За последние годы искусственный интеллект добился значительного прогресса в различных областях, но его способность к математическому мышлению всегда была узким местом. Сегодня появление нового теста под названием FrontierMath предоставляет новый критерий для оценки математических возможностей ИИ. Он расширяет возможности ИИ в области математического рассуждения до беспрецедентных пределов и ставит серьезные проблемы перед существующими моделями ИИ. Редактор Downcodes поможет вам глубже понять FrontierMath и увидеть, как она подрывает наше понимание математических возможностей ИИ.
В огромной вселенной искусственного интеллекта математика когда-то считалась последним бастионом машинного интеллекта. Сегодня появился новый эталонный тест под названием FrontierMath, который расширяет возможности математического рассуждения ИИ до беспрецедентных пределов.
Epoch AI объединила усилия с более чем 60 ведущими умами математического мира, чтобы совместно создать поле испытаний ИИ, которое можно назвать Математической олимпиадой. Это не только технический тест, но и высшая проверка математической мудрости искусственного интеллекта.
Представьте себе лабораторию, наполненную лучшими математиками мира, которые создали сотни математических головоломок, превосходящих воображение обычных людей. Эти проблемы охватывают самые передовые математические области, такие как теория чисел, реальный анализ, алгебраическая геометрия и теория категорий, и имеют ошеломляющую сложность. Даже гению математики, обладателю золотой медали Международной математической олимпиады, нужны часы или даже дни, чтобы решить задачу.
Поразительно, но современные модели искусственного интеллекта показали неутешительные результаты в этом тесте: ни одна модель не смогла решить более 2% проблем. Этот результат был словно тревожным звонком и дал ИИ пощечину.
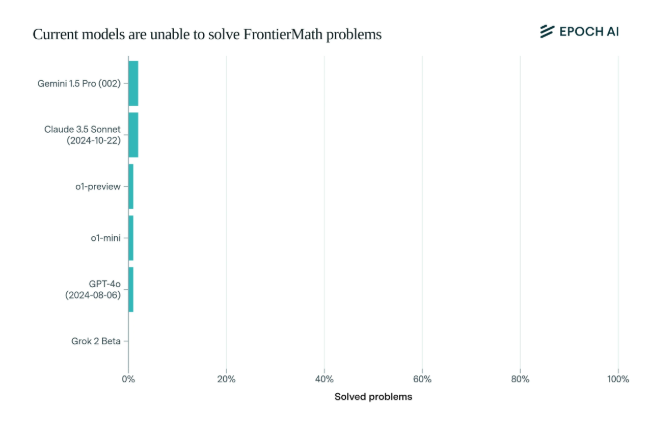
Уникальность FrontierMath заключается в строгом механизме оценки. Традиционные тесты математических тестов, такие как MATH и GSM8K, были максимально расширены искусственным интеллектом, и этот новый тест использует новые, неопубликованные вопросы и автоматизированную систему проверки, чтобы эффективно избежать загрязнения данных и по-настоящему проверить возможности математического рассуждения ИИ.
Флагманские модели ведущих компаний в области искусственного интеллекта, такие как OpenAI, Anthropic и Google DeepMind, которые привлекли большое внимание, в совокупности потерпели неудачу в этом тесте. Это отражает глубокую техническую философию: для компьютеров кажущиеся сложными математические задачи могут быть простыми, но задачи, которые люди считают простыми, могут сделать ИИ беспомощным.
Как сказал Андрей Карпати, это подтверждает парадокс Моравца: сложность интеллектуальных задач между людьми и машинами часто противоречит здравому смыслу. Этот эталонный тест является не только тщательным исследованием возможностей ИИ, но и катализатором эволюции ИИ в более высокие измерения.
Для математического сообщества и исследователей искусственного интеллекта FrontierMath — это непокорённая гора Эверест. Он не только проверяет знания и навыки, но также проверяет проницательность и творческое мышление. В будущем тот, кто сможет возглавить восхождение на эту вершину интеллекта, будет записан в историю развития искусственного интеллекта.
Появление эталонного теста FrontierMath является не только серьезной проверкой существующего уровня технологий ИИ, но и указывает направление будущего развития ИИ. Оно указывает на то, что ИИ еще предстоит пройти долгий путь в области математических рассуждений. это также стимулирует исследования. Исследователи продолжают исследовать и внедрять инновации, чтобы преодолеть узкие места существующих технологий.