Новейшая мультимодальная языковая модель BLIP-3-Video, выпущенная исследовательской группой Salesforce AI, обеспечивает решение для эффективной обработки растущих объемов видеоданных. Эта модель направлена на повышение эффективности и эффективности понимания видео и широко используется в таких областях, как автономное вождение и развлечения, привнося инновации во все сферы жизни. Редактор Downcodes подробно объяснит основную технологию и превосходную производительность BLIP-3-Video.
Недавно исследовательская группа Salesforce AI запустила новую мультимодальную языковую модель — BLIP-3-Video. В связи с быстрым увеличением количества видеоконтента, эффективная обработка видеоданных стала актуальной проблемой, которую необходимо решить. Появление этой модели направлено на повышение эффективности и результативности понимания видео и подходит для различных отраслей — от автономного вождения до развлечений.
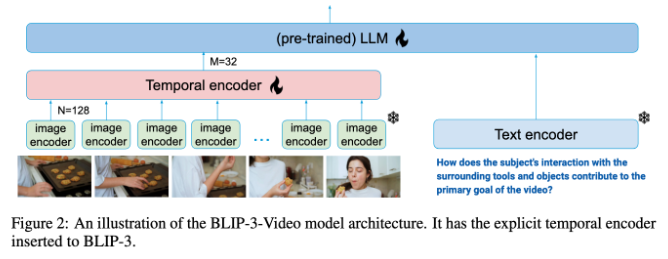
Традиционные модели понимания видео часто обрабатывают видео покадрово и генерируют большое количество визуальной информации. Этот процесс не только потребляет много вычислительных ресурсов, но и сильно ограничивает возможности обработки длинных видеороликов. Поскольку объем видеоданных продолжает расти, этот подход становится все более неэффективным, поэтому крайне важно найти решение, которое фиксирует ключевую информацию видео, одновременно снижая вычислительную нагрузку.
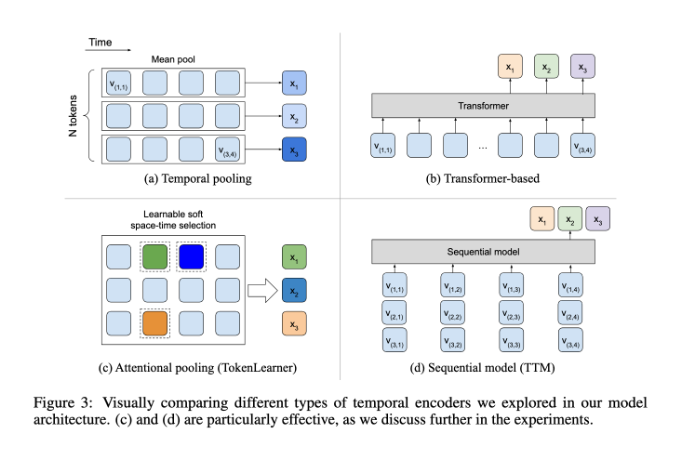
В этом плане BLIP-3-Video показывает себя неплохо. Эта модель успешно сокращает количество визуальной информации, необходимой в видео, до 16–32 визуальных маркеров за счет введения «временного кодировщика». Этот инновационный дизайн значительно повышает эффективность вычислений, позволяя модели выполнять сложные видеозадачи с меньшими затратами. Этот временной кодер использует обучаемый пространственно-временной механизм объединения внимания, который извлекает наиболее важную информацию из каждого кадра и интегрирует ее в компактный набор визуальных маркеров.
BLIP-3-Video также работает очень хорошо. Сравнивая с другими крупномасштабными моделями, исследование показало, что точность этой модели в задачах с ответами на видеовопросы сопоставима с точностью топ-моделей. Например, модели Tarsier-34B требуется 4608 маркеров для обработки 8 кадров видео, а BLIP-3-Video требуется только 32 маркера для достижения оценки MSVD-QA 77,7%. Это показывает, что BLIP-3-Video значительно снижает потребление ресурсов при сохранении высокой производительности.
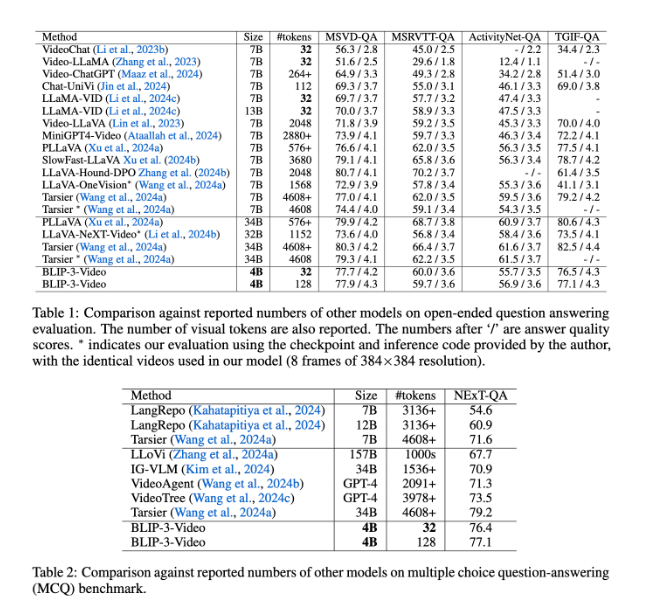
Кроме того, нельзя недооценивать эффективность BLIP-3-Video в задачах с вопросами и ответами с несколькими вариантами ответов. В наборе данных NExT-QA модель получила высокий балл 77,1%, а в наборе данных TGIF-QA она также достигла точности 77,1%. Эти данные демонстрируют эффективность BLIP-3-Video в решении сложных проблем с видео.

BLIP-3-Video открывает новые возможности обработки видео благодаря инновационному кодировщику времени. Запуск этой модели не только повышает эффективность понимания видео, но и предоставляет больше возможностей для будущих видеоприложений.
Вход в проект: https://www.salesforceairesearch.com/opensource/xGen-MM-Vid/index.html.
BLIP-3-Video обеспечивает новое направление для будущего развития видеотехнологий благодаря своим эффективным возможностям обработки видео. Его превосходная производительность в видеовопросах и ответах, а также в задачах вопросов и ответов с множественным выбором демонстрирует его огромный потенциал в экономии ресурсов и повышении производительности. Мы надеемся, что BLIP-3-Video сыграет свою роль в большем количестве областей и будет способствовать развитию видеотехнологий.