Исследовательская группа Института компьютерных инноваций Чжэцзянского университета совершила прорыв в решении проблемы недостаточной способности больших языковых моделей обрабатывать табличные данные и запустила новую модель TableGPT2. Благодаря своему уникальному кодировщику таблиц TableGPT2 может эффективно обрабатывать различные табличные данные, внося революционные изменения в приложения, управляемые данными, такие как бизнес-аналитика (BI). Редактор Downcodes подробно объяснит инновации и будущее направление развития TableGPT2.
Появление больших языковых моделей (LLM) принесло революционные изменения в приложения искусственного интеллекта. Однако у них есть очевидные недостатки в обработке табличных данных. Чтобы решить эту проблему, исследовательская группа из Института компьютерных инноваций Университета Чжэцзян запустила новую модель под названием TableGPT2, которая может напрямую и эффективно интегрировать и обрабатывать табличные данные, открывая новые возможности для бизнес-аналитики (BI) и других методов, основанных на данных. приложения, новые возможности.
Основная инновация TableGPT2 заключается в уникальном кодировщике таблиц, который специально разработан для захвата структурной информации и информации о содержимом ячеек таблицы, тем самым улучшая способность модели обрабатывать нечеткие запросы, отсутствующие имена столбцов и нерегулярные таблицы, которые часто встречаются в реальной жизни. -мировые приложения. TableGPT2 основан на архитектуре Qwen2.5 и прошел масштабную предварительную подготовку и тонкую настройку, включающую более 593 800 таблиц и 2,36 миллиона высококачественных кортежей вывода таблиц запросов, что представляет собой беспрецедентный масштаб операций, связанных с таблицами. данные предыдущих исследований.
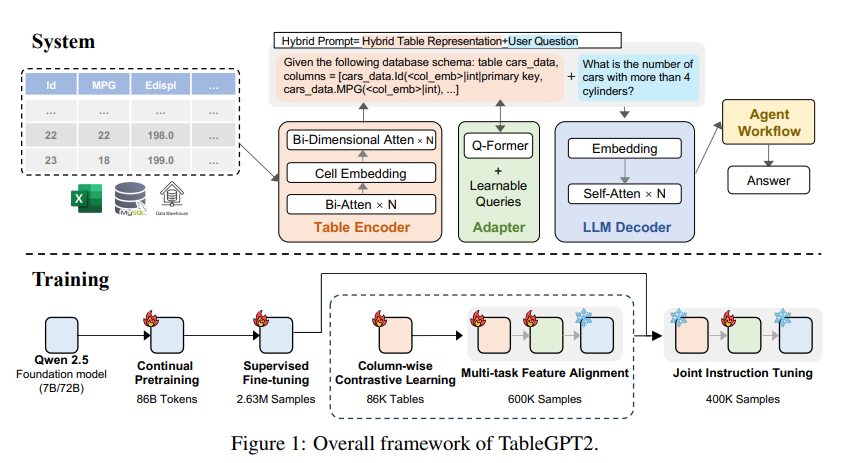
Чтобы улучшить возможности кодирования и рассуждения TableGPT2, исследователи провели непрерывное предварительное обучение (CPT), в котором 80% данных представляют собой тщательно аннотированный код, чтобы гарантировать его сильные возможности кодирования. Кроме того, они также собрали большое количество данных для вывода и учебников, содержащих знания по конкретной предметной области, чтобы расширить возможности вывода модели. Окончательные данные CPT содержат 86 миллиардов строго отфильтрованных токенов, что обеспечивает необходимые возможности кодирования и рассуждения для TableGPT2 для обработки сложных задач BI и других связанных задач.
Чтобы устранить ограничения TableGPT2 при адаптации к конкретным задачам и сценариям BI, исследователи выполнили контролируемую точную настройку (SFT). Они создали набор данных, охватывающий множество критических и реальных сценариев, включая несколько раундов разговоров, сложные рассуждения, использование инструментов и запросы, ориентированные на бизнес. Набор данных сочетает в себе ручное аннотирование с автоматическим процессом аннотирования под руководством экспертов, что обеспечивает качество и актуальность данных. Процесс SFT, в котором использовалось в общей сложности 2,36 миллиона образцов, еще больше усовершенствовал модель для удовлетворения конкретных потребностей BI и других сред, включающих таблицы.
