lang2sql
1.0.0
Этот репо предоставляет пошаговое руководство и шаблон для настройки естественного языка для генератора кода SQL с помощью API Opneai.
Учебное пособие также доступно на среде.
Последнее обновление: 7 января 2024 года
Быстрое развитие моделей естественного языка, особенно крупных языковых моделей (LLMS), представила многочисленные возможности для различных областей. Одним из наиболее распространенных приложений является использование LLMS для кодирования. Например, CHATGPT и код Meta's CODE и Meta-это LLMS, которые предлагают современный естественный язык для кода генераторов. Одним из возможных вариантов использования является естественный язык для генератора кодов SQL, который может помочь нетехническим специалистам с простыми запросами на данные и, как мы надеемся, позволят командам данных сосредоточиться на более интенсивных задачах. Этот урок фокусируется на настройке языка для генератора кода SQL с использованием API OpenAI.
Одним из возможных приложений является чат -бот, который может отвечать на запросы пользователей с соответствующими данными (рисунок 1). Чатбот может быть интегрирован с пролеченным каналом, используя приложение Python, которое выполняет следующие шаги:
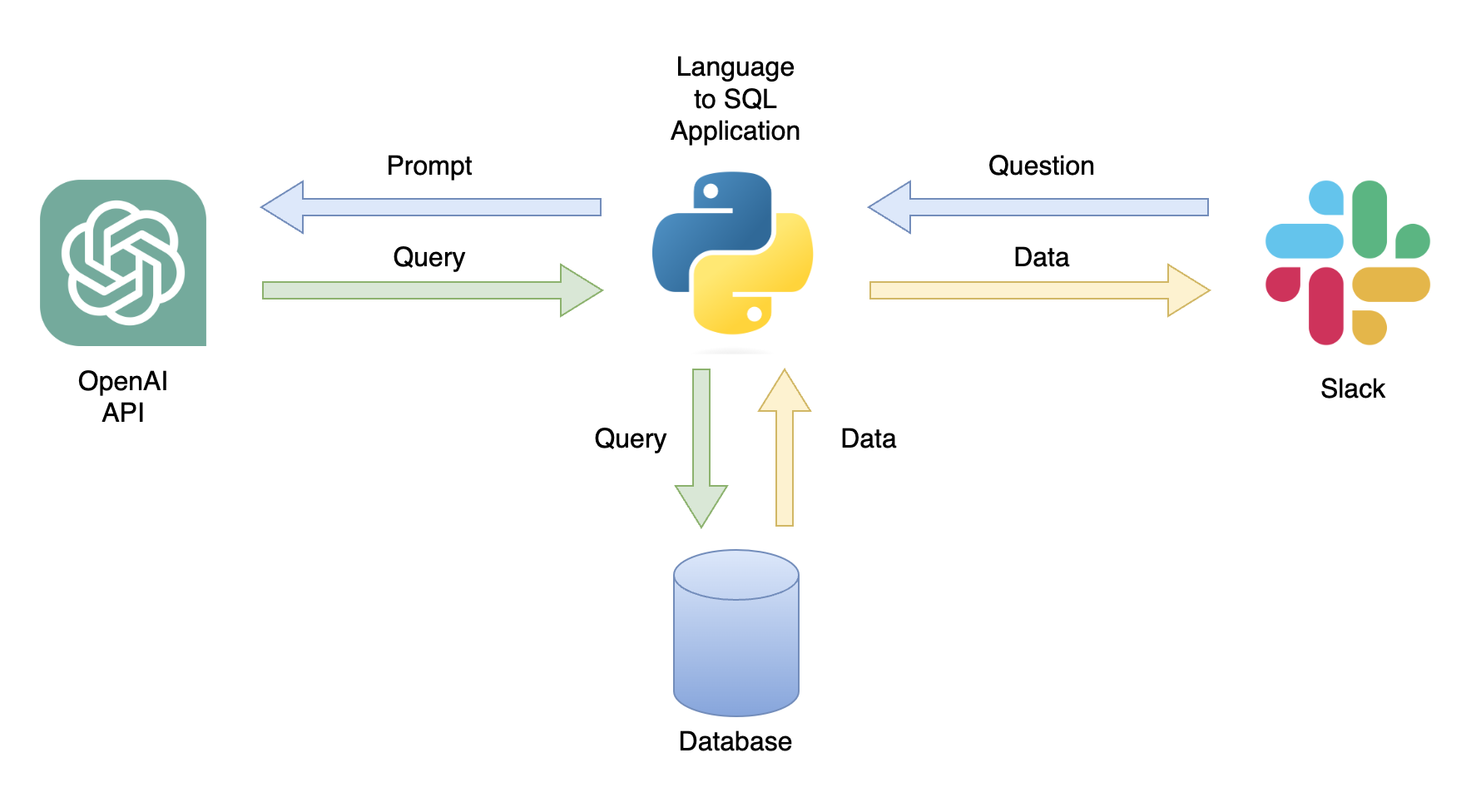
В этом уроке мы создадим пошаговое приложение Python, которое преобразует вопросы пользователя в запросы SQL.
