Интерактивный помощник на основе голоса, оснащенный различными синтетическими голосами (включая голос Джарвиса от Ironman)
Изображение от Midjourney AI
Вы когда-нибудь мечтали попросить гипертерешеткие советы системы, чтобы улучшить свою броню? Теперь вы можете! Ну, может быть, не та доспехи ... этот проект эксплуатирует Wepperai Whisper, Openai Catgpt и IBM Watson.
Мотивация проекта:
Много раз идеи приходят в худший момент, и они исчезают, прежде чем у вас будет время, чтобы лучше их исследовать. Цель этого проекта-разработать систему, способную давать советы и мнения в квази-реальном времени обо всем, что вы спрашиваете. Полученный помощник сможет получить доступ от любого авторизованного микрофона внутри вашего дома или вашего телефона, он должен постоянно работать в фоновом режиме, и когда вызван, должен иметь возможность генерировать значимые ответы (с помощью крутого голоса), а также интерфейс с ПК или сервером и сохранять/читать/записать файлы, которые можно получить позже. Он должен иметь возможность запускать исследования, собирать материал из Интернета (извлечь контент с HTML -страниц, транскрибировать видео на YouTube, найти научные статьи ...) и предоставить резюме, которые можно использовать в качестве контекста для принятия обоснованных решений. Кроме того, он может взаимодействовать с некоторыми внешними гаджетами (IoT), но это дополнительное.
Демонстрация:
2023-04-11.23-20-03_trim.mp4
14 июля 2023 г. Обновление: режим исследования
Я могу поделиться первым проектом режима исследования. Этот метод думал о людях, которые часто имеют дело с исследовательскими работами.
Переключиться в режим исследования, сказав «переключиться на режим исследования»
Инициализируйте новое рабочее пространство, подобное этим: «Инициализируйте новое рабочее пространство о приложениях углеродного волокна в индустрии космических кораблей» . Рабочая область - это папка, которая собирает и организует результаты исследования. Этот протокол подразделяется на 3 подкзадата:
Основная идентификация бумаги: используйте API семантического ученых, чтобы определить некоторые сильно релевантные статьи;
Расширение ядра: для каждой статьи находит некоторые предложения, а затем сохраняют только те предложения, которые, по -видимому, похожи как минимум 2 бумаги;
Расшипное расширение: используйте пакет Refy Predition, чтобы увеличить результаты;
Найдите предложения, такие как: «Найдите предложения, которые являются силилярными для бумаги с заголовком ...»
Скачать: 'Скачать бумагу с заголовком ...'
Запросите вашу базу данных: «Что является автором газеты с заголовком ...?»«Каковы экспериментальные условия для бумаги с заголовком ...?»
PS: этот режим не очень стабилен и должен работать над
PPS: Этот проект будет прекращен в течение некоторого времени, так как я буду работать над своей диссертацией до 2024 года. Однако уже есть так много вещей, которые можно улучшить, поэтому я вернусь!
Что вам понадобится:
Отказ от ответственности: Проект может поглотить ваш кредит Openai, что приведет к нежелательному выставлению счетов; Я не беру на себя ответственность за какие -либо нежелательные обвинения; Рассмотрите возможность установления ограничений на потребление кредита на вашей учетной записи Openai;
Аккаунт OpenAI и ключ API; (Проверьте часто задаваемые вопросы ниже для альтернатив)
Учетная запись Picovoice и бесплатный доступ; (необязательный)
Учетная запись ElevenLabs и бесплатный ключ API (необязательно) ;
Ключи API Langchain для веб-серфинга (новости, погода, Serpapi, Google-Serp, Google-поиск ... все они бесплатны)
ffmpeg;
Виртуальная среда Python (Python> = 3,9 и <3.10);
Некоторый кредит на то, чтобы потратить на CHATGPT (вы можете получить три месяца бесплатного использования, зарегистрировавшись в OpenAI) (предлагается) ;
Версия CUDA> = 11,2;
Облачная учетная запись IBM для использования их облачных моделей текста в речь (учебник) (необязательно) ;
(Разумно) быстрое подключение к Интернету (большая часть кода зависит от API, поэтому более медленное соединение может привести к более длительному времени для реагирования);
микрофон и динамик;
Графический двигатель CUDA, способный (моя версия Torch: 2.0 и CUDA v11.7 pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 );
Терпение ?
Вы можете положиться на новую setup.bat Bat, которая сделает для вас большинство вещей.