TableGPT2 также представляет новаторский кодировщик семантических таблиц, который принимает всю таблицу в качестве входных данных и генерирует компактный набор векторов внедрения для каждого столбца. Эта архитектура настроена с учетом уникальных свойств табличных данных, эффективно фиксируя связи между строками и столбцами с помощью двунаправленного механизма внимания и иерархического процесса извлечения признаков. Кроме того, используется метод контрастного обучения по столбцам, чтобы побудить модель изучать значимые, структурированные табличные семантические представления.
Чтобы легко интегрировать TableGPT2 с инструментами анализа данных корпоративного уровня, исследователи также разработали среду выполнения рабочих процессов агента. Платформа состоит из трех основных компонентов: разработки подсказок во время выполнения, безопасной изолированной среды кода и модуля оценки агента, которые вместе повышают возможности и надежность агента. Рабочие процессы поддерживают сложные задачи анализа данных с помощью модульных шагов (нормализация входных данных, выполнение агента и вызов инструментов), которые работают вместе для управления и мониторинга производительности агента. Благодаря интеграции расширенной генерации извлечения (RAG) для эффективного контекстного поиска и изолированной программной среды кода для безопасного выполнения, платформа гарантирует, что TableGPT2 предоставляет точную, контекстно-зависимую информацию о реальных проблемах.
Исследователи провели обширную оценку TableGPT2 на различных широко используемых табличных тестах и тестах общего назначения. Результаты показывают, что TableGPT2 превосходно справляется с пониманием, обработкой и рассуждением таблиц со средним улучшением производительности на 35,20% для модели с 7 миллиардами параметров, 720. Средняя производительность модели со 100 миллионами параметров увеличилась на 49,32% при сохранении высоких общих показателей. Для справедливой оценки они сравнивали TableGPT2 только с моделями с открытым исходным кодом, нейтральными к тестам, такими как Qwen и DeepSeek, гарантируя сбалансированную и универсальную производительность модели при выполнении различных задач без переаттестации ни одного теста производительности. Они также представили и частично выпустили новый тест RealTabBench, который делает упор на нетрадиционные таблицы, анонимные поля и сложные запросы, чтобы лучше соответствовать реальным сценариям.
Несмотря на то, что TableGPT2 достигает высочайшего уровня производительности в экспериментах, все еще существуют проблемы с развертыванием LLM в реальных средах бизнес-аналитики. Исследователи отметили, что будущие направления исследований включают:
Кодирование, специфичное для предметной области: позволяет LLM быстро адаптировать языки (DSL) или псевдокод, специфичные для конкретного предприятия, для лучшего удовлетворения конкретных потребностей инфраструктуры данных предприятия.
Мультиагентное проектирование: узнайте, как эффективно интегрировать несколько LLM в единую систему, позволяющую справляться со сложными реальными приложениями.
Универсальная обработка таблиц: улучшите способность модели обрабатывать нестандартные таблицы, такие как объединенные ячейки и противоречивые структуры, распространенные в Excel и Pages, чтобы лучше обрабатывать различные формы табличных данных в реальном мире.
Запуск TableGPT2 знаменует собой значительный прогресс LLM в обработке табличных данных, открывая новые возможности для бизнес-аналитики и других приложений, управляемых данными. Я считаю, что по мере углубления исследований TableGPT2 будет играть все более важную роль в области анализа данных в будущем.
Адрес статьи: https://arxiv.org/pdf/2411.02059v1.
Появление TableGPT2 открыло новый рассвет в области бизнес-аналитики. Его эффективные возможности обработки табличных данных и высокая масштабируемость указывают на то, что анализ данных в будущем станет более интеллектуальным и удобным. Мы с нетерпением ожидаем, что TableGPT2 будет более широко использоваться в будущем и принесет большую ценность во все сферы жизни.