
[Рекомендации по теме: видеоуроки по JavaScript, веб-интерфейс]
Независимо от того, какой язык программирования вы используете, строки являются важным типом данных. Следуйте за мной, чтобы узнать больше о строках JavaScript !
Строка — это строка, состоящая из символов. Если вы изучали C и Java , вы должны знать, что сами символы также могут стать независимым типом. Однако JavaScript нет единого типа символов, есть только строки длиной 1 .
Строки JavaScript используют фиксированную кодировку UTF-16 . Независимо от того, какую кодировку мы используем при написании программы, это не повлияет на нее.
строк: одинарные кавычки, двойные кавычки и обратные кавычки.
let single = 'abcdefg';//Одинарные кавычки let double = "asdfghj";//Двойные кавычки let backti = `zxcvbnm`;//Обратные
одинарные и двойные кавычки имеют одинаковый статус, мы не делаем различий.
Обратные кавычкиформатирования строк
позволяют нам элегантно форматировать строки, используя ${...} вместо сложения строк.
let str = `Мне ${Math.round(18.5)} лет.`;console.log(str); Результат выполнения кода:

в многострочных строках
также позволяют строке охватывать строки, что очень полезно при написании многострочных строк.
let ques = `Автор красивый? А. Очень красивый; Б. Такой красивый; C. Супер красивый;`;console.log(ques);
Результаты выполнения кода:
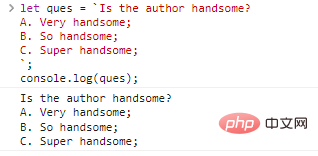
Вам не кажется, что в этом нет ничего плохого? Но этого нельзя добиться с помощью одинарных и двойных кавычек. Если вы хотите получить одинаковый результат, вы можете написать так:
let ques = 'Автор красивый?nA. Очень красивый;nB.Такой красивый;nC. Супер красиво;'; console.log(ques);
Приведенный выше код содержит специальный символ n , который является наиболее распространенным специальным символом в нашем процессе программирования.
символ n также известный как «символ новой строки», поддерживает одинарные и двойные кавычки для вывода многострочных строк. Когда механизм выводит строку, если он встречает n , он продолжит вывод на другой строке, тем самым реализуя многострочную строку.
Хотя n выглядит как два символа, он занимает только одну позицию. Это связано с тем, что является escape-символом в строке, а символы, измененные этим escape-символом, становятся специальными символами.
Список специальных символов
| Описание | специальных символов | |
|---|---|---|
n | , используемый для начала новой строки выводимого текста. | |
r | перемещает курсор в начало строки. В системах Windows rn используется для обозначения разрыва строки, что означает, что курсор должен сначала перейти к началу строки, а затем к началу строки. на следующую строку, прежде чем она сможет перейти на новую строку. Другие системы могут использовать n напрямую. | |
' " | Одинарные и двойные кавычки, главным образом потому, что одинарные и двойные кавычки являются специальными символами. Если мы хотим использовать одинарные и двойные кавычки в строке, мы должны экранировать их. | |
\ | Обратная косая черта, также потому, что | |
b f v | , возврат страницы, вертикальная метка - он больше не используется, | |
Unicode XX | xXX | - это шестнадцатеричный символ Юникода, закодированный как XX . : x7A означает. z (шестнадцатеричная кодировка Unicode для z — 7A ). |
uXXXX | кодируется как шестнадцатеричный символ Unicode для XXXX , например: u00A9 означает © | |
( 1-6 базовых символов u{X...X} | UTF-32 кодировка — это символ Unicode X...X . |
Например:
console.log('Я студент.');// 'console.log(""I love U. "");/ / "console.log("\n — символ новой строки.");// nconsole.log('u00A9')// ©console.log('u{1F60D} ');// Код результаты выполнения:
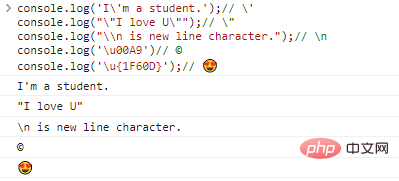
При наличии escape-символа теоретически мы можем вывести любой символ, если найдем соответствующую ему кодировку.
Избегайте использования ' и "
для одинарных и двойных кавычек в строках. Мы можем разумно использовать двойные кавычки внутри одинарных кавычек, использовать одинарные кавычки внутри двойных кавычек или напрямую использовать одинарные и двойные кавычки внутри обратных кавычек. Избегайте использования escape-символов, например:
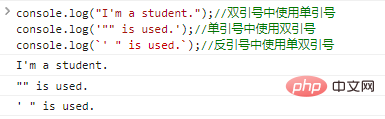
console.log("Я студент.");
//Использовать одинарные кавычки внутри двойных console.log('"" используется.');
//Использовать двойные кавычки внутри одинарных console.log(`' " is use.`);
//Результаты выполнения кода с использованием одинарных и двойных кавычек в обратных кавычках следующие:
С помощью свойства строки .length мы можем получить длину строки:
console.log("HelloWorldn".length);//11 n здесь занимает только один символ.