Обзор GitHub
Основной скрипт. Вы должны запустить: openai_api_chatbot.py Если вы хотите использовать последнюю версию API OpenAI в папке Demos, вы найдете некоторое руководство для пакетов, используемых в проекте, если у вас есть ошибки, вы можете сначала проверить эти файлы, чтобы нацелиться на проблему. В основном хранится в папке «Помощник»: get_audio.py хранит все функции для обработки микрофонов, tools.py Pypy реализует некоторые основные аспекты виртуального помощника, voice.py описывает (очень) грубый голосовой класс. Agents.py Обработайте часть системы Langchain (здесь вы можете добавить или удалить инструменты из наборов инструментов агентов) Оставшиеся сценарии являются дополнительными для генерации голоса и не должны отредактировать.
Учебное пособие по установке
Автоматическая установка
Вы можете запустить setup.bat если вы работаете в Windows/Linux. Сценарий будет выполнять каждый шаг ручной установки в последовательности. Обратитесь к тем, если процедура не удастся. Автоматическая установка также запустит установку Vicuna (Руководство по установке Vicuna)
Ручная установка
Шаг 1: Установка, учетные записи, API ...
Среда
Сделайте новую пустую виртуальную среду с Python 3.8 и активируйте ее (. Venv_name scripts activeate);
pip install -r venv_requirements.txt ; Это может занять некоторое время; Если вы столкнетесь с конфликтами на определенных пакетах, установите их вручную без ==<version> ;
Установите вручную Pytorch в соответствии с вашей версией CUDA;
Скопируйте и вставьте файлы, которые вы найдете в папке whisper_edits в папку whisper вашей среды (. Venv lib site-packages Whisper ) Эти изменения добавят лишь атрибут в модель Whisper, чтобы легче получить доступ к ее размере;
установить TTS;
Запустите их сценарий и проверьте, что все работает (он должен загружать некоторые модели) (вы можете запустить demos/tts_demo.py );
Переименовать или удалить папку TTS и загрузить помощника и других сценариев из этого репо.
Установите Vicuna после инструкций в папке Vicuna или запуска:
cd Vicuna call vicuna.ps1
Ручные инструкции поручают вам следовать руководству по установке Vicuna
Вставьте все свои ключи в файл env.txt и переименовать в .env (да, удалите расширение TXT)
Проверьте все, что работает (следующее)
Чеки
Убедитесь, что ваш графический двигатель и версия CUDA совместимы с Pytorch, используя torch.cuda.is_available() и torch.cuda.get_device_name(0) внутри Pyhton; Полем
запустить tests.py . Этот файл пытается выполнить основные операции, которые могут выразить ошибки;
[Предупреждение] Проверьте часто задаваемые вопросы ниже, если у вас есть ошибки;
Вы можете проверить источники ошибки, запустив демонстрации в папке Demos;
Шаг 2: Поддержка языка
Чтобы получить ответы на вашем языке, вы должны сначала проверить, поддерживается ли ваш язык речевым генератором по адресу https://cloud.ibm.com/docs/text-topeech?topic=text-topeech-Voices ;
Если он поддерживается, добавьте или измените языки внутри VirtualAssistant.__init__() ;
Помните: загруженный шепот - средний. Если он плохо работает на вашем языке, обновите до более крупного в __main__() на whisper_model = whisper.load_model("large") ; Но я надеюсь, что ваша память графического процессора также велико.
Шаг 3: Запуск ( openai_api_chatbot.py ):
