую. Когда температура составляет 2, он будет наверняка пропустить кэш и отправлять запрос на большую модель. Когда температура равен 0, он будет искать кэш, прежде чем запрашивать большую модельную службу.
По умолчанию
post_process_messages_func- этоtemperature_softmax. В этом случае обратитесь к ссылке API, чтобы узнать, какtemperatureвлияет на выход.
import time
from gptcache import cache , Config
from gptcache . manager import manager_factory
from gptcache . embedding import Onnx
from gptcache . processor . post import temperature_softmax
from gptcache . similarity_evaluation . distance import SearchDistanceEvaluation
from gptcache . adapter import openai
cache . set_openai_key ()
onnx = Onnx ()
data_manager = manager_factory ( "sqlite,faiss" , vector_params = { "dimension" : onnx . dimension })
cache . init (
embedding_func = onnx . to_embeddings ,
data_manager = data_manager ,
similarity_evaluation = SearchDistanceEvaluation (),
post_process_messages_func = temperature_softmax
)
# cache.config = Config(similarity_threshold=0.2)
question = "what's github"
for _ in range ( 3 ):
start = time . time ()
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
temperature = 1.0 , # Change temperature here
messages = [{
"role" : "user" ,
"content" : question
}],
)
print ( "Time elapsed:" , round ( time . time () - start , 3 ))
print ( "Answer:" , response [ "choices" ][ 0 ][ "message" ][ "content" ])Чтобы использовать GPTCache исключительно, требуются только следующие строки кода, и нет необходимости изменять какой -либо существующий код.
from gptcache import cache
from gptcache . adapter import openai
cache . init ()
cache . set_openai_key ()Больше документов:
GPTCache предлагает следующие основные преимущества:
Онлайн -сервисы часто демонстрируют местонахождение данных, когда пользователи часто получают доступ к популярному или трендовому контенту. Кэш -системы используют это поведение, сохраняя широко доступные данные, что, в свою очередь, сокращает время поиска данных, улучшает время отклика и облегчает бремя на серверах бэкэнд. Традиционные системы кэша обычно используют точное совпадение между новым запросом и кэшированным запросом, чтобы определить, доступен ли запрашиваемый контент в кэше перед получением данных.
Тем не менее, использование точного подхода к совпадению для кэша LLM менее эффективно из -за сложности и изменчивости запросов LLM, что приводит к низкой скорости попадания в кэш. Чтобы решить эту проблему, GPTCache принимает альтернативные стратегии, такие как семантическое кэширование. Семантическое кэширование идентифицирует и хранит сходные или связанные запросы, тем самым увеличивая вероятность попадания кэша и повышая общую эффективность кэширования.
GPTCache использует алгоритмы встраивания для преобразования запросов в встраиваемые встроения и использует векторный хранилище для поиска сходства на этих вставках. Этот процесс позволяет GPTCache идентифицировать и извлекать аналогичные или связанные запросы из хранилища кэша, как показано в разделе модулей.
Представляя модульный дизайн, GPTCache позволяет пользователям легко настраивать свой собственный семантический кеш. Система предлагает различные реализации для каждого модуля, и пользователи могут даже разработать свои собственные реализации в соответствии с их конкретными потребностями.
В семантическом кэше вы можете столкнуться с ложными положительными, во время хитов в кешах и ложных негативных препаратов во время промахи кэша. GPTCache предлагает три показателя для оценки его производительности, которые полезны для разработчиков, чтобы оптимизировать свои системы кэширования:
