В крупномасштабных средах облачных вычислений даже небольшое снижение производительности может привести к огромной трате ресурсов. Перед Meta стоит задача эффективного обнаружения и решения этих тонких проблем с производительностью. С этой целью команда Meta AI разработала FBDetect, систему, которая может обнаруживать чрезвычайно небольшие снижения производительности в производственных средах с точностью даже 0,005%. Редактор Downcodes подробно познакомит вас с принципом работы и замечательными результатами FBDetect.
При управлении крупной облачной инфраструктурой даже небольшое снижение производительности может привести к значительной трате ресурсов. Например, в такой компании, как Meta, замедление работы приложения на 0,05% может показаться незначительным, но когда миллионы серверов работают одновременно, эта крошечная задержка может привести к тысячам потраченных впустую серверов. Поэтому своевременное обнаружение и устранение этих незначительных ухудшений производительности является огромной проблемой для Meta.

Чтобы решить эту проблему, Meta AI запустила FBDetect, систему обнаружения снижения производительности для производственных сред, которая может фиксировать малейшее снижение производительности, даже такое низкое, как 0,005%. FBDetect способен отслеживать около 800 000 временных рядов, охватывая множество показателей, таких как пропускная способность, задержка, использование ЦП и памяти, с участием сотен сервисов и миллионов серверов. Используя инновационные методы, такие как выборка трассировки стека по всему кластеру серверов, FBDetect способен улавливать тонкие различия в производительности на уровне подпрограмм.
FBDetect в основном фокусируется на анализе производительности на уровне подпрограмм, который может снизить сложность обнаружения с 0,05% регрессии на уровне приложения до более легко идентифицируемых 5% изменений на уровне подпрограмм. Такой подход значительно снижает шум, делая отслеживание изменений более практичным.
Техническое ядро FBDetect состоит из трех основных аспектов. Во-первых, он уменьшает дисперсию данных о производительности за счет обнаружения регрессии на уровне подпрограммы, так что небольшие регрессии можно выявить вовремя. Во-вторых, система выполняет выборку трассировки стека по всему кластеру серверов, чтобы точно измерить производительность каждой подпрограммы, аналогично анализу производительности в крупномасштабной среде. Наконец, для каждой обнаруженной регрессии FBDetect выполняет анализ первопричин, чтобы определить, вызвана ли регрессия временной проблемой, изменением стоимости или фактическим изменением кода.
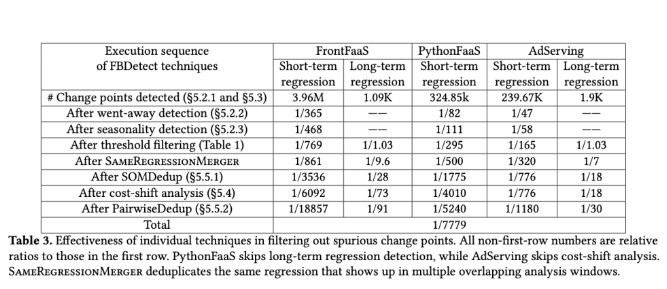
После семи лет тестирования в реальных производственных средах FBDetect обладает мощными возможностями защиты от помех и может эффективно фильтровать ложные сигналы регрессии. Внедрение данной системы позволит не только существенно сократить количество инцидентов, которые необходимо расследовать разработчикам, но и повысить эффективность мета-инфраструктуры. Обнаруживая небольшие регрессии, FBDetect помогает Meta избежать бесполезной траты ресурсов примерно на 4000 серверов в год.
На крупных предприятиях, таких как Meta, с миллионами серверов, обнаружение снижения производительности особенно важно. Благодаря своим расширенным возможностям мониторинга FBDetect не только повышает скорость выявления незначительных регрессий, но также предоставляет разработчикам эффективные методы анализа первопричин, которые помогают своевременно решать потенциальные проблемы, тем самым способствуя эффективной работе всей инфраструктуры.
Вход для бумаги: https://tangchq74.github.io/FBDetect-SOSP24.pdf.
Успешные примеры FBDetect предоставляют ценный опыт крупным предприятиям и открывают новые направления для разработки будущих систем мониторинга производительности. Его эффективное использование ресурсов и возможности точного обнаружения регрессии достойны внимания и изучения в отрасли. Будем надеяться, что появятся более инновационные технологии, подобные этой, которые помогут предприятиям лучше управлять и оптимизировать свою облачную инфраструктуру.