Deep RL Keras
1.0.0
Модульная реализация популярных алгоритмов обучения глубоким подкреплением в Керасе:
Эта реализация требует керас 2.1.6, а также спортзал Openai.
$ pip install gym keras==2.1.6Алгоритм актерского критика представляет собой беззаписи, не политический метод, в котором критик действует как аппроксиматор функции стоимости, а актер в качестве аппроксиматора политической функции. При обучении критик предсказывает TD-ошибку и направляет изучение как самого себя, так и актера. На практике мы приближаемся к TD-ошибке, используя функцию Advantage. Для большей стабильности мы используем общую вычислительную основу в обеих сетях, а также формулировку N-шага со скидкой. Мы также включаем термин регуляризации энтропии («мягкое» обучение), чтобы поощрять исследование. Хотя A2C прост и эффективен, запуск его на играх Atari быстро становится неразрешимым из -за длительного времени вычисления.
Аналогичным образом, как алгоритм A2C, реализация A3C включает в себя асинхронные обновления веса, что обеспечивает гораздо более быстрые вычисления. Мы используем несколько агентов для асинхронного восхождения градиентного восхождения по нескольким потокам. Мы проверяем A3C в среде прорыва Атари.
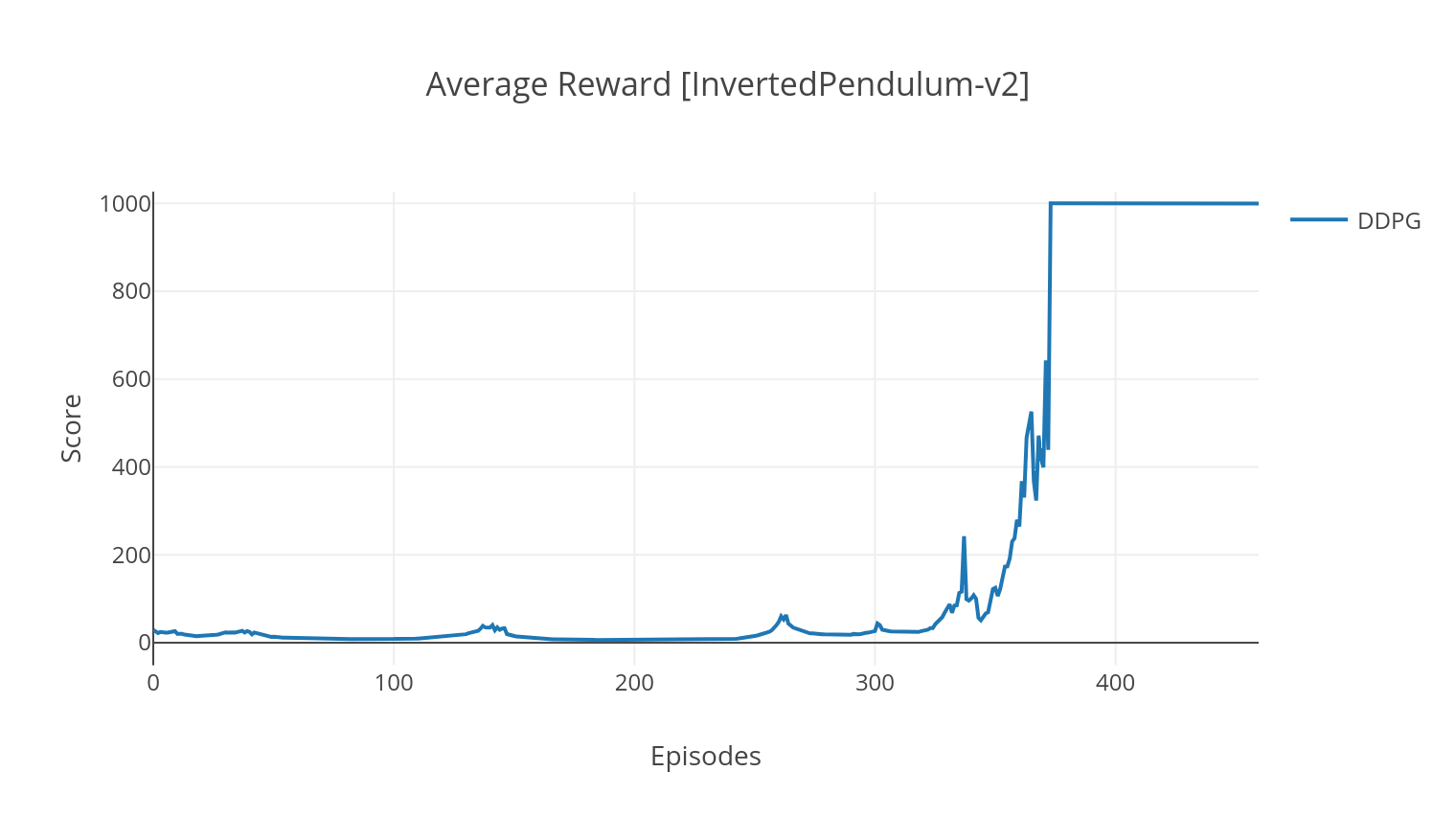
Алгоритм DDPG представляет собой безмодель без политической алгоритма для непрерывных действий. Подобно A2C, это алгоритм актер-критиков, в котором актер обучен детерминированной целевой политике, а критик предсказывает Q-значения. Чтобы уменьшить дисперсию и повысить стабильность, мы используем воспроизведение опыта и отдельные целевые сети. Более того, как намекал Openai, мы поощряем разведку через параметры пространственного шума (в отличие от традиционного пространственного шума). Мы тестируем DDPG в среде Lunar Lander.