В главе «Методы базовых типов» мы рассмотрели, почему базовые типы в
JavaScriptимеют свойства и методы. Вы еще помните?
string — это строка символов. Мы можем получить доступ к одному символу через [字符下标] Индекс символа начинается с 0 :
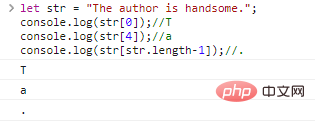
let str = "Автор красивый."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//.
Результаты выполнения кода:
Мы также можем использовать функцию charAt(post) для получения символов:
let str = "Автор красивый.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.Эффект
выполнения обоих абсолютно одинаков, единственная разница заключается в доступе к символам за пределами границ:
let str = "01234"; console.log(str[ 9]);//unknownconsole.log(str.charAt(9));//"" (пустая строка)
Мы также можем использовать for ..of для обхода строки:
for(let c of '01234'){
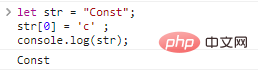
console.log(c);} Строку в JavaScript нельзя изменить после ее определения. Например:
let str = "Const";str[0] = 'c' ;console.log(str)
; результаты:
Если вы хотите получить другую строку, вы можете только создать новую:
let str = "Const";str = str.replace('C','c');console.log
(str);
изменили символы String, фактически исходная строка не была изменена, мы получаем новую строку, возвращаемую методом replace .
преобразует регистр строки или преобразует регистр одного символа в строке.
Методы для этих двух строк относительно просты, как показано в примере:
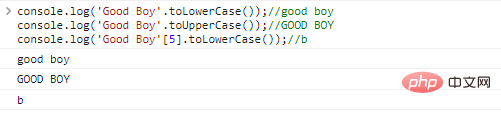
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Хороший мальчик'.toUpperCase());//ХОРОШО
BOYconsole.log('Good Boy'[5].toLowerCase());//b результаты выполнения кода:
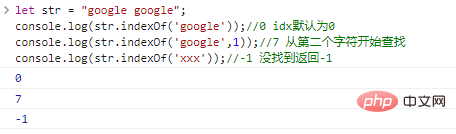
Функция .indexOf(substr,idx) начинается с позиции idx строки, ищет позицию substr и возвращает индекс первого символа строки. подстрока в случае успеха или -1 в случае неудачи.
let str = "google google";console.log(str.indexOf('google'));
//0 idx по умолчанию равен 0console.log(str.indexOf('google',1));
//7 Поиск console.log(str.indexOf('xxx')); начиная со второго символа.
//-1 не найдено, возвращает -1 результат выполнения кода:
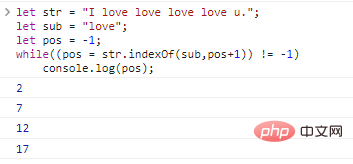
Если мы хотим запросить позиции всех подстрок в строке, мы можем использовать цикл:
let str = "Я люблю, люблю, люблю, люблю тебя.";let sub = "love";let pos = -1; while((pos = str.indexOf (sub,pos+1)) != -1)
console.log(pos); Результаты выполнения кода следующие:
.lastIndexOf(substr,idx) ищет подстроки задом наперед, сначала находя последнюю совпадающую строку:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx по умолчанию равен 0 поскольку методы indexOf() и lastIndexOf() вернут -1 если запрос не удался, и ~-1 === 0 . То есть использование ~ верно только тогда, когда результат запроса не равен -1 , поэтому мы можем:
let str = "google google";if(~indexOf('google',str)){
...} Обычно мы не рекомендуем использовать синтаксис, характеристики синтаксиса которого невозможно четко отразить, поскольку это повлияет на читаемость. К счастью, приведенный выше код встречается только в старой версии кода. Он упомянут здесь, чтобы никто не запутался при чтении старого кода.
