Команда Emu3 из исследовательского института Чжиюань выпустила революционную мультимодальную модель Emu3, которая подрывает традиционную мультимодальную архитектуру модели, обучается только на основе предсказания следующего токена и достигает производительности SOTA в задачах генерации и восприятия. Команда Emu3 умело разбивает изображения, текст и видео на отдельные пространства и обучает единую модель Transformer на смешанных мультимодальных последовательностях, достигая унификации мультимодальных задач, не полагаясь на диффузионную или комбинированную архитектуру, которая обеспечивает множество модальных полей. новые прорывы.
Команда Emu3 из исследовательского института Чжиюань выпустила новую мультимодальную модель Emu3. Эта модель обучается только на основе прогнозирования следующего токена, подрывая традиционную модель диффузии и архитектуру комбинированной модели и достигая результатов как в задачах генерации, так и в задачах восприятия. -художественное исполнение.
Прогнозирование следующего токена долгое время считалось многообещающим путем к общему искусственному интеллекту (AGI), но оно плохо справлялось с мультимодальными задачами. В настоящее время в мультимодальной области по-прежнему доминируют диффузионные модели (например, стабильная диффузия) и комбинированные модели (например, комбинация CLIP и LLM). Команда Emu3 разбивает изображения, текст и видео на отдельные пространства и обучает одну модель Transformer с нуля на смешанных мультимодальных последовательностях, тем самым объединяя мультимодальные задачи, не полагаясь на диффузионную или комбинационную архитектуру.
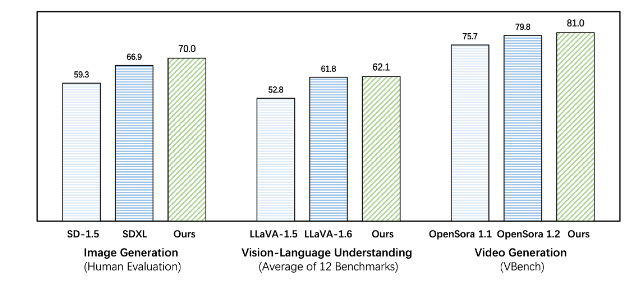
Emu3 превосходит существующие модели для конкретных задач как в задачах генерации, так и в задачах восприятия, даже превосходя флагманские модели, такие как SDXL и LLaVA-1.6. Emu3 также может генерировать видео высокой точности, предсказывая следующий токен в видеопоследовательности. В отличие от Sora, которая использует модель диффузии видео для генерации видео из шума, Emu3 генерирует видео причинным образом, предсказывая следующий токен в видеопоследовательности. Модель может имитировать определенные аспекты реальной среды, людей и животных и предсказывать, что произойдет дальше, учитывая контекст видео.
Emu3 упрощает разработку сложных мультимодальных моделей и фокусируется на токенах, открывая огромный потенциал масштабирования во время обучения и вывода. Результаты исследования показывают, что предсказание следующего токена является эффективным способом построения общего мультимодального интеллекта за пределами языка. Для поддержки дальнейших исследований в этой области команда Emu3 имеет ключевые технологии и модели с открытым исходным кодом, в том числе мощный визуальный токенизатор, который может конвертировать видео и изображения в дискретные токены, которые ранее не были общедоступными.
Успех Emu3 указывает направление будущего развития мультимодальных моделей и вселяет новую надежду на реализацию AGI.
Адрес проекта: https://github.com/baaivision/Emu3
Редактор Downcodes подводит итог: Появление модели Emu3 знаменует собой новую веху в мультимодальной области. Его простая архитектура и высокая производительность открывают новые идеи и направления для будущих исследований AGI. Стратегия открытого исходного кода также способствует совместному развитию научных кругов и промышленности. Стоит ожидать новых прорывов в будущем!