Мы просканировали всю информацию веб-страницы в предыдущем разделе. Теперь нам нужно найти нужный нам контент в html-коде. Поэтому нам нужно войти на сайт в соответствии с проблемой и проанализировать информацию на веб-странице.
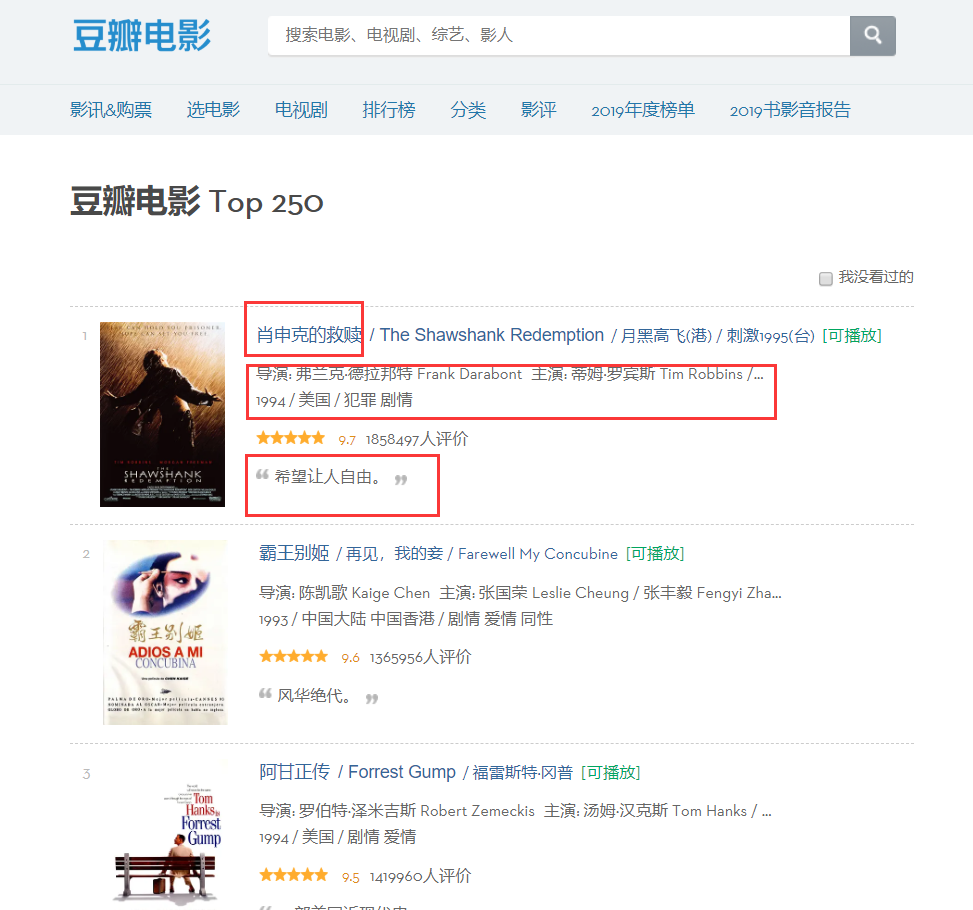
На странице видно, что информация, которую нам нужно сканировать, существует в разных разделах, поэтому давайте проверим элементы страницы, щелкните страницу правой кнопкой мыши, чтобы проверить исходный код веб-страницы, или F12.

Прежде чем анализировать веб-страницу, мы сначала указываем метод хранения после анализа. Здесь мы используем список для хранения всей информации, а затем каждый элемент в списке соответствует словарю, и каждый словарь соответствует нескольким типам информации.
Movies=[]#Сначала определите список для хранения всей информации
Путем анализа мы можем определить, что позиция заголовка — это первый «пролет» в первой «а» под «div» с именем «hd», поэтому мы можем заблокировать имя каждого фильма с помощью следующего кода, а затем в словарь.