Дополнение:
~— это побитовый оператор отрицания. Например: двоичная форма десятичного числа2—0010, а двоичная форма~2—1101(дополнение), что равно-3.Проще говоря,
~nэквивалентно-(n+1), например:~2 === -(2+1) === -3
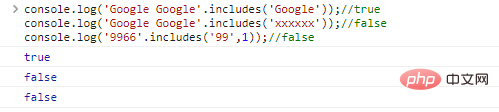
.includes(substr,idx) используется для определения того, является ли substr в строке начальной позицией idx
console.log('Google Google'.includes('Google'));//trueconsole.log( 'Google Google'. include('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//ложные результаты выполнения кода:
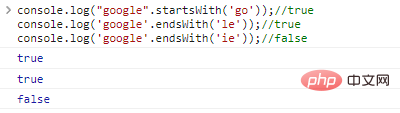
.startsWith('substr') и .endsWith('substr') соответственно определяют, начинается или заканчивается строка с substr
console.log("google".startsWith('go'));//trueconsole.log('google' .endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//ложный результат выполнения кода:
.substr() , .substring() , .slice() используются для получения подстрок строк, но их использование различно.
.substr(start,len)
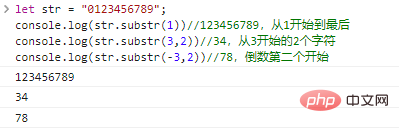
возвращает строку, состоящую из len символов, начиная с start . Если len опущен, она будет перехвачена до конца исходной строки. start может быть отрицательным числом, обозначающим start символ сзади вперед.
let str = "0123456789";console.log(str.substr(1))//123456789, начиная с 1 и до конца console.log(str.substr(3,2))//34, 2, начиная с 3 символов console.log(str.substr(-3,2))//78, предпоследний
результат выполнения стартового кода:
.slice(start,end)
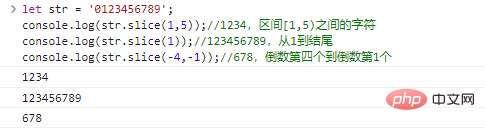
возвращает строку, начинающуюся с start и заканчивающуюся end (эксклюзивно). start и end могут быть отрицательными числами, обозначающими предпоследние start/end символы.
let str = '0123456789';console.log(str.slice(1,5));//1234, символы между интервалом [1,5) console.log(str.slice(1));//123456789 , от 1 до конца console.log(str.slice(-4,-1));//678,
результат выполнения кода от четвертого до последнего:
.substring(start,end)
почти такая же, как .slice() . Разница в двух местах:
end > start разрешены;0 ,например:
let str = '0123456789'; console.log(str .substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1, 3));//012, -1 рассматривается как
результат выполнения кода Make 0:
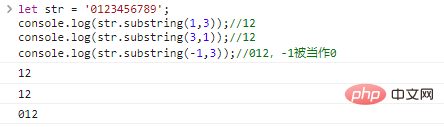
Сравните различия между тремя
| параметрами | описания | метода |
|---|---|---|
.slice(start,end) | [start,end) | может быть отрицательным. Подстрока |
.substring(start,end) | [start,end) | Отрицательное значение 0 |
.substr(start,len) | начинается с start Для len | существует |
методов отрицательной подстроки, поэтому выбрать их, естественно, сложно. Рекомендуется запомнить
.slice(), который более гибок, чем два других.
Мы уже упоминали о сравнении строк в предыдущей статье. Строки сортируются в словарном порядке. За каждым символом находится код, а код ASCII является важной ссылкой.
Например:
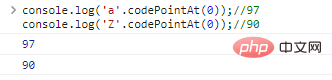
console.log('a'>'Z');// Сравнение истинных символов — это, по сути, сравнение кодировок, представляющих символы. JavaScript использует UTF-16 для кодирования строк. Каждый символ представляет собой 16 битный код. Если вы хотите узнать природу сравнения, вам нужно использовать .codePointAt(idx) для получения кодировки символов:
console.log('a). '.codePointAt(0));//97console.log('Z'.codePointAt(0));//90 результатов выполнения кода:
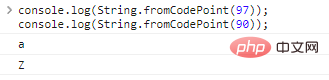
Используйте String.fromCodePoint(code) для преобразования кодировки в символы:
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
Результаты выполнения кода следующие:
Этот процесс можно выполнить с помощью escape-символа u следующим образом:
console.log('u005a');//Z, 005a — это шестнадцатеричная запись 90 console.log('u0061');//a, 0061 Это шестнадцатеричная запись числа 97. Давайте рассмотрим символы, закодированные в диапазоне [65,220] :
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str); Результаты части выполнения кода следующие:

На рисунке выше не показаны все результаты, поэтому попробуйте.
основан на международном стандарте ECMA-402 . JavaScript реализован специальный метод ( .localeCompare() ) для сравнения различных строк с использованием str1.localeCompare(str2) :
str1 < str2 , вернуть отрицательное число;str1 > str2 , верните положительное число;str1 == str2 , верните 0,например:
console.log("abc".localeCompare('def'));//-1 Почему бы не использовать операторы сравнения напрямую?