$ python3 main.py --type A2C --env CartPole-v1
$ python3 main.py --type A3C --env CartPole-v1 --nb_episodes 10000 --n_threads 16
$ python3 main.py --type A3C --env BreakoutNoFrameskip-v4 --is_atari --nb_episodes 10000 --n_threads 16
$ python3 main.py --type DDPG --env LunarLanderContinuous-v2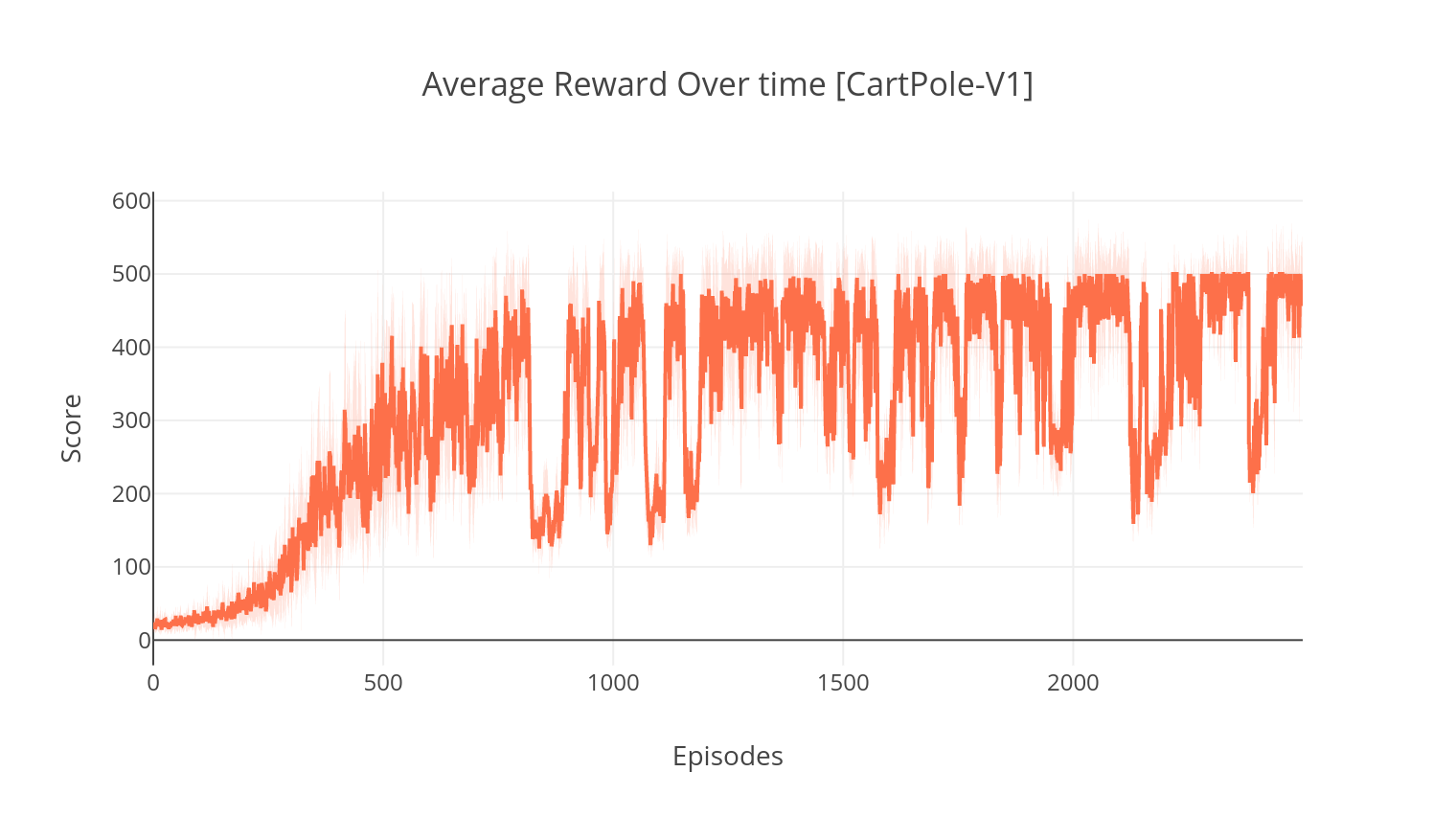
Алгоритм DQN представляет собой алгоритм Q-обучения, который использует глубокую нейронную сеть в качестве аппроксимации функции Q-значения. Мы оцениваем целевые значения Q, используя уравнение Беллмана, и собираем опыт с помощью политики Эпсилон-Грида. Для большей стабильности мы выбираем прошлый опыт случайным образом (переживание воспроизведения). Вариант алгоритма DQN-это двойной DQN (или DDQN). Для более точной оценки наших значений Q мы используем вторую сеть, чтобы погрузить переоценку Q-значений исходной сетью. Эта целевая сеть обновляется с более медленной тау, на каждом этапе обучения.
Мы можем дополнительно улучшить наш алгоритм DDQN, добавив в воспроизведение приоритетного опыта (PER), который направлен на то, чтобы выполнить важность выборки на собранном опыте. Опыт ранжируется по его TD-ошибке и сохраняется в структуре Sumtree, которая позволяет эффективно извлекать переходы (s, a, r, s ') с самой высокой ошибкой.
