Редактор Downcodes узнал, что китайская исследовательская группа успешно создала крупнейший публичный мультимодальный набор данных ИИ «Infinity-MM» и на основе этого набора данных обучила небольшую модель Aquila-VL-2B с отличными характеристиками. Модель показала отличные результаты в многочисленных тестах производительности, продемонстрировав огромный потенциал синтетических данных в повышении производительности моделей ИИ. Набор данных Infinity-MM содержит различные типы данных, такие как описания изображений и данные визуальных инструкций. В процессе его создания используются модели искусственного интеллекта с открытым исходным кодом, такие как RAM++ и MiniCPM-V, и подвергается многоуровневой обработке для обеспечения качества и разнообразия данных. Модель Aquila-VL-2B основана на архитектуре LLaVA-OneVision и использует Qwen-2.5 в качестве языковой модели.
Недавно исследовательские группы из нескольких китайских институтов успешно создали набор данных «Infinity-MM», который в настоящее время является одним из крупнейших общедоступных наборов данных мультимодального ИИ, и обучили небольшую новую модель с отличными характеристиками — Aquila-VL-2B. .
Набор данных в основном содержит четыре основные категории данных: 10 миллионов описаний изображений, 24,4 миллиона общих данных визуальных инструкций, 6 миллионов выбранных данных высококачественных инструкций и 3 миллиона данных, сгенерированных GPT-4 и другими моделями искусственного интеллекта.
Что касается генерации, исследовательская группа использовала существующие модели искусственного интеллекта с открытым исходным кодом. Сначала модель RAM++ анализирует изображение и извлекает важную информацию, впоследствии генерируя соответствующие вопросы и ответы. Кроме того, команда создала специальную систему классификации, чтобы обеспечить качество и разнообразие генерируемых данных.
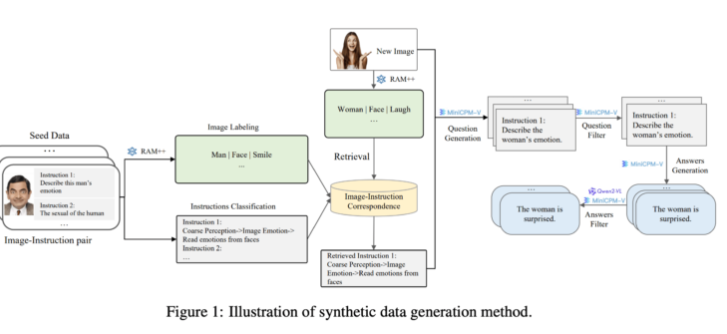
Этот метод генерации синтетических данных использует метод многоуровневой обработки, объединяющий модели RAM++ и MiniCPM-V для предоставления точных данных обучения для системы искусственного интеллекта посредством распознавания изображений, классификации инструкций и генерации ответов.
Модель Aquila-VL-2B основана на архитектуре LLaVA-OneVision, использует Qwen-2.5 в качестве языковой модели и использует SigLIP для обработки изображений. Обучение модели разбито на четыре этапа с постепенным увеличением сложности. На первом этапе модель изучает основные ассоциации изображения и текста; последующие этапы включают задачи общего зрения, выполнение конкретных инструкций и, наконец, интеграцию синтезированных сгенерированных данных. Разрешение изображения также постепенно улучшается во время обучения.
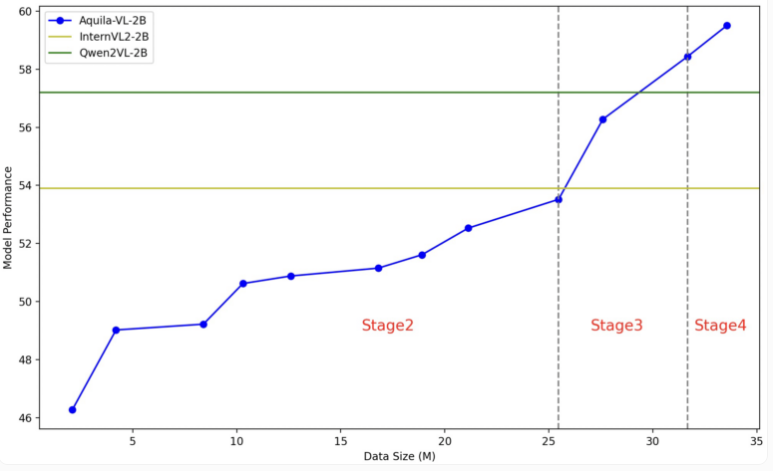
В тесте Aquila-VL-2B показал лучший результат в мультимодальном тесте на базе MMStar с результатом 54,9%, при объеме всего 2 миллиарда параметров. Кроме того, модель особенно хорошо показала себя в математических задачах, набрав 59% в тесте MathVista, что намного превосходит аналогичные системы.
В общем тесте на понимание изображения Aquila-VL-2B также показал хорошие результаты: балл по HallusionBench составил 43%, а по MMBench — 75,2%. Исследователи заявили, что добавление синтетически сгенерированных данных значительно улучшило производительность модели. Без использования этих дополнительных данных средняя производительность модели упала бы на 2,4%.
На этот раз исследовательская группа решила открыть набор данных и модель исследовательскому сообществу. В процессе обучения в основном использовались графические процессоры Nvidia A100 и местные китайские чипы. Успешный запуск Aquila-VL-2B означает, что модели с открытым исходным кодом постепенно догоняют тенденцию традиционных систем с закрытым исходным кодом в исследованиях ИИ, особенно показывая хорошие перспективы в использовании синтетических обучающих данных.
Вход в статью «Инфинити-ММ»: https://arxiv.org/abs/2410.18558
Вход в проект Aquila-VL-2B: https://huggingface.co/BAAI/Aquila-VL-2B-llava-qwen
Успех Aquila-VL-2B не только доказывает техническую мощь Китая в области искусственного интеллекта, но и предоставляет ценные ресурсы сообществу открытого исходного кода. Его эффективная работа и открытая стратегия будут способствовать развитию мультимодальной технологии искусственного интеллекта, и стоит с нетерпением ждать ее будущего применения в других областях.