При запуске вы увидите много информации, отображаемой. Я постоянно стараюсь улучшить читаемость исполнения, весь проект представляет собой огромную бета -версию, прощайте небольшие вариации с экранов ниже. В любом случае, это то, что происходит в общих чертах, когда вы нажимаете «запустить»:
Происходят предварительные инициализации, вы должны услышать звонок, когда помощник будет готов;
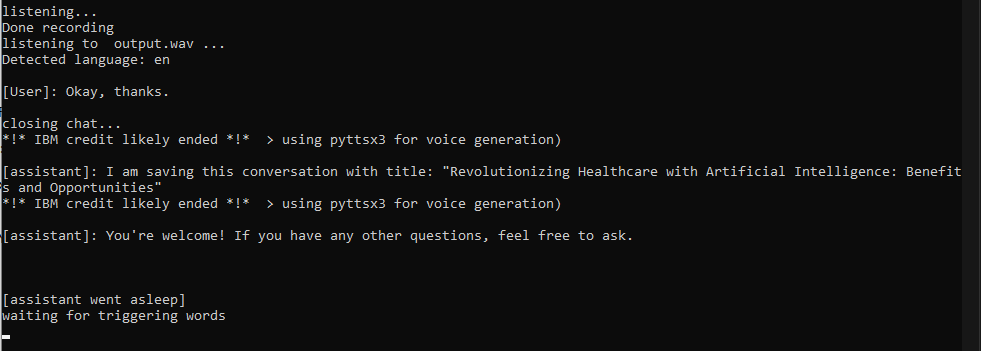
Когда отображается в ожидании запуска слов, вам нужно будет сказать Jarvis , чтобы вызвать помощника. На данный момент начнется разговор, и вы можете говорить на любом языке, который вы хотите (если вы следовали шагу 2). Разговор прекратится, когда вы 1) произнесете стоп -слово 2) Скажите что -нибудь с одним словом (например, «ОК») 3), когда вы перестанете задавать вопросы более 30 секунд
После того, как волшебное слово сказано, слово слушающее ... должно быть, должно появиться. На этом этапе вы можете задать свой вопрос. Когда вы закончите, просто подождите (3 секунды), чтобы ответ был отправлен;
Сценарий преобразует записанный звук в текст с помощью Whisper;
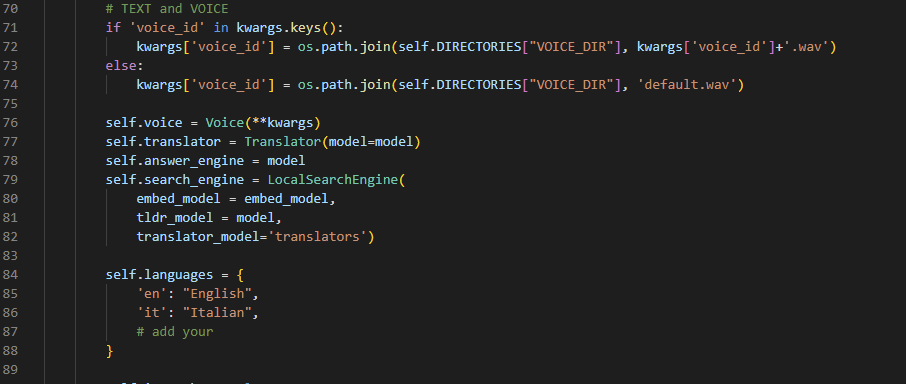
Текст будет проанализирован, и будет принято решение. Если помощник считает, что ему нужно предпринять некоторые действия, чтобы ответить (например, поиск прошлого разговора), агенты Langchain составит план и используют свой инструмент для ответа.
В остальном, сценарий затем расширит chat_history с вашим вопросом, он отправит запрос с API, и он обновит историю, как только он получит полный ответ от CHATGPT (это может занять до 5-10 секунд, подумайте о явном запросе на короткий ответ, если вы спешите);
Функция say() будет выполнять дублирование голоса, чтобы поговорить с Джарвисом/чьим -то голосом; Если аргумент не на английском языке, IBM Watson отправит ответ из одной из своих хороших моделей текста в речь. Если все не удается, функции будут полагаться на Pyttsx3, который является быстрым, но не такой классной альтернативой;
Когда будет сказано какое -либо из ключевых слов Stop, сценарий попросит Chatgpt дать заголовок для разговора и сохранит чат в файле .txt с форматом 'currentDate_title.txt';
Помощник затем вернется ко сну;
Я сделал несколько подсказок и закрыл разговор
Ключевые слова:
Чтобы остановить или сохранить чат, просто скажите «спасибо» в какой -то момент;
Чтобы вызвать голос Джарвиса, просто скажет «Джарвис» в какой -то момент;
Не идеален, я знаю, но сейчас работает
История:
[11 - 2022] Доставьте чаты, подобные чате, от Python с клавиатуры
[12 - 2022] Доставить чат, подобные подсказкам от Python с голосом
[2 - 2023] Международная языковая поддержка для быстрого и ответов
[3 - 2023] Настройка голоса Jarvis
[3 - 2023] Сохраните разговор
[3 - 2023] Фоновое выполнение и вызов голоса
[3 - 2023] Улучшение вывода отображаемой информации
[3 - 2023] Улучшение голосовых выступлений Джарвиса посредством быстрого предварительной обработки
[4 - 2023] Введение: чаты хранилища памяти проекта , события, временные рамки и другую соответствующую информацию для данного проекта, который будет доступен позже пользователем или сам помощник
[4 - 2023] Создайте полный класс VirtualAssistant полным стеком с памятью и локальным доступом к хранению
[4 - 2023] Добавьте звуковую обратную связь на разных этапах (звон, звуковые сигналы ...)