Moviename=each.find('div',class_='hd').a.span.text.strip()movie['title']=moviename#Элемент в словареТочно так же исходный код имени режиссёра можно найти по позиционированию, но этот исходный код содержит много информации, поэтому нам нужно фильтровать её через регулярные выражения.
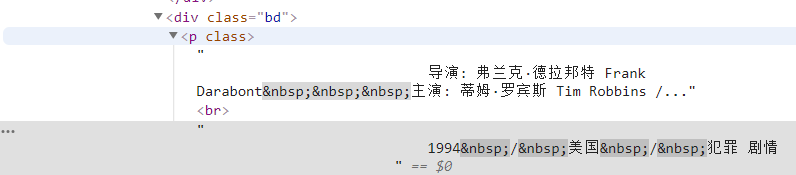
info=each.find('div',class_='bd').p.text.strip()Сначала находим весь контент под этим тегом, а затем отфильтровываем ненужную информацию через регулярные выражения.
info=info.replace('n',)#Фильтрация возврата каретки info=info.replace(,)#Фильтрация пробелов info=info.replace(xa0,)#Фильтрация неразрывных пробельных символов Director=re.findall( r '[Режиссер:].+[В главных ролях:]',info)[0]режиссер=режиссер[3:len(режиссер)-6]Затем определите его как элемент словаря.
movie['director']=режиссер#Элемент в словаре
Мы можем обнаружить, что тип фильма также находится в этом теге «p», и мы также получаем эту информацию напрямую через регулярные выражения.
plot=re.findall(r'[0-9]*[/].+[/].+',info)[0]plot=plot[1:]plot=plot[plot.index('/') +1:]plot=plot[plot.index('/')+1:]movie['plot']=plot#Добавить как элемент в словарьНаконец, заблокируйте информацию о рейтинге.
star=each.find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()Затем продолжайте сохранять его в виде словаря.
фильм['star']=звезда
Наконец добавьте этот словарь в список и переберите выходные данные.
Movies.append(movie)#Добавить словарь в список foriinmovies:#Пройти вывод print(i)
importreimportrequestsfrombs4importBeautifulSoupforiinrange(1):headers={#Имитировать браузер для доступа к 'user-agent':'Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/52.0.2743.82Safari/537.36' , 'Хост':'movie.douban.com'}res='https://movie.douban.com/top250?start='+str(25*i)#25 раз r=requests.get(res,headers = headers,timeout=10)#Установите таймаут суп=BeautifulSoup(r.text,html.parser)#Установите метод синтаксического анализа, можно использовать и другие методы. div_list=soup.find_all('div',class_='item')movies=[]foreachindiv_list:movie={}moviename=each.find('div',class_='hd').a.span.text.strip ()movie['title']=movienamerank=each.find('div',class_='pic').em.text.strip()movie['rank']=rankinfo=each.find('div', class_='bd').p.text.strip()info=info.replace('n',)info=info.replace(,)info=info.replace(xa0,)director=re.findall( r'[Режиссер:].+[В главных ролях:]',info)[0]режиссер=режиссер[3:len(режиссер)-6]фильм['режиссер']=directorrelease_date=re.findall(r'[0- 9]{4}',info)[0]movie['release_date']=release_dateplot=re.findall(r'[0-9]*[/].+[/].+',info)[0] plot=plot[1:]plot=plot[plot.index('/')+1:]plot=plot[plot.index('/')+1:]movie['plot']=plotstar=each. find('div',class_='star')star=star.find('span',class_='rating_num').text.strip()movie['star']=starmovies.append(movie)foriinmovies:print (я)Консоль:

В этом примере мы в основном узнаем, как найти соответствующую информацию в исходном коде веб-страницы. BeautifulSoup может помочь нам быстро найти ее, а затем объединить ее с регулярными выражениями для завершения сопоставления информации. сохранит эти данные в базу данных.