Редактор Downcodes узнал, что Meta недавно выпустила новую многоязычную команду многоповоротного диалога после эталонного теста оценки способностей Multi-IF. Тест охватывает восемь языков и содержит 4501 трехэтапное диалоговое задание, направленное на более полную оценку больших. производительность языковых моделей (LLM) в практических приложениях. В отличие от существующих стандартов оценки, которые в основном ориентированы на одноэтапный диалог и одноязычные задачи, Multi-IF фокусируется на изучении возможностей модели в сложных многоходовых и многоязычных сценариях, обеспечивая более четкое направление для совершенствования LLM.
Meta недавно выпустила новый эталонный тест под названием Multi-IF, который предназначен для оценки способности моделей большого языка (LLM) следовать инструкциям в многоходовых диалогах и многоязычных средах. Этот тест охватывает восемь языков и содержит 4501 трехходовую диалоговую задачу, ориентированную на производительность текущих моделей в сложных многоходовых и многоязычных сценариях.
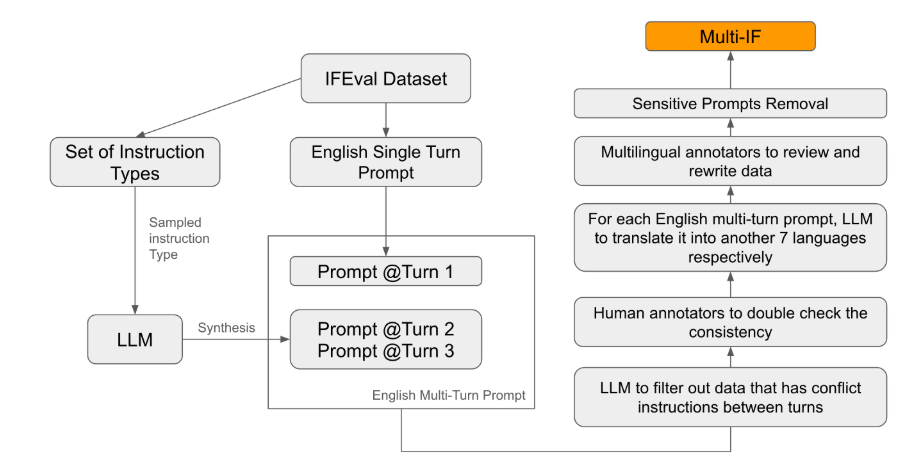
Среди существующих стандартов оценки большинство сосредоточено на одноэтапном диалоге и одноязычных задачах, которые трудно полностью отразить эффективность модели в практическом применении. Запуск Multi-IF призван восполнить этот пробел. Исследовательская группа создала сложные сценарии диалога, расширив один раунд инструкций на несколько раундов инструкций и гарантируя, что каждый раунд инструкций был логически последовательным и последовательным. Кроме того, набор данных также обеспечивает многоязычную поддержку за счет таких шагов, как автоматический перевод и ручная корректура.
Результаты экспериментов показывают, что эффективность большинства LLM значительно падает в течение нескольких раундов диалога. Если взять в качестве примера модель o1-preview, ее средняя точность в первом раунде составила 87,7%, но упала до 70,7% в третьем раунде. Особенно на языках с нелатинской графикой, таких как хинди, русский и китайский, производительность модели в целом ниже, чем у английского, что демонстрирует ограничения в многоязычных задачах.
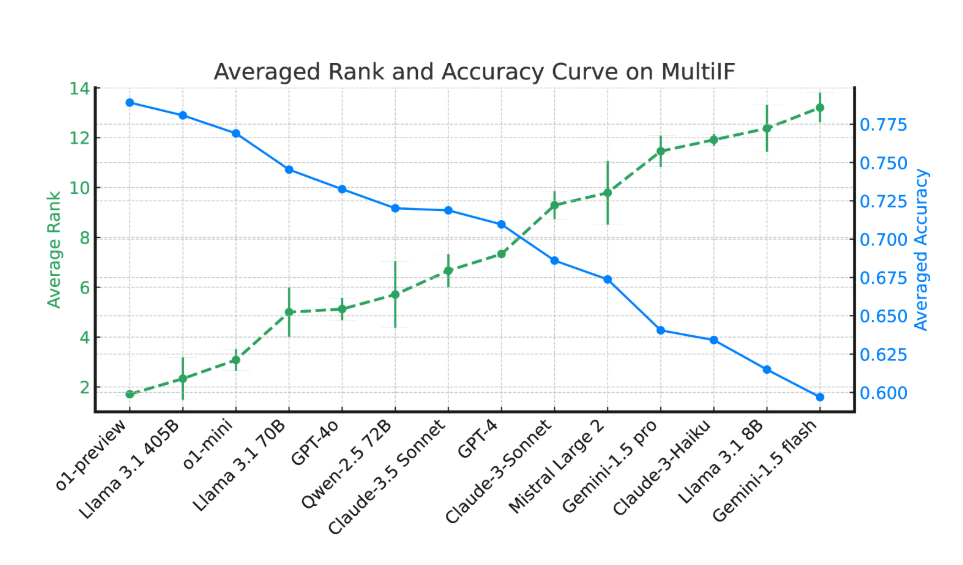
При оценке 14 передовых языковых моделей наилучшие результаты показали o1-preview и Llama3.1405B со средними показателями точности 78,9% и 78,1% в трех раундах инструкций соответственно. Однако в ходе нескольких раундов диалога все модели продемонстрировали общее снижение способности следовать инструкциям, что отражает проблемы, с которыми сталкиваются модели при выполнении сложных задач. Исследовательская группа также представила «коэффициент забывания инструкций» (IFR) для количественной оценки феномена забывания инструкций моделью в нескольких раундах диалога. Результаты показывают, что высокопроизводительные модели работают в этом отношении относительно хорошо.
Выпуск Multi-IF предоставляет исследователям сложный тест и способствует развитию LLM в сфере глобализации и многоязычных приложений. Запуск этого теста не только выявляет недостатки текущих моделей в многораундовых и многоязычных задачах, но и дает четкое направление для будущих улучшений.
Документ: https://arxiv.org/html/2410.15553v2.
Выпуск эталонного теста Multi-IF предоставляет важную информацию для исследования больших языковых моделей в многоходовом диалоге и многоязычной обработке, а также указывает путь для будущих улучшений моделей. Ожидается, что в будущем появятся все более и более мощные программы LLM, которые смогут лучше справляться с проблемами сложных многоэтапных многоязычных задач.