В этом учебном пособии представлены пошаговое руководство о том, как настроить приложение Python, которое преобразует общие вопросы в запросы SQL с использованием API OpenAI. Это включает в себя следующую функциональность:
На рисунке 2 ниже описывается общая архитектура простого языка для генератора кода SQL.
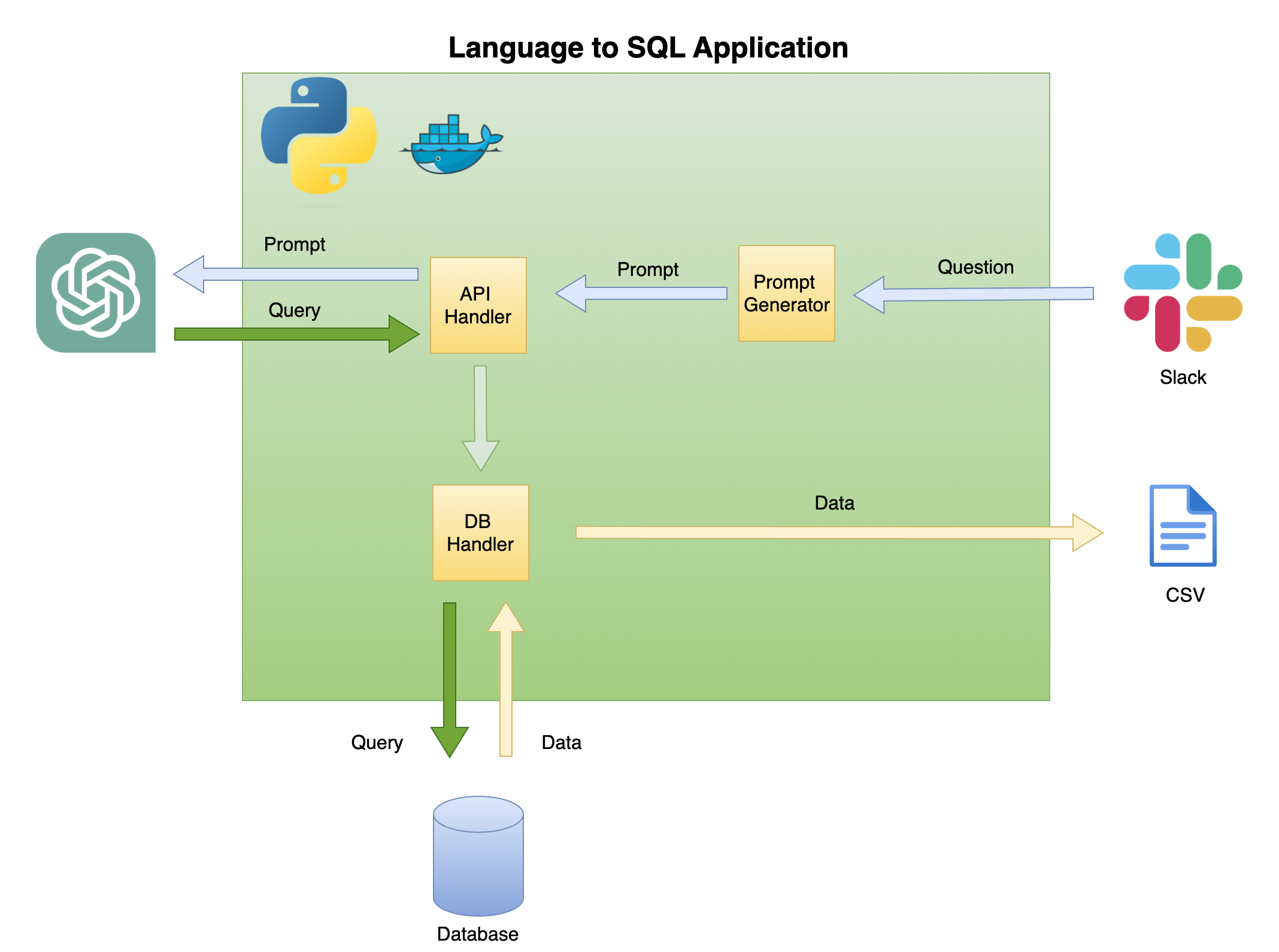
Объем и фокус этого учебника - зеленая коробка - построение следующей функциональности:
Вопрос, чтобы запросить - преобразовать вопрос в формат быстрого приглашения:
Обработчик API - функция, которая работает с API OpenAI:
Обработчик DB - функция, которая отправляет SQL -запрос в базу данных и возвращает требуемые данные
Основной предпосылкой для этого урока является базовое знание Python. Это включает в себя следующую функциональность:
Кроме того, требуются базовые знания SQL и доступ к API OpenAI.
