Понимание сверхдлинного видео всегда было сложной проблемой для мультимодальных моделей большого языка (MLLM). Существующие модели с трудом обрабатывают видеоданные, длина которых превышает максимальную длину контекста, а затухание информации и высокие вычислительные затраты также являются серьезной проблемой. Редактор Downcodes узнал, что Чжиюаньский научно-исследовательский институт и несколько университетов предложили сверхдлинную модель визуального языка под названием Video-XL, которая предназначена для эффективного решения проблем с пониманием видео на часовом уровне. Основная технология этой модели — «скрытая сводка визуального контекста», которая умело использует возможности контекстного моделирования LLM для сжатия длинных визуальных представлений в более компактную форму, аналогично сжатию целой коровы в миску с говяжьей эссенцией, что делает модель более эффективно усваивать ключевую информацию.
В настоящее время мультимодальные модели большого языка (MLLM) добились значительного прогресса в области понимания видео, но обработка чрезвычайно длинных видео по-прежнему остается сложной задачей. Это связано с тем, что MLLM обычно с трудом справляется с обработкой тысяч визуальных токенов, длина которых превышает максимальную длину контекста, и страдает от разрушения информации, вызванного агрегацией токенов. В то же время большое количество видеотегов также приведет к высоким вычислительным затратам.
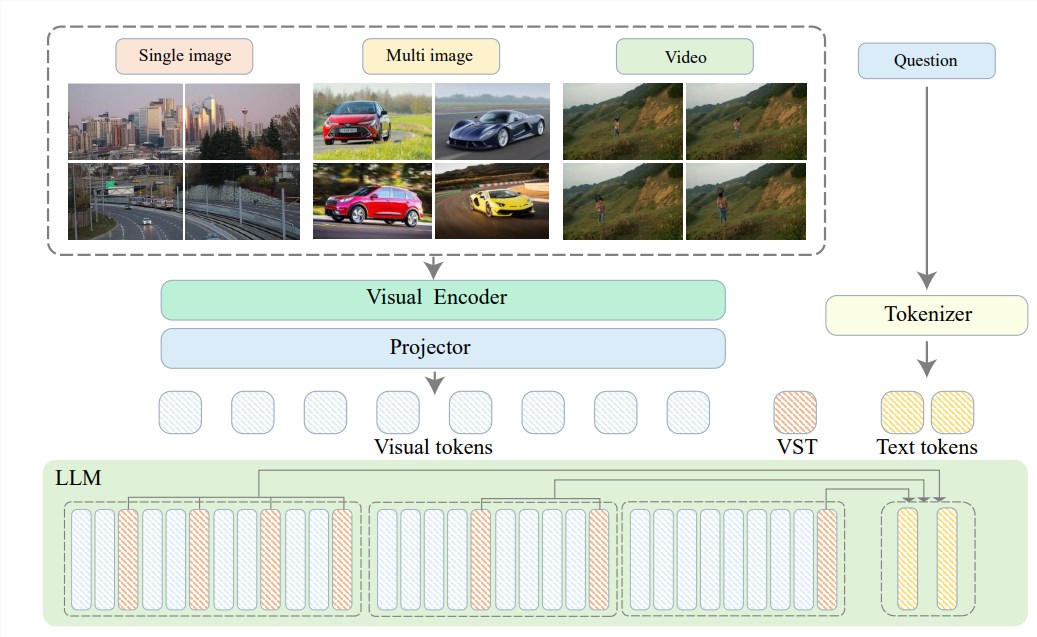
Чтобы решить эти проблемы, Чжиюаньский научно-исследовательский институт объединился с Шанхайским университетом Цзяо Тун, Китайским университетом Жэньминь, Пекинским университетом, Пекинским университетом почты и телекоммуникаций и другими университетами, чтобы предложить Video-XL, систему сверхвысокой четкости, предназначенную для эффективное понимание видео на часовом уровне. Модель длинного визуального языка. В основе Video-XL лежит технология «скрытого обобщения визуального контекста», которая использует встроенные в LLM возможности контекстного моделирования для эффективного сжатия длинных визуальных представлений в более компактную форму.
