Вам интересны технологии, лежащие в основе продуктов искусственного интеллекта, таких как ChatGPT и Wenxinyyan? Все они полагаются на большие языковые модели (LLM). Редактор Downcodes поможет вам понять принцип работы LLM простым и понятным способом. Даже если у вас есть уровень математики только второго класса, вы легко это поймете! Мы начнем с базовых концепций нейронных сетей и постепенно объясним обучение моделей, передовые методы и основные технологии, такие как архитектура GPT и Transformer, чтобы у вас было четкое представление о LLM.
Слышали ли вы о продвинутых ИИ, таких как ChatGPT и Wen XiNYyan? Основная технология, лежащая в их основе, — «большая языковая модель» (LLM). Вам кажется, что это сложно и трудно понять? Не волнуйтесь, даже если у вас уровень математики только второго класса, вы легко поймете принцип работы LLM, прочитав эту статью!
Нейронные сети: магия чисел
Во-первых, нам нужно знать, что нейронная сеть похожа на суперкомпьютер: она может обрабатывать только числа. И входные, и выходные данные должны быть числами. Так как же нам заставить его понимать текст?
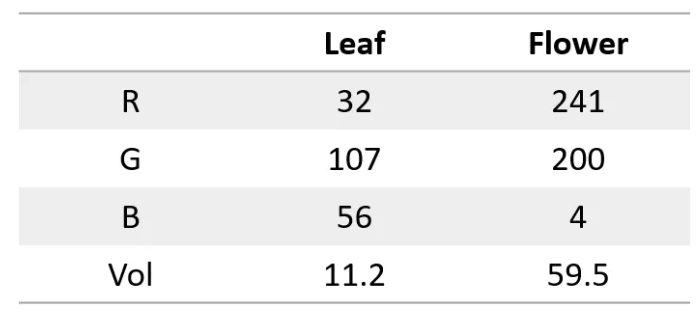
Секрет в том, чтобы преобразовать слова в числа! Например, мы можем представить каждую букву цифрой, например a=1, b=2 и так далее. Таким образом нейронная сеть может «прочитать» текст.
Обучение модели: дайте сети «выучить» язык
В случае с цифровым текстом следующим шагом будет обучение модели и предоставление возможности нейронной сети «изучить» правила языка.
Процесс обучения похож на игру в угадайку. Мы показываем сети какой-нибудь текст, например «Шалтай-Болтай», и просим ее угадать, какая будет следующая буква. Если он угадает правильно, мы даем ему награду; если он угадает неправильно, мы даем ему штраф. Постоянно угадывая и корректируя, сеть может предсказывать следующую букву с возрастающей точностью, в конечном итоге создавая полные предложения, такие как «Шалтай-Болтай сидел на стене».
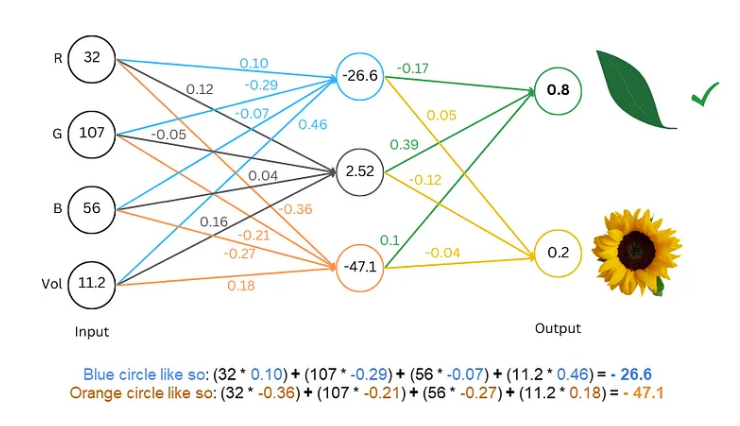
Продвинутые методы: сделайте модель более «умной»
Чтобы сделать модель более «умной», исследователи изобрели множество передовых технологий, таких как:
Встраивание слов: вместо использования простых чисел для обозначения букв мы используем набор чисел (векторов) для представления каждого слова, что может более полно описать значение слова.
Сегментатор подслов: разделяйте слова на более мелкие единицы (подслова), например, разделяя «кошки» на «кошки» и «ы», что может сократить словарный запас и повысить эффективность.
Механизм самообслуживания: когда модель предсказывает следующее слово, она корректирует вес прогноза на основе всех слов в контексте, точно так же, как мы понимаем значение слова на основе контекста при чтении.
Остаточное соединение. Чтобы избежать трудностей с обучением, вызванных слишком большим количеством сетевых слоев, исследователи изобрели остаточное соединение, чтобы облегчить изучение сети.
Механизм внимания с несколькими головами: за счет параллельного запуска нескольких механизмов внимания модель может понимать контекст с разных точек зрения и повышать точность прогнозов.
Позиционное кодирование: чтобы модель понимала порядок слов, исследователи добавляют позиционную информацию к встраиваниям слов, точно так же, как мы обращаем внимание на порядок слов при чтении.
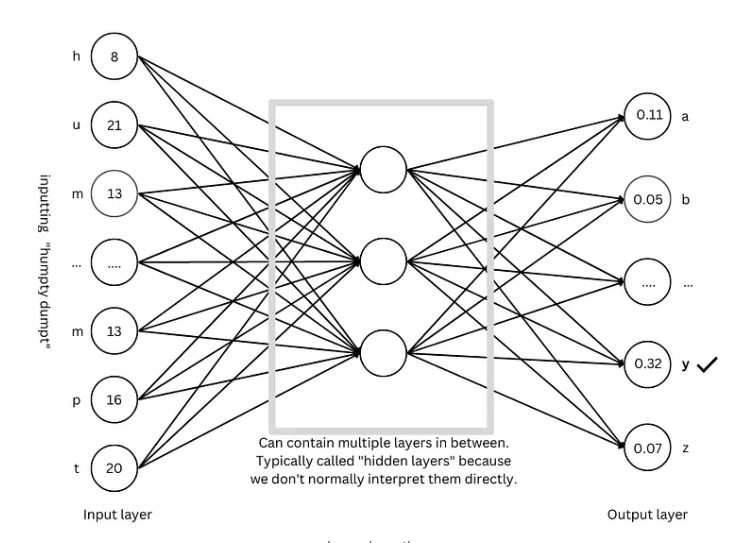
Архитектура GPT: «чертеж» крупномасштабных языковых моделей
Архитектура GPT в настоящее время является одной из самых популярных крупномасштабных архитектур языковых моделей. Это своего рода «чертеж», которым руководствуются при проектировании и обучении модели. Архитектура GPT умело сочетает в себе вышеупомянутые передовые методы, позволяющие модели эффективно изучать и генерировать язык.
Архитектура-трансформер: «революция» языковых моделей
Архитектура Transformer — это крупный прорыв в области языковых моделей за последние годы. Она не только повышает точность прогнозирования, но и снижает сложность обучения, закладывая основу для разработки крупномасштабных языковых моделей. Архитектура GPT также развивалась на основе архитектуры Transformer.
Ссылка: https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876.
Надеюсь, что пояснения редактора Downcodes помогут вам понять принципы работы больших языковых моделей. Конечно, технология LLM все еще развивается. Эта статья — лишь верхушка айсберга. Все более и более углубленное содержание требует от вас продолжения обучения и изучения.