Хотя это не обязательно, полезное знание Docker полезно, так как учебное пособие было создано в приданированной среде с использованием расширения контейнеров Vscode Dev. Если у вас нет опыта работы с Docker или расширением, вы все равно можете запустить учебник, создав виртуальную среду и установив необходимые библиотеки (как описано ниже). Знание быстрого инженера и API OpenAI также полезно.
Я создал подробный учебник о установке среды Python Dockerized с помощью VSCODE и расширения контейнеров DEV:
https://github.com/ramikrispin/vscode-python
Чтобы настроить естественный язык для генерации кода SQL, мы будем использовать следующие библиотеки Python:
pandas - для обработки данных на протяжении всего процессаduckdb - чтобы имитировать работу с базой данныхopenai - работать с API OpenAItime и os - загружать файлы CSV и поля форматаЭтот репозиторий содержит необходимые настройки для запуска приготовленной среды с требованиями к обучению в VSCODE и расширении контейнеров DEV. Более подробная информация доступна в следующем разделе.
В качестве альтернативы, вы можете настроить виртуальную среду и установить требования к учебным пособию, следуя приведенным ниже инструкциям, используя инструкции в разделе «Использование виртуальной среды».
Этот учебник был построен в условиях докеризации с VSCODE и расширением контейнеров DEV. Чтобы запустить его с помощью VSCODE, вам нужно будет установить расширение контейнеров Dev и открыть настольный компьютер Docker (или эквивалент). Настройки среды доступны в папке .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
devcontainer.json имеет инструкции по сборке и настройки VSCODE для этой статей.
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Где аргумент build определяет метод docker build и устанавливает аргументы для сборки. В этом случае мы установили версию Python на 3.10 , а виртуальную среду Conda - ang2sql . Аргумент METHOD определяет тип среды - либо openai , чтобы установить библиотеки требований для этого учебника, используя API OpenAI или transformers для установки среды для API HuggingFaces (который выходит за рамки этого учебника).
Аргумент remoteEnv позволяет устанавливать переменные среды. Мы будем использовать его, чтобы установить ключ API OpenAI. В этом случае я устанавливаю переменную локально как OPENAI_KEY и загружаю ее, используя аргумент localEnv .
Если вы хотите узнать больше о настройке среды разработки Python с помощью VSCODE и Docker, проверьте этот урок.
Если вы не используете среду обучения, вы можете создать локальную виртуальную среду из командной строки, используя сценарий ниже:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
Примечание: я использовал conda , и она должна работать так же, как и в любом другом методе окружающей среды.
Мы используем переменные ENV_NAME и PYTHON_VER для установки виртуальной среды и версии Python, соответственно.
Чтобы подтвердить, что ваша среда правильно установлена, используйте conda list чтобы подтвердить, что установлены необходимые библиотеки Python. Вы должны ожидать вывод ниже:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Мы будем использовать API OpenAI для доступа к CHATGPT, используя двигатель Text-Davinci-003. Это требовало активного аккаунта Openai и ключа API. Легко установить учетную запись и ключ API, следуя инструкциям по ссылке ниже:
https://openai.com/product
После того, как вы установите доступ к API и клавишу, я рекомендую добавить клавишу в качестве переменной среды в ваш файл .zshrc (или любой другой формат, который вы используете для хранения переменных среды в вашей системе оболочки). Я сохранил свой ключ API под переменной среды OPENAI_KEY . По убедительным причинам я рекомендую использовать ту же конвенцию об именах.
Чтобы установить переменную в файле .zshrc (или эквивалент), добавьте ниже строку в файл:
export OPENAI_KEY= " YOUR_API_KEY " При использовании vScode или запуска с терминала вы должны перезагрузить сеанс после добавления переменной в файл .zshrc .
Чтобы моделировать функциональность базы данных, мы будем использовать набор данных по криминальной жизни в Чикаго. Этот набор данных содержит подробную информацию о преступлениях, зарегистрированных в городе Чикаго с 2001 года. С почти 8 миллионами записей и 22 столбцами, набор данных включает в себя такую информацию, как классификация преступности, местоположение, время, результат и т. Д. Доступны данные для загрузки с портала данных Чикаго. Поскольку мы храним данные локально в качестве кадры данных Pandas и используем DuckDB для имитации SQL -запроса, мы загрузим подмножество данных, используя последние три года.
