Новое исследование Массачусетского технологического института выявило поразительное сходство между внутренней структурой больших языковых моделей (LLM) и человеческим мозгом, что вызвало горячие споры в области искусственного интеллекта. Редактор Downcodes подробно объяснит революционные результаты этого исследования и их значение для будущего развития ИИ. Благодаря углубленному анализу пространства активации LLM исследователи обнаружили трехуровневые структурные особенности. Открытие этих особенностей поможет нам лучше понять механизм работы LLM и указать новые направления для развития будущих технологий искусственного интеллекта.
ИИ действительно начал «выращивать мозг»?! Последние исследования Массачусетского технологического института показывают, что внутренняя структура модели большого языка (LLM) удивительно похожа на человеческий мозг!
В этом исследовании использовалась технология разреженного автоэнкодера для проведения углубленного анализа пространства активации LLM и были обнаружены три уровня удивительных структурных особенностей:
Сначала на микроскопическом уровне исследователи обнаружили существование «кристаллических» структур. Грани этих «кристаллов» состоят из параллелограммов или трапеций, похожих на знакомые словесные аналогии, такие как «мужчина:женщина::король:королева».

Что еще более удивительно, так это то, что эти «кристаллические» структуры становятся более четкими после удаления некоторых нерелевантных мешающих факторов (таких как длина слова) с помощью методов линейного дискриминантного анализа.
Во-вторых, на мезоуровне исследователи обнаружили, что пространство активации LLM имеет модульную структуру, аналогичную функциональным отделам человеческого мозга.
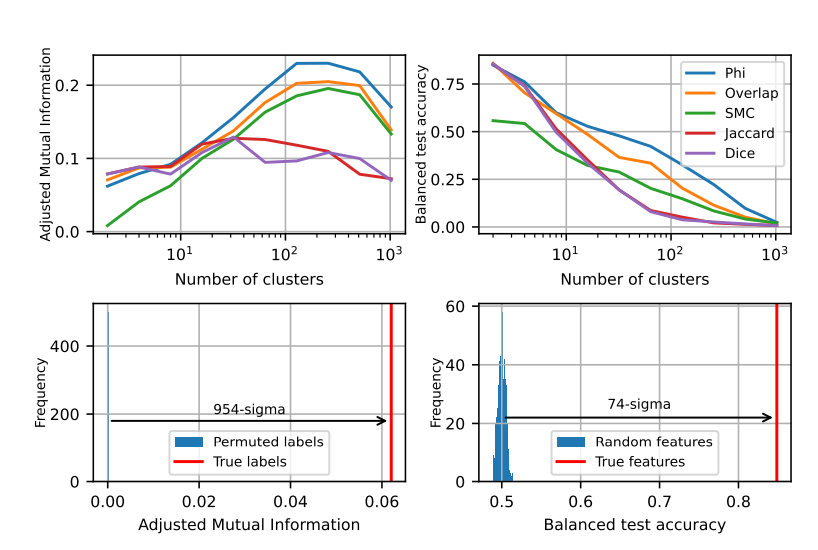
Например, функции, связанные с математикой и программированием, группируются вместе, образуя «долю», аналогичную функциональным долям человеческого мозга. Посредством количественного анализа нескольких индикаторов исследователи подтвердили пространственную локализацию этих «долей», показав, что одновременно встречающиеся признаки также более пространственно сгруппированы, что намного превосходит то, что можно было бы ожидать от случайного распределения.
На макроуровне исследователи обнаружили, что общая структура облака точек признаков LLM не изотропна, а представляет собой степенное распределение собственных значений, и это распределение наиболее очевидно в среднем слое.
Исследователи также количественно проанализировали энтропию кластеризации разных уровней и обнаружили, что энтропия кластеризации среднего слоя была ниже, что указывает на то, что представление объекта было более концентрированным, в то время как энтропия кластеризации раннего и позднего слоев была выше, что указывает на то, что признак представительство было более рассредоточенным.
Это исследование дает нам новый взгляд на понимание внутренних механизмов больших языковых моделей, а также закладывает основу для разработки более мощных и интеллектуальных систем искусственного интеллекта в будущем.
Этот результат исследования является захватывающим. Он не только углубляет наше понимание крупномасштабных языковых моделей, но и указывает на новое направление будущего развития искусственного интеллекта. Редактор Downcodes считает, что благодаря постоянному развитию технологий искусственный интеллект проявит свой мощный потенциал во многих областях и принесет лучшее будущее человеческому обществу.