Редактор Downcodes узнал, что Пекинский университет и другие научно-исследовательские группы выпустили LLaVA-o1, знаковую мультимодальную модель с открытым исходным кодом. Модель превзошла конкурентов, таких как Gemini, GPT-4o-mini и Llama, в нескольких тестах производительности, а ее механизм «медленного мышления» позволил ей выполнять более сложные рассуждения, сравнимые с GPT-o1. Открытый исходный код LLaVA-o1 придаст новую жизнь исследованиям и применениям в области мультимодального искусственного интеллекта.
Недавно Пекинский университет и другие научно-исследовательские группы объявили о выпуске мультимодальной модели с открытым исходным кодом под названием LLaVA-o1, которая считается первой моделью визуального языка, способной к спонтанным и систематическим рассуждениям, сравнимым с GPT-o1.
Модель хорошо показала себя в шести сложных мультимодальных тестах, причем ее версия с 11B параметрами превосходит других конкурентов, таких как Gemini-1.5-pro, GPT-4o-mini и Llama-3.2-90B-Vision-Instruct.
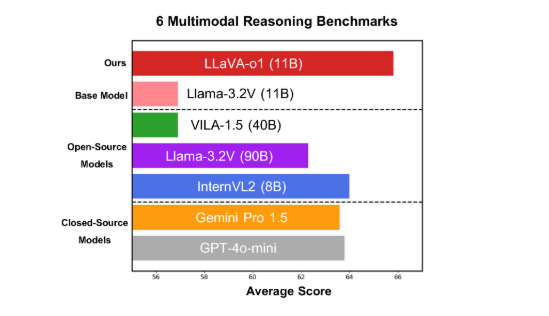
LLaVA-o1 основан на модели Llama-3.2-Vision и использует механизм рассуждения «медленного мышления», который может независимо выполнять более сложные процессы рассуждения, превосходя традиционный метод подсказки цепочки мышления.
В тесте мультимодального вывода LLaVA-o1 превзошел базовую модель на 8,9%. Модель уникальна тем, что процесс ее рассуждения разделен на четыре этапа: подведение итогов, визуальное объяснение, логическое рассуждение и формирование выводов. В традиционных моделях процесс рассуждения часто относительно прост и может легко привести к неверным ответам, в то время как LLaVA-o1 обеспечивает более точные результаты за счет структурированного многоэтапного рассуждения.
Например, при решении задачи «Сколько предметов осталось после вычитания всех маленьких ярких шариков и фиолетовых предметов?» LLaVA-o1 сначала суммирует задачу, затем извлекает информацию из изображения, затем выполняет пошаговые рассуждения. и, наконец, дать ответ. Такой поэтапный подход улучшает возможности модели по систематическому рассуждению, делая ее более эффективной в решении сложных проблем.

Стоит отметить, что LLaVA-o1 представляет метод поиска луча на уровне этапа в процессе вывода. Этот подход позволяет модели генерировать несколько вариантов ответов на каждом этапе вывода и выбирать лучший ответ для перехода к следующему этапу вывода, тем самым значительно улучшая общее качество вывода. Благодаря контролируемой точной настройке и разумным данным обучения LLaVA-o1 работает лучше по сравнению с более крупными моделями или моделями с закрытым исходным кодом.
Результаты исследований команды Пекинского университета не только способствуют развитию мультимодального искусственного интеллекта, но также предоставляют новые идеи и методы для будущих моделей визуального понимания языка. Команда заявила, что код, веса предварительного обучения и наборы данных LLaVA-o1 будут полностью открытыми, и они надеются, что больше исследователей и разработчиков будут совместно изучать и применять эту инновационную модель.
Статья: https://arxiv.org/abs/2411.10440.
GitHub: https://github.com/PKU-YuanGroup/LLaVA-o1
Открытый исходный код LLaVA-o1, несомненно, будет способствовать технологическому развитию и инновациям в области мультимодального искусственного интеллекта. Его эффективный механизм вывода и отличная производительность делают его важным справочником для будущих исследований моделей визуального языка и заслуживают внимания и ожидания. Мы надеемся, что больше разработчиков примут участие и будут совместно способствовать развитию технологий искусственного интеллекта.