Вы можете извлечь данные из API или загрузить файл CSV. Чтобы не вызывать API каждый раз, когда я запускаю скрипт, я загружаю файлы и храню их в папке данных. Ниже приведены ссылки на наборы данных по году:
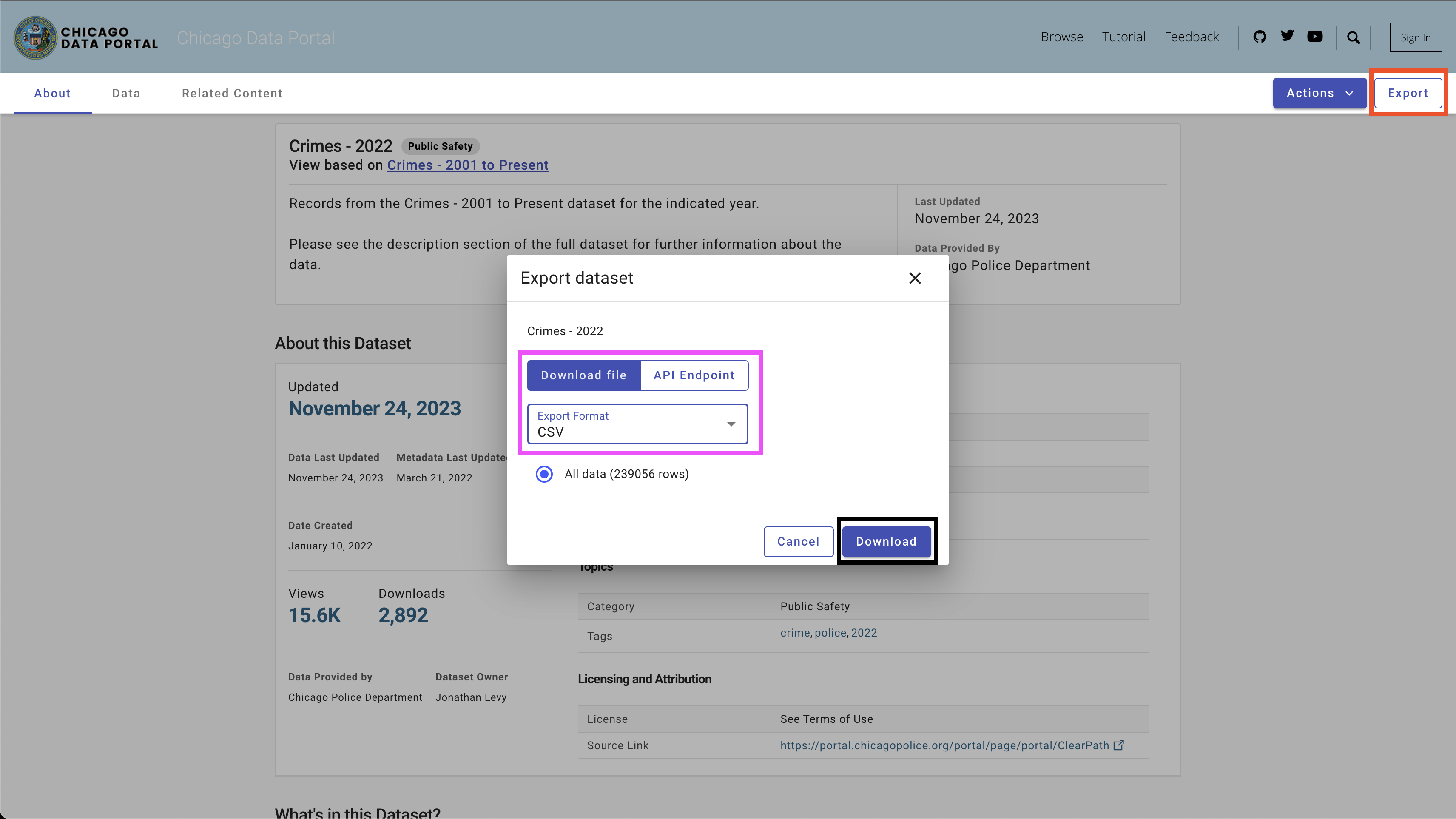
Чтобы загрузить данные, используйте кнопку Export на правой верхней части, выберите опцию CSV и нажмите кнопку Download , как показано на рисунке 4.
Я использовал следующее соглашение о именованиях - chicago_crime_year.csv и сохранил файлы в папке data . Каждый размер файла почти 50 МБ. Поэтому я добавил их в файл GIT игнорировать в папке data , и они недоступны в этом репо. После загрузки файлов и настройки их имен у вас должны быть следующие файлы в папке:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
Примечание. На момент создания этого урока данные за 2023 год все еще обновляются. Следовательно, вы можете получить немного разные результаты при выполнении некоторых запросов в следующем разделе.
Давайте перейдем к захватывающей части, которая настраивает генератор кода SQL. В этом разделе мы создадим функцию Python, которая принимает вопрос пользователя, связанную таблицу SQL и ключ API OpenAI и выводит запрос SQL, который отвечает на вопрос пользователя.
Давайте начнем с загрузки Чикагского набора данных о преступности и необходимых библиотек Python.