В дуэльном варианте DQN мы включаем промежуточный уровень в Q-сетевой кладке, чтобы оценить как значение состояния, так и функцию, зависящую от состояния. После переформулировки (см. REF), оказывается, мы можем выразить предполагаемое Q-значение как значение состояния, к которому мы добавляем оценку преимуществ и вычитаем его среднее значение. Эта факторизация независимых от состояния и зависимых от состояния ценностей помогает распутать обучение по действию и дает лучшие результаты.
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --with_PER
$ python3 main.py --type DDQN --env CartPole-v1 --batch_size 64 --dueling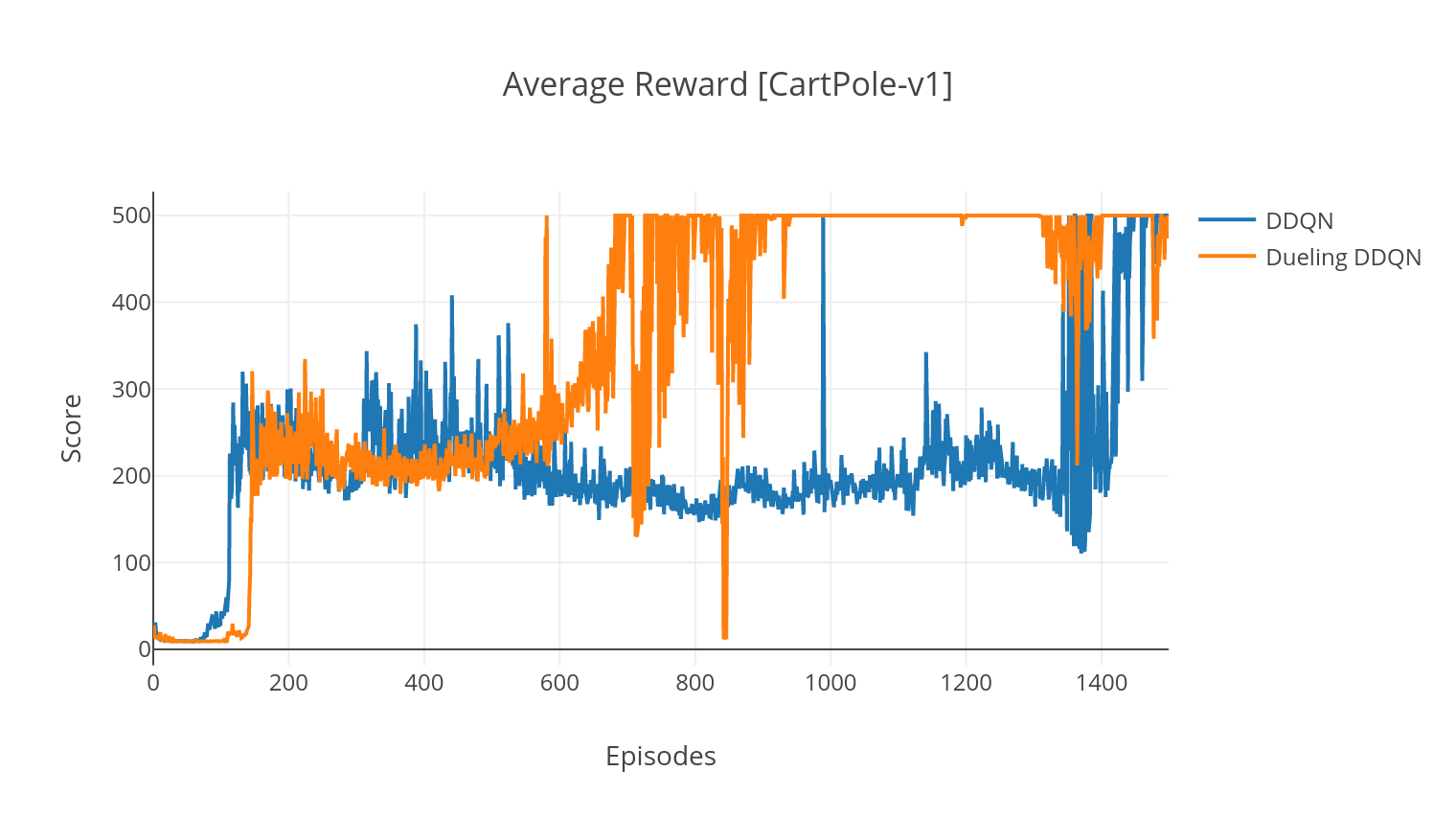
| Аргумент | Описание | Ценности |
|---|---|---|
| --тип | Тип алгоритма RL для запуска | Выберите из {a2c, a3c, ddqn, ddpg} |
| --env | Укажите среду | Breakoutnoframeskip-V4 (по умолчанию) |
| --NB_EPISODES | Количество эпизодов для бега | 5000 (по умолчанию) |
| -batch_size | Размер партии (DDQN, DDPG) | 32 (по умолчанию) |
| -concroctive_frames | Количество сложенных последовательных кадров | 4 (по умолчанию) |
| -IS_ATARI | Является ли среда игрой в атари с входом в пиксель | - |
| -with_per | Использовать ли воспроизведение приоритетного опыта (с DDQN) | - |
| -служить | Использовать ли дуэльные сети (с DDQN) | - |
| --N_THREADS | Количество потоков (A3C) | 16 (по умолчанию) |
| -Gather_stats | Вычислить статистику счетов в среднем за 10 игр (медленно, см. Ниже) | - |