Проще говоря, это сжатие видеоконтента в более упорядоченную форму, аналогично сжатию целой коровы в миску с говяжьей эссенцией, которую модели легче переварить и усвоить.
Эта технология сжатия не только повышает эффективность, но и эффективно сохраняет ключевую информацию видео. Знаете, длинные видео часто наполнены массой лишней информации, как портянка старушки, длинная и вонючая. Video-XL может точно исключить эту бесполезную информацию и сохранить только самые важные части, что гарантирует, что модель не заблудится при понимании длинного видеоконтента.
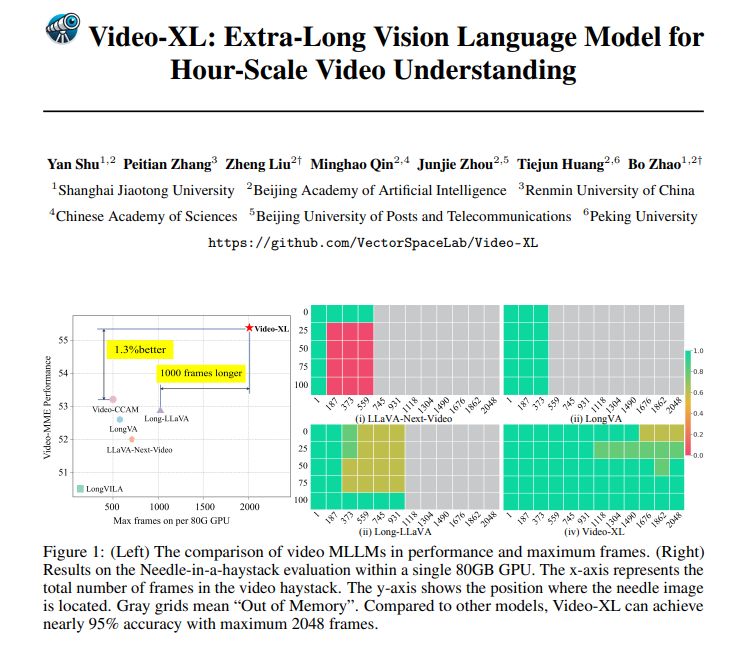
Video-XL не только великолепен в теории, но и весьма эффективен на практике. Video-XL добился лучших результатов в нескольких тестах на понимание длинных видео, особенно в тесте VNBench, где его точность почти на 10% выше, чем у лучших существующих методов.
Еще более впечатляюще то, что Video-XL обеспечивает удивительный баланс между эффективностью и результативностью, способный обрабатывать 2048 кадров видео на одном графическом процессоре емкостью 80 ГБ, сохраняя при этом точность почти 95% при оценке «иголки в стоге сена».
Video-XL также имеет широкие перспективы применения. Помимо способности понимать обычные длинные видео, он также способен решать конкретные задачи, такие как обобщение фильмов, обнаружение аномалий наблюдения и распознавание размещения рекламы.
Это означает, что вам больше не придется терпеть длинные сюжеты при просмотре фильмов в будущем. Вы можете напрямую использовать Video-XL для создания упрощенного резюме, экономя время и усилия, или вы можете использовать его для мониторинга записей наблюдения и автоматического выявления аномальных событий; , что намного эффективнее, чем отслеживание вручную.
Адрес проекта: https://github.com/VectorSpaceLab/Video-XL
Документ: https://arxiv.org/pdf/2409.14485.
Video-XL добился революционного прогресса в области распознавания сверхдлинных видео. Его идеальное сочетание эффективности и точности обеспечивает новое решение для обработки длинного видео. Оно имеет широкие перспективы применения в будущем и заслуживает внимания!