Перво -сначала - давайте загрузим необходимые библиотеки Python:
import pandas as pd
import duckdb
import openai
import time
import osМы будем использовать библиотеки ОС и времени для загрузки файлов CSV и переформатирования определенных полей. Данные будут обработаны с использованием библиотеки Pandas , и мы будем моделировать команды SQL с библиотекой DuckDB . Наконец, мы установим соединение с API OpenAI с помощью библиотеки OpenAI .
Затем мы загрузим файлы CSV из папки данных. Приведенный ниже код считывает все файлы CSV , доступные в папке данных:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Если вы загрузили соответствующие файлы за 2021 по 2023 год и использовали то же самое соглашение о именовании, вы должны ожидать следующего вывода:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]Далее мы будем читать и загрузить все файлы и добавить их в кадр данных Pandas:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headЕсли вы правильно загрузили файлы, вы должны ожидать следующего выхода:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Примечание. При создании этого учебника были доступны частичные данные за 2023 год. Добавление трех файлов приведет к большему количеству строк, чем показано (648830 строк).
Прежде чем мы перейдем к коду Python, давайте сделаем паузу и рассмотрим, как работает быстрое инженерное образование и как мы можем помочь CHATGPT (и, как правило, в любом LLM) привести к лучшим результатам. Мы будем использовать в этом разделе веб -интерфейс CHATGPT.
Одним из основных факторов в статистических моделях и моделях машинного обучения является то, что качество вывода зависит от качества ввода. Как говорит знаменитая фраза- мусор, мусор . Точно так же качество вывода LLM зависит от качества подсказки.
Например, давайте предположим, что мы хотим подсчитать количество случаев, которые закончились арестом.
Если мы используем следующую подсказку:
Create an SQL query that counts the number of records that ended up with an arrest.
Вот выход из Chatgpt:
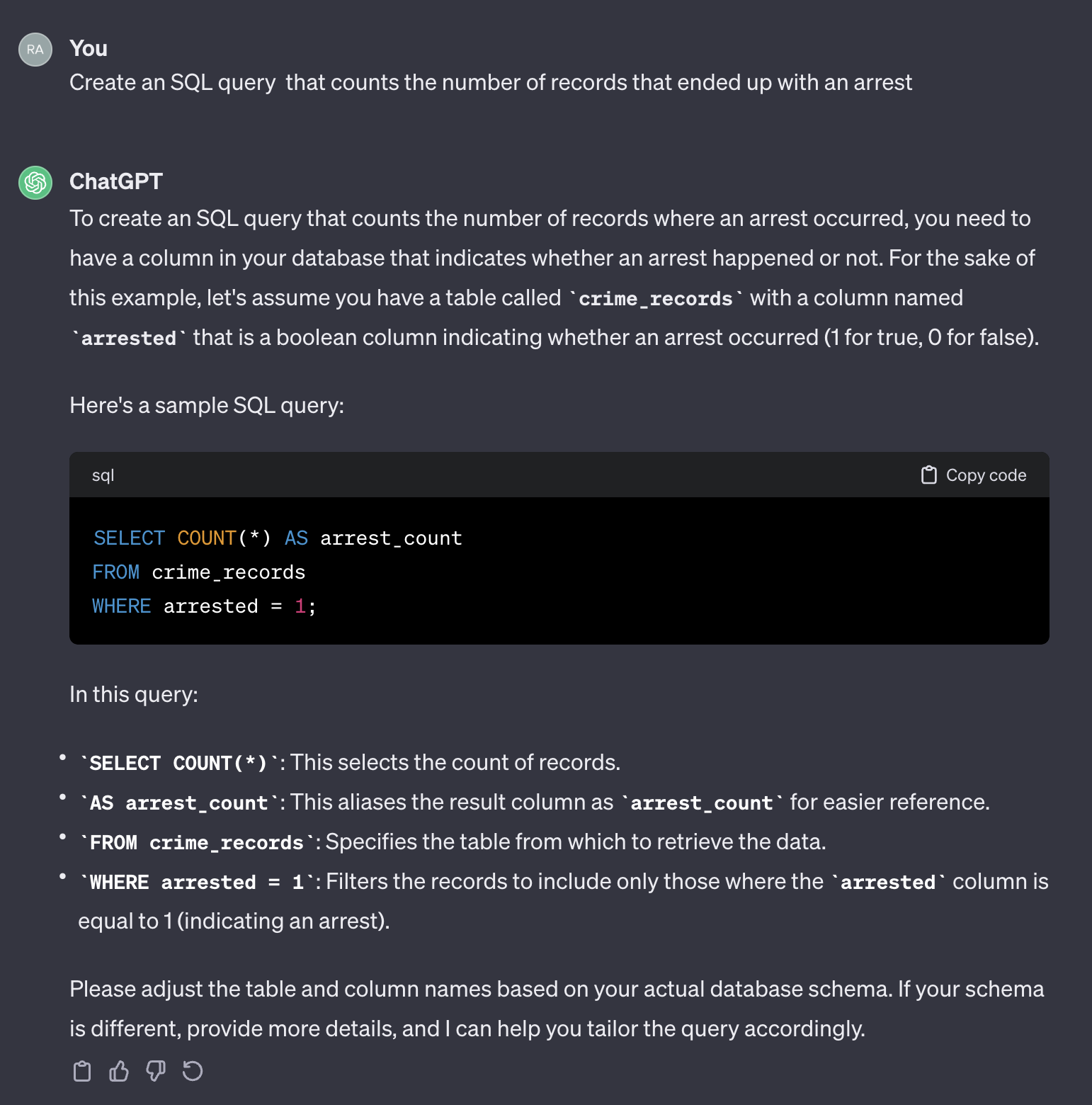
Стоит отметить, что Chatgpt предоставляет общий ответ. Хотя это, как правило, правильно, это может быть не практично использовать в автоматическом процессе. Во -первых, имена поля в ответе не соответствуют именам в фактической таблице, которые мы должны запросить. Во -вторых, поле, которое представляет результат ареста, является логическим ( true или false ) вместо целого числа ( 0 или 1 ).