| --оказывать | Делать то, что она будет обучать | - |
| --ГПУ | Индекс графического процессора | 0 |
Все модели сохраняются в рамках <algorithm_folder>/models/ при готовом обучении. Вы можете визуализировать их, работающие в той же среде, в которой они были обучены, запустив сценарий load_and_run.py . Для моделей DQN вы должны указать путь к желаемой модели в аргументе --model_path . Для актерских моделей вам необходимо указать оба веса файлов в аргументах --actor_path и --critic_path .
Используя Tensorboard, вы можете отслеживать счет агента по мере его обучения. При обучении будет создана папка журнала с именем, соответствующей выбранной среде. Например, чтобы следовать прогрессии A2C на Cartpole-V1, просто запустите:
$ tensorboard --logdir=A2C/tensorboard_CartPole-v1/ При обучении с аргументом --gather_stats генерируется файл журнала, содержащий результаты, усредненные по 10 игр в каждом эпизоде: logs.csv . Используя сюжет, вы можете визуализировать среднее вознаграждение за эпизод. Для этого вам сначала нужно будет установить сюжет и получить бесплатную лицензию.
pip3 install plotlyЧтобы настроить свои учетные данные, запустите:
import plotly
plotly . tools . set_credentials_file ( username = '<your_username>' , api_key = '<your_key>' )Наконец, чтобы построить результаты, запустите:
python3 utils/plot_results.py < path_to_your_log_file >

