В последние годы сфера искусственного интеллекта с открытым исходным кодом переживает бум, но по-прежнему существует разрыв с крупными технологическими компаниями. Вычислительная мощность — это только один аспект, и более важным аспектом является отсутствие решений для постобучения. Последний прорыв AI2 (ранее Институт искусственного интеллекта Аллена) — программа постобучения Tülu3 — является мощным оружием, позволяющим ликвидировать этот разрыв. Редактор Downcodes даст вам глубокое понимание того, как эта технология расширяет возможности искусственного интеллекта с открытым исходным кодом и делает большие языковые модели, которыми изначально было трудно управлять, простыми в использовании и настройке.
В области искусственного интеллекта с открытым исходным кодом разрыв с крупными технологическими компаниями отражается не только в вычислительной мощности. AI2 (бывший Институт искусственного интеллекта Аллена) устраняет этот пробел посредством ряда новаторских инициатив. Его недавно выпущенная программа постобучения Tülu3 позволяет преобразовать оригинальные большие языковые модели в практические системы искусственного интеллекта.
В отличие от обычного познания, базовые языковые модели нельзя использовать непосредственно после предварительного обучения. По сути, процесс постобучения является ключевым звеном, определяющим конечную ценность модели. Именно на этом этапе модель трансформируется из всезнающей сети, лишенной суждений, в практический инструмент с определенной функциональной ориентацией.
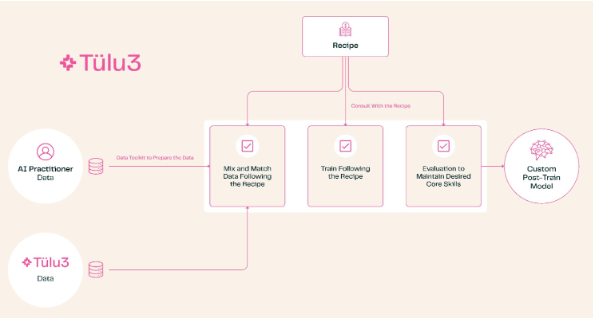
Долгое время крупные компании скрывали программы постобучения. Хотя каждый может построить модель, используя новейшие технологии, необходимы уникальные методы постобучения, чтобы сделать модель полезной в конкретных областях, таких как психологическое консультирование или исследовательский анализ. Даже для таких проектов, как Meta's Llama, который рекламируется как открытый исходный код, источник исходной модели и общих методов обучения по-прежнему строго конфиденциальен.
Появление Tülu3 меняет эту ситуацию. Этот полный набор решений для постобучения охватывает весь спектр процессов: от выбора темы до управления данными, от обучения с подкреплением до тонкой настройки. Пользователи могут настраивать возможности модели в соответствии со своими потребностями, например, расширяя возможности математики и программирования или снижая приоритет многоязычной обработки.
Тест AI2 показывает, что производительность модели, обученной Tülu3, достигла уровня лучших моделей с открытым исходным кодом. Этот прорыв значителен: он предоставляет компаниям полностью автономный и контролируемый выбор. Специально для учреждений, которые обрабатывают конфиденциальные данные, такие как медицинские исследования, им больше не нужно полагаться на сторонние API или специализированные услуги. Они могут завершить весь процесс обучения локально, экономя затраты и защищая конфиденциальность.
AI2 не только выпустила это решение, но и стала инициатором его применения в своих продуктах. Хотя текущие результаты тестов основаны на модели Llama, у них есть планы запустить новую модель, основанную на их собственной OLMo и обученную Tülu3, которая будет действительно полностью открытым решением от начала до конца.
Эта технология с открытым исходным кодом не только демонстрирует решимость AI2 способствовать демократизации ИИ, но и дает импульс всему сообществу ИИ с открытым исходным кодом. Это приближает нас на один шаг к по-настоящему открытой и прозрачной экосистеме искусственного интеллекта.
Открытый исходный код Tülu3 знаменует собой большой шаг вперед в области искусственного интеллекта с открытым исходным кодом. Он снижает порог для приложений искусственного интеллекта, способствует справедливости и совместному использованию технологий искусственного интеллекта и открывает неограниченные возможности для будущего развития искусственного интеллекта. Мы с нетерпением ждем появления новых подобных проектов с открытым исходным кодом для совместного создания более процветающей экосистемы искусственного интеллекта.