Чатгпт, в этом смысле, действует как человек. Маловероятно, что вы получите более точный ответ от человека, опубликуя тот же вопрос в форме кодирования, такой как переполнение стека или любую другую подобную платформу. Учитывая, что мы не предоставили какую -либо контекст или дополнительную информацию о характеристиках таблицы, ожидая, что Chatgpt угадает имена поля, и их значения будут необоснованными. Контекст является важным фактором в любой подсказке. Чтобы проиллюстрировать этот момент, давайте посмотрим, как Chatgpt обрабатывает следующее подсказку:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Вот выход из Chatgpt:
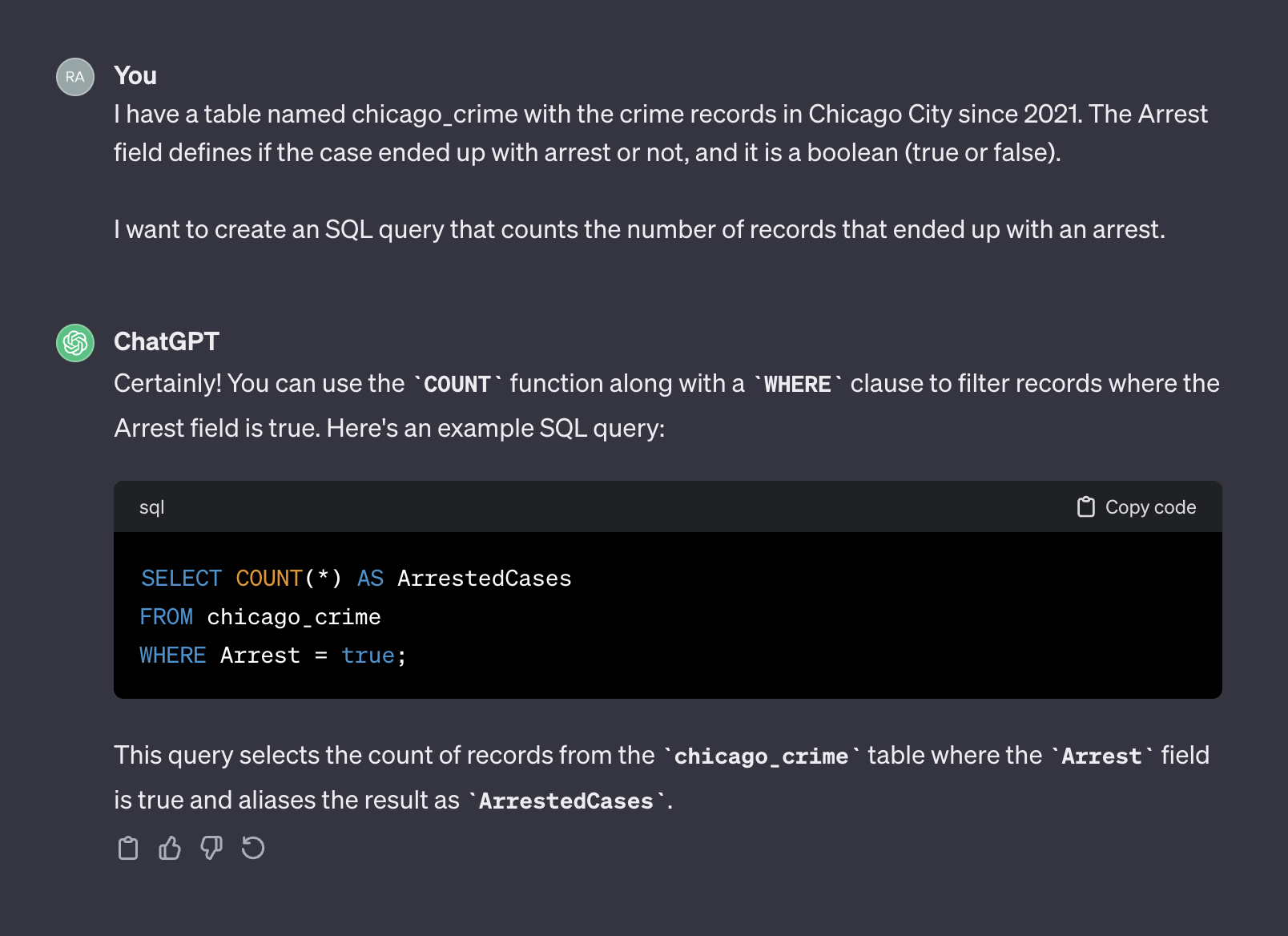
На этот раз, после добавления контекста, CHATGPT вернул правильный запрос, который мы можем использовать как есть. Как правило, при работе с текстовым генератором подсказка должна включать два компонента - контекст и запрос. В вышеупомянутом подсказке первый абзац представляет контекст подсказки:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Где второй абзац представляет запрос:
I want to create an SQL query that counts the number of records that ended up with an arrest.