[4 - 2023] Международная языковая поддержка для голосовых команд (бета)
[4-2023] Создание пошагового учебника
[4 - 2023] Переместите некоторую обработку локально, чтобы сократить потребление кредита: Vicuna: новая, мощная модель, основанная на ламе, и обученная GPT -4;
[4 - 2023] интегрируйтесь с одиннадцатью голосами Labs для супер выразительных голосов и выдающегося голосового клонирования;
[4 - 2023] Расширение голосовых команд и действий (сделайте лучшим активным помощником)
[4 - 2023] Подключите систему к Интернету
[6 - 2023] Подключитесь к базе данных бумаги
В настоящее время работает над:
Расширить инструменты обработки DOC
Найдите бесплатную альтернативу для агентов Langchain
следующий:
Исправление ошибки длины чата (когда чат слишком длинный, он не может быть обработан CATGPT 3.5 Turbo)
Расширение памяти
Отчеты об аварии
Уточнить возможности
В ожидании чатгпта4:
Добавьте мультимодальный вход (то есть «Как вы думаете, это» [это может летать на бумажной плоскости » -> Camera -> CathGPT4 ->« Вы должны улучшить кончик крыльев »)
Расширить память проекта на изображения, PDFS, бумаги ...
Проверьте UpdateHistory.md проекта, чтобы узнать больше.
Веселиться!
Ошибки и часто задаваемые вопросы
Категории: установить, общие, время выполнения
Установка: у меня есть конфликтующие пакеты при установке venv_requirements.txt , что мне делать?
Убедитесь, что у вас есть правильная версия Python (3.7) на .venv (> Python -версия с активированной виртуальной средой).
Попробуйте отредактировать venv_requirements.txt и удалить требования к версии инкриминированных зависимостей.
Прямо удалите пакет из файла TXT и установите их вручную после.
Установка: я встречаю ошибку при запуске OpenAI_API_CHATBOT.PY SWITE: TYPERROR: ARGERTIBLIBRARY () () 1 должен быть STR, не то, что случилось?
Проблема заключается в шепоте. Вы должны переустановить его вручную с pip install whisper-openai
Установка: я не могу импортировать 'openai.embeddings_utils'
Попробуйте pip install --upgrade openai .
Это происходит потому, что OpenAI повысил свои минимальные требования. У меня была эта проблема, и она решила путем ручной загрузки embeddings_utils.py Inside ./< Youour_venv>/lib/site-packages/openai/
3. Если проблема сохраняется с `` `DataLib``` `` по подбору проблемы, и я предоставлю вам отсутствующий файл 4. обновление до Python 3.8 (создайте новые Env и повторные установки TTS, требования)
Установка: я сталкиваюсь с ошибкой modulenotFounderror: No Module с именем '<некоторые модуль>'
Требования не обновляются каждый коммит. Хотя это может генерировать ошибки, вы можете быстро установить пропущенные модули, в то же время он удерживает среду в чистоте от конфликтов, когда я пробую новые пакеты (и я пробую их много)
Время выполнения: я сталкиваюсь с какой -то памятью OOM при загрузке модели шепота, что это значит?
Это означает, что выбранная вами модель слишком велика для вашей памяти устройства CUDA. К сожалению, вы мало что можете с этим поделать, кроме как загрузить меньшую модель. Если меньшая модель не удовлетворяет вас, вы можете захотеть говорить «яснее» или сделать более длинные подсказки, чтобы модель более точно прогнозировала то, что вы говорите. Это звучит неудобно, но, в моем случае, значительно улучшило мой английский говорящий :)
Время выполнения: токены максимальной длины для Chatgpt-3,5-Turbo составляет 4096, но получили ... жетоны.
Эта ошибка все еще присутствует, не ожидайте, что когда -нибудь будет долго беседовать со своим помощником, так как в какой -то момент у нее будет достаточно памяти, чтобы вспомнить весь разговор. Исправление находится в разработке, оно может состоять из принятия подхода «скользящих окон», даже если это может вызвать повторение некоторых концепций.
Генерал: Я закончил свой кредит/демонстрацию Openai, что я могу сделать?
Только выходите в Интернет. Цена не так уж и плоха, и вы можете заплатить несколько долларов в месяц, так как ценообразование зависит от использования (с тяжелыми тестированием я в конечном итоге потреблял эквивалент ~ 4 доллара в месяц во время бесплатной пробной версии). Вы можете установить ограничения на свое ежемесячное потребление токенов.
Используйте гибридный режим, в котором наиболее кредитоспособные задачи выполняются локально бесплатно, а остальные выполняются в Интернете.
Установите Vicuna и запустите автономный режим только с ограниченной производительностью.
Общее: Как долго этот проект будет обновлен?
Прямо сейчас (апрель 2023 г.) Я работаю почти без перерыва над этим. Скорее всего, я сделаю перерыв летом, потому что я буду работать над своей диссертацией.
Если у вас есть вопросы, вы можете связаться со мной, подняв проблему, и я сделаю все возможное, чтобы помочь как можно скорее.
 Изображение от Midjourney AI
Изображение от Midjourney AI