Для пользователей включен образец, чтобы начать с оценки производительности их семантического кеша.
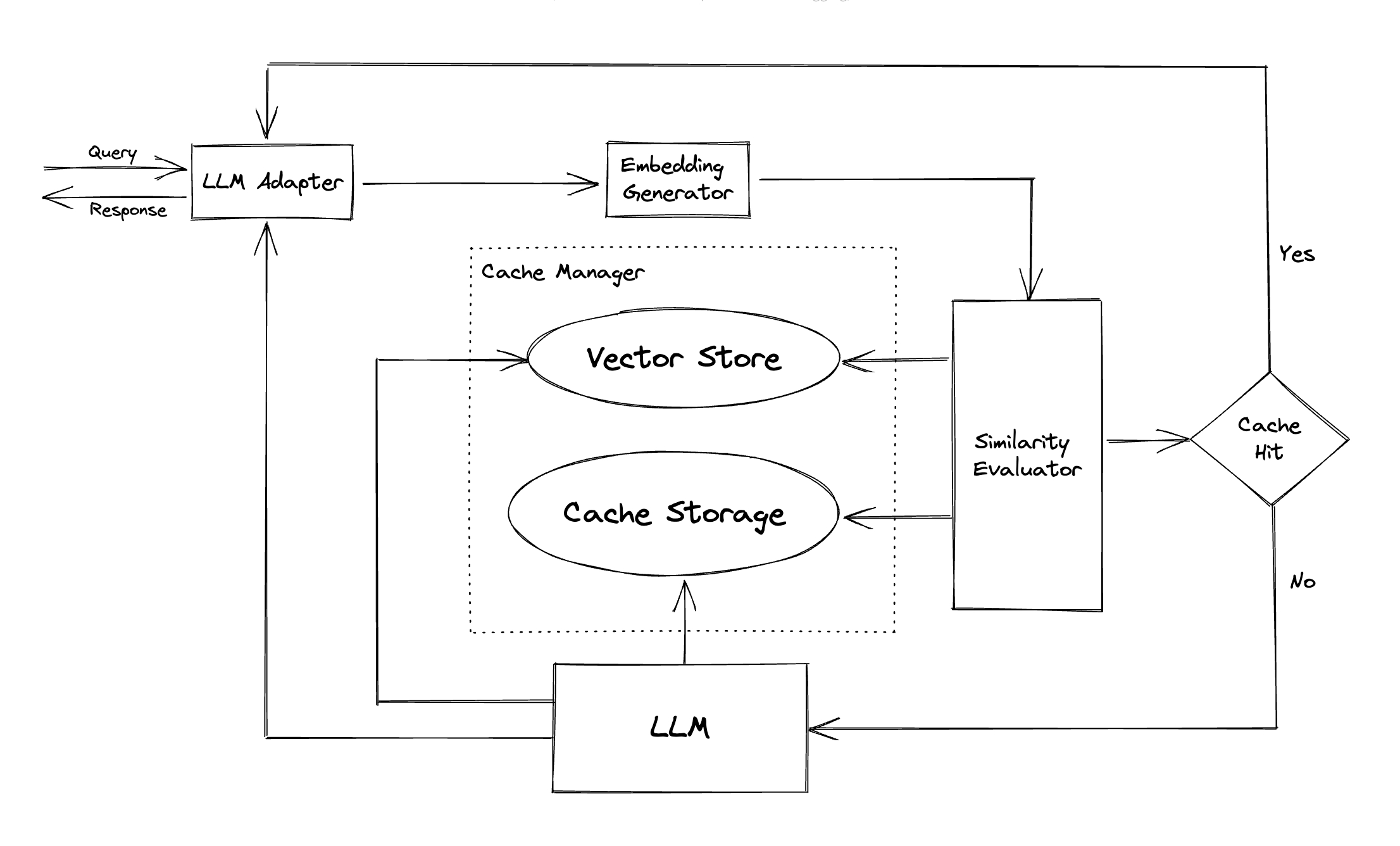
Адаптер LLM : адаптер LLM предназначен для интеграции различных моделей LLM путем объединения их API и протоколов запроса. GPTCache предлагает стандартизированный интерфейс для этой цели с текущей поддержкой интеграции CHATGPT.
Мультимодальный адаптер (экспериментальный) : мультимодальный адаптер предназначен для интеграции различных крупных мультимодальных моделей путем объединения их API и протоколов запроса. GPTCache предлагает стандартизированный интерфейс для этой цели с текущей поддержкой интеграции генерации изображений, аудио транскрипции.
Встроенный генератор : этот модуль создан для извлечения внедрения из запросов на поиск сходства. GPTCache предлагает общий интерфейс, который поддерживает множество API -интерфейсов, и представляет ряд решений на выбор.
Хранение кеша : хранилище кэша - это то, где хранится ответ от LLM, такой как CHATGPT. Получены кэшированные ответы, чтобы помочь в оценке сходства и возвращаются запрашиванию, если есть хороший семантический матч. В настоящее время GPTCache поддерживает SQLite и предлагает универсально доступный интерфейс для расширения этого модуля.
Vector Store : модуль векторного хранилища помогает найти k наиболее похожие запросы из извлеченного внедрения запроса входного запроса. Результаты могут помочь оценить сходство. GPTCache предоставляет удобный интерфейс, который поддерживает различные векторные магазины, включая Milvus, Zilliz Cloud и Faiss. Больше вариантов будет доступно в будущем.
Cache Manager : Cache Manager отвечает за управление работой как хранилища кэша , так и векторного хранилища .
cachetools Python или распределенным образом, используя Redis в качестве магазина ключей.В настоящее время GPTCache принимает решения о выселениях, основанных исключительно на количестве строк. Этот подход может привести к неточной оценке ресурсов и может вызвать ошибки вне памяти (OOM). Мы активно исследуем и разрабатываем более сложную стратегию.
Если вы должны были масштабировать свое развертывание GPTCache горизонтально с использованием кэширования в памяти, это не будет возможно. Поскольку кэшированная информация будет ограничена отдельной стручкой.
С распределенным кэшированием информация о кэше, согласованная во всех репликах, мы можем использовать распределенные кеш -магазины, такие как Redis.
Оценка сходства : этот модуль собирает данные как из хранилища кэша , так и в хранилище вектора и использует различные стратегии для определения сходства между входным запросом и запросами из векторного хранилища . Основываясь на этом сходстве, он определяет, соответствует ли запрос кэш. GPTCache предоставляет стандартизированный интерфейс для интеграции различных стратегий, а также набор реализаций для использования. Следующие определения сходства в настоящее время поддерживаются или будут поддерживаться в будущем:
Примечание . Не все комбинации разных модулей могут быть совместимы друг с другом. Например, если мы отключим экстрактор встраивания , векторный хранилище может не функционировать, как предполагалось. В настоящее время мы работаем над реализацией комбинированной проверки здравомыслия для GPTCache .
Вскоре! Следите за обновлениями!
Мы чрезвычайно открыты для вкладов, будь то с помощью новых функций, улучшенной инфраструктуры или улучшенной документации.
Для получения комплексных инструкций о том, как внести свой вклад, обратитесь к нашему руководству по взносу.