API OpenAI относится к контексту как system и запросом как user .
Документация API OpenAI предоставляет рекомендацию о том, как установить system и компоненты user в приглашении при запросе сгенерирования кода SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
В следующем разделе мы будем использовать приведенный выше пример OpenAI и обобщать его в шаблоне общего назначения.
В предыдущем разделе мы обсудили важность быстрой инженерии и то, как обеспечение хорошего контекста может повысить точность ответа LLM. Кроме того, мы увидели рекомендованную OpenAI -структуру для генерации кода SQL. В этом разделе мы сосредоточимся на обобщении процесса создания подсказок для генерации SQL на основе этих принципов. Цель состоит в том, чтобы построить функцию Python, которая получает имя таблицы и вопрос пользователя, и соответственно создает быстро. Например, для таблицы таблицы chicago_crime которую мы загрузили ранее, и вопрос, который мы задавали в предыдущем разделе, функция должна создать приведенное ниже приглашение:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Давайте начнем с быстрого структуры. Мы примем формат OpenAI и используем следующий шаблон:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Где system_template получил два элемента:
Для этого урока мы будем использовать библиотеку DuckDB для обработки рамки данных Pandas, так как это была таблица SQL и извлеките имена и атрибуты поля таблицы, используя функцию duckdb.sql . Например, давайте используем команду DESCRIBE SQL для извлечения информации о полях таблицы chicago_crime :
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Который должен вернуть таблицу ниже:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Примечание. Информация, которая нам нужна - имя столбца и его атрибут доступны в первых двух столбцах. Поэтому нам нужно будет анализировать эти столбцы и объединить их вместе с следующим форматом:
Column_Name Column_Attribute
Например, столбец Case Number должен перенести в следующий формат:
Case Number VARCHAR
Функция create_message ниже организует процесс принятия имени таблицы и вопроса и генерации подсказки с помощью вышеуказанной логики:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m Функция создает шаблон приглашения и возвращает system запросов и компоненты user и имена и атрибуты столбцов. Например, давайте запустим количество вопроса об аресте:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Это вернется:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object Вывод функции create_message был разработан для соответствия API API ChatCompletion.create API API.
Этот раздел посвящен функциональности библиотеки Python OpenAI. Библиотека Openai обеспечивает бесшовный доступ к API Openai REST. Мы будем использовать библиотеку для подключения к API и отправить запросы GET с нашей подсказкой.
Давайте начнем с подключения к API, подав наш API с функцией openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) Примечание. Мы использовали функцию getenv из библиотеки os для загрузки переменной среды OpenAI_KEY. В качестве альтернативы, вы можете накопить непосредственно свой ключ API:
openai . api_key = "YOUR_OPENAI_API_KEY"API OpenAI обеспечивает доступ к различным LLM с различными функциями. Вы можете использовать функцию openai.model.list, чтобы получить список доступных моделей:
openai . Model . list () Чтобы преобразовать его в хороший формат, вы можете обернуть его в кадр данных pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headИ следует ожидать следующего вывода:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Для нашего варианта использования, генерации текста, мы будем использовать модель gpt-3.5-turbo , которая является улучшением модели GPT3. Модель gpt-3.5-turbo представляет собой серию моделей, которые продолжают обновляться, и по умолчанию, если модельная версия не указана, API укажет на самый последний стабильный выпуск. При создании этого урока модель по умолчанию 3.5 была gpt-3.5-turbo-0613 , используя 4096 токенов и обученную с данными до сентября 2021 года.
