Редактор Downcodes расскажет вам о последних результатах исследований Принстонского и Йельского университетов! В этом исследовании глубоко изучаются возможности рассуждения «Цепочки мыслей (CoT)» больших языковых моделей (LLM), показывая, что рассуждение CoT — это не простое применение логических правил, а сложное сочетание множества факторов, таких как память, вероятность и шумовые рассуждения. Исследователи выбрали задачу взлома шифра сдвига и провели углубленный анализ трех LLM: GPT-4, Claude3 и Llama3.1. Наконец, они обнаружили три ключевых фактора, влияющих на эффект вывода CoT, и предложили механизм вывода LLM. новые идеи.
Исследователи из Принстонского и Йельского университетов недавно опубликовали отчет о возможностях рассуждения «Цепочки мыслей (CoT)» больших языковых моделей (LLM), раскрывая секрет рассуждений CoT: это не чисто символические рассуждения, основанные на логических правилах, а Он сочетает в себе несколько факторов, таких как память, вероятность и шумовые рассуждения.
Исследователи использовали взлом шифра сдвига в качестве тестового задания и проанализировали производительность трех LLM: GPT-4, Claude3 и Llama3.1. Шифр сдвига — это простая кодировка, при которой каждая буква заменяется буквой, сдвинутой вперед на фиксированное количество мест в алфавите. Например, переместите алфавит на 3 позиции вперед, и CAT станет FDW.
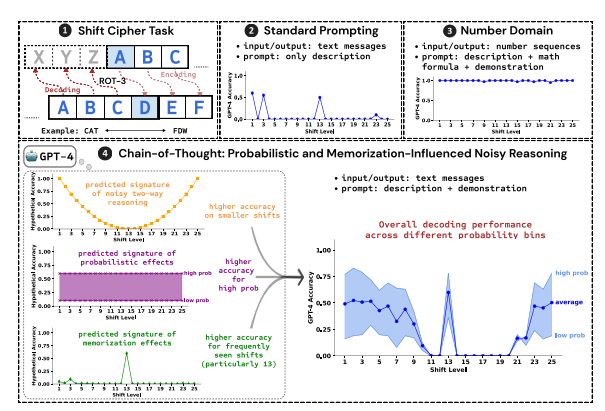
Результаты исследования показывают, что тремя ключевыми факторами, влияющими на эффект рассуждения ЦТ, являются:
Вероятностный: LLM предпочитает генерировать выходные данные с более высокой вероятностью, даже если этапы вывода приводят к ответам с более низкой вероятностью. Например, если шаг вывода указывает на STAZ, но слово STAY является более распространенным, LLM может «самоисправиться» и вывести STAY.
Память: LLM запоминает большой объем текстовых данных во время предварительного обучения, что влияет на точность вывода CoT. Например, rot-13 — наиболее распространенный сдвиговый шифр, а точность LLM на rot-13 значительно выше, чем у других типов сдвиговых шифров.
Вывод по шуму: процесс вывода LLM не совсем точен, но существует определенная степень шума. По мере увеличения величины сдвига шифра сдвига промежуточные шаги, необходимые для декодирования, также увеличиваются, и влияние вывода шума становится более очевидным, что приводит к снижению точности LLM.
Исследователи также обнаружили, что рассуждения LLM CoT основаны на самообусловливании, то есть LLM необходимо явно генерировать текст в качестве контекста для последующих шагов рассуждения. Если LLM дать указание «думать молча», не выводя никакого текста, его способность к рассуждению значительно снижается. Кроме того, эффективность демонстрационных шагов мало влияет на рассуждения ЦТ. Даже если на демонстрационных этапах есть ошибки, эффект рассуждения ЦТ от LLM все равно может оставаться стабильным.
Это исследование показывает, что рассуждения LLM CoT не являются идеальными символическими рассуждениями, а включают в себя множество факторов, таких как память, вероятность и шумовые рассуждения. LLM показывает характеристики как мастера памяти, так и мастера вероятности в процессе рассуждения CoT. Это исследование помогает нам глубже понять способности LLM к рассуждениям и дает ценную информацию для разработки более мощных систем искусственного интеллекта в будущем.
Адрес статьи: https://arxiv.org/pdf/2407.01687.
Этот исследовательский отчет предоставляет нам ценную информацию для понимания механизма рассуждения «мыслительной цепочки» больших языковых моделей, а также предлагает новое направление для проектирования и оптимизации будущих систем искусственного интеллекта. Редакция Downcodes продолжит уделять внимание передовым разработкам в области искусственного интеллекта и предлагать вам еще больше интересного контента!