Это связано с тем, что английские символы имеют особый способ записи. Например, á — это вариант a :
console.log('á' < 'z');// Хотя false также является a , оно больше, чем z ! !
В настоящее время вам необходимо использовать метод .localeCompare() :
console.log('á'.localeCompare('z'));//-1 str.trim() удаляет пробельные символы до и после string, str.trimStart() , str.trimEnd() удаляет пробелы в начале и конце;
let str = " 999 "; console.log(str.trim()); //999
повторов str.repeat(n) строка n раз;
let str = ' 6';console.log(str.repeat(3));//666
str.replace(substr,newstr) заменяет первую подстроку, str.replaceAll() используется для замены всех подстроки;
let str = '9 +9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6')) ;//6+6по-прежнему Есть много других методов, и мы можем обратиться к руководству для получения дополнительной информации.
JavaScript использует UTF-16 для кодирования строк, то есть для представления одного символа используются два байта ( 16 бит). Однако 16 битные данные могут представлять только 65536 символов. общие символы, естественно, не включены. Это легко понять, но для редких символов (китайских), emoji , редких математических символов и т. д. этого недостаточно.
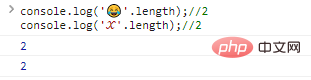
В этом случае вам необходимо расширить и использовать более длинные цифры ( 32 бита) для представления специальных символов, например:
console.log(''.length);//2console.log('?'.length);//2 Результат выполнения кода:
В результате мы не можем обрабатывать их обычными методами. Что произойдет, если мы выведем каждый байт отдельно?
console.log(''[0]);console.log(''[1]); Результаты выполнения кода:
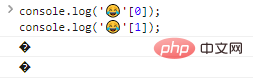
Как видите, отдельные выходные байты не распознаются.
К счастью, методы String.fromCodePoint() и .codePointAt() могут справиться с этой ситуацией, поскольку они были добавлены недавно. В старых версиях JavaScript вы можете использовать только методы String.fromCharCode() и .charCodeAt() для преобразования кодировок и символов, но они не подходят для специальных символов.
Мы можем иметь дело со специальными символами, оценивая диапазон кодировки символа, чтобы определить, является ли он специальным символом. Если код символа находится в диапазоне 0xd800~0xdbff , то это первая часть 32 битного символа, а его вторая часть должна находиться в диапазоне 0xdc00~0xdfff .
Например:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));// результат выполнения кода de02:

В английском языке существует множество буквенных вариантов, например: буква a может быть основным символом àáâäãåā . Не все из этих вариантов символов хранятся в кодировке UTF-16 поскольку существует слишком много комбинаций вариантов.
Для поддержки всех комбинаций вариантов несколько символов Unicode также используются для представления одного вариантного символа. В процессе программирования мы можем использовать базовые символы плюс «декоративные символы» для выражения специальных символов:
console.log('au0307'. );//ş
console.log('au0308');//ş
console.log('au0309');//ş
console.log('Eu0307');//Ė
console.log('Eu0308');//E
console.log('Eu0309');// ẺРезультаты выполнения
кода:
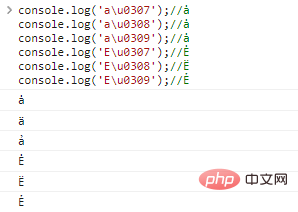
Базовая буква также может иметь несколько украшений, например:
console.log('Eu0307u0323');//Ẹ̇
console.log('Eu0323u0307');// Ẹ̇Результаты выполнения кода:
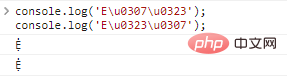
Здесь возникает проблема. В случае нескольких украшений они упорядочены по-разному, но на самом деле отображаемые символы одни и те же.
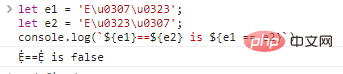
Если мы сравним эти два представления напрямую, то получим неверный результат:
пусть e1 = 'Eu0307u0323';
пусть e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`) результаты выполнения кода:
Чтобы решить эту ситуацию, существует ** алгоритм нормализации Unicode , который может преобразовать строку в универсальный ** формат, реализованный с помощью str.normalize() :
let e1 = 'Eu0307u0323';
пусть e2 = 'Eu0323u0307';
console.log(`${e1}==${e2} равно ${e1.normalize() == e2.normalize()}`)
Результаты выполнения кода:

[Рекомендации по теме: видеоуроки по JavaScript, веб-интерфейс]
Выше приведено подробное содержание общих базовых методов работы со строками JavaScript. Для получения дополнительной информации обратите внимание на другие соответствующие статьи на китайском веб-сайте PHP!