Чтобы отправить запрос GET с нашей подсказкой, мы будем использовать функцию ChatCompletion.create . Функция имеет много аргументов, и мы будем использовать следующие:
model - идентификатор модели для использования, полный список, доступный здесьmessages - список сообщений, включающих разговор до сих пор (например, подсказка)temperature - Управляйте случайностью или детерминизмом вывода процесса путем установки уровня температуры выборки. Уровень температуры принимает значения от 0 до 2. Когда значение аргумента выше, выход становится более случайным. И наоборот, когда значение аргумента ближе к 0, выход становится более детерминированным (воспроизводимый)max_tokens - максимальное количество токенов для создания в завершенииПолный список аргументов функции, доступных в API Documentaiton.
В приведенном ниже примере мы будем использовать ту же подсказку, что и та, которая использовалась в веб -интерфейсе CHATGPT (то есть рисунок 5), на этот раз с помощью API. Мы сгенерируем подсказку с функцией create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Давайте преобразуем вышеупомянутое подсказку в структуру ChatCompletion.create Функциональных messages Аргумент:
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] Далее мы отправим подсказку (т.е. объект message ) в API с использованием функции ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Мы установим аргумент temperature на 0, чтобы обеспечить высокую воспроизводимость и ограничить количество токенов при завершении текста до 256. Функция возвращает объект JSON с завершением текста, метаданных и другой информацией:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}Используя Indies, мы можем извлечь запрос SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Используя функцию duckdb.sql для запуска кода SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘В следующем разделе мы будем обобщать и функционализировать все шаги.
В предыдущих разделах мы представили формат подсказки, установили функцию create_message и рассмотрели функциональность функции ChatCompletion.create . В этом разделе мы сшиваем все это вместе.
Одна вещь, которую следует отметить о возвращенном коде SQL из функции ChatCompletion.create , заключается в том, что переменная не возвращается с кавычками. Это может быть проблемой, когда имя переменной в запросе объединяет два или более слова. Например, использование переменной, такой как Case Number или Primary Type из chicago_crime внутри запроса без использования кавычек, приведет к ошибке.
Мы будем использовать приведенную ниже вспомогательную функцию, чтобы добавить кавычки к переменным в запросе, если у возвращенного запроса его нет:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) Входы функции являются запросом и именами столбцов соответствующей таблицы. Он процитирует имена столбцов и добавляет кавычки, если находит совпадение в запросе. Например, мы можем запустить его с помощью SQL -запроса, который мы проанализировали из ChatCompletion.create function output:
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Вы можете заметить, что он добавил кавычки к переменной Arrest .
Теперь мы можем представить функцию lang2sql , которая использует три функции, которые мы представили до сих пор - create_message , ChatCompletion.create и add_quotes для перевода вопроса пользователя в код SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output Функция получает, в качестве входов, ключ API OpenAI, имя таблицы и параметры ядра функции ChatCompletion.create и возвращает объект с помощью подсказки, ответа API и анализируемый запрос. Например, давайте попробуем перезапустить тот же запрос, который мы использовали в предыдущем разделе с функцией lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Мы можем извлечь SQL -запрос из выходного объекта:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Мы можем проверить выход по результатам, которые мы получили в предыдущем разделе:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Давайте теперь добавим дополнительную сложность к вопросу и запрашиваем случаи, которые закончились арестом в течение 2022 года:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Как видите, модель правильно определила соответствующее поле как Year и сгенерировала правильный запрос:
print ( response . sql )Код SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Проверка запроса в таблице:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Вот пример простого вопроса, который требовал группировки по определенной переменной:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Вы можете видеть из вывода ответа, что код SQL в этом случае верен:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Это вывод запроса:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘И последнее, но не менее важное: LLM может идентифицировать контекст (например, какая переменная), даже если мы предоставляем частичное имя переменной:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Он возвращает приведенный ниже код SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Это вывод запроса:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘В этом уроке мы продемонстрировали, как создать генератор кода SQL с несколькими строками кода Python и использовать API OpenAI. Мы видели, что качество подсказки имеет решающее значение для успеха полученного кода SQL. В дополнение к контексту, предоставляемому подсказкой, имена поля также должны предоставить информацию о характеристиках поля, чтобы помочь LLM определить актуальность поля к вопросу пользователя.
Хотя этот урок был ограничен работой с одной таблицей (например, без соединений между таблицами), некоторые LLM, такие как те, которые доступны на OpenAI, могут обрабатывать более сложные случаи, включая работу с несколькими таблицами и определение правильных операций соединения. Регулировка функции LANG2SQL для обработки нескольких таблиц может быть хорошим следующим шагом.
Этот учебник лицензирован по международной лицензии Creative Commons Attribution-Noncommercial-Sharealike 4.0.


