Редактор Downcodes поможет вам разобраться в тревожном явлении в сфере ИИ — коллапсе моделей. Представьте себе, что модель ИИ похожа на кулинарного блогера, который начинает есть еду, которую готовит, тем больше он к ней пристрастился, и еда становится все более и более невкусной. В конце концов, он становится «плохим». это когда модель рушится. Это происходит, когда модель ИИ слишком сильно полагается на генерируемые ею данные, что приводит к снижению качества модели или даже к ее полному провалу. В этой статье мы углубимся в причины, последствия и способы избежать коллапса модели.
Недавно в кругу ИИ произошла странная вещь: например, кулинарный блоггер внезапно начал есть приготовленную им еду, и чем больше он ел, тем больше у него становилась зависимость, и еда становилась все более и более неприятной. Об этом страшно говорить. Профессиональный термин называется коллапсом модели.
Что такое коллапс модели? Проще говоря, если модель ИИ использует большое количество самостоятельно сгенерированных данных в процессе обучения, она попадает в порочный круг, в результате чего качество генерации модели становится все хуже и хуже, и, в конечном итоге, качество создания модели становится все хуже и хуже. неудача.
Это похоже на закрытую экосистему. Модель ИИ — единственное живое существо в этой системе, а пища, которую она производит, — это данные. Вначале он все еще мог найти некоторые натуральные ингредиенты (реальные данные), но со временем он начал все больше и больше полагаться на «искусственные» ингредиенты, которые он производил (синтетические данные). Проблема в том, что эти «искусственные» ингредиенты имеют дефицит питательных веществ и несут в себе некоторые недостатки самой модели. Если вы съедите слишком много, «тело» модели ИИ рухнет, а создаваемые вещи будут становиться все более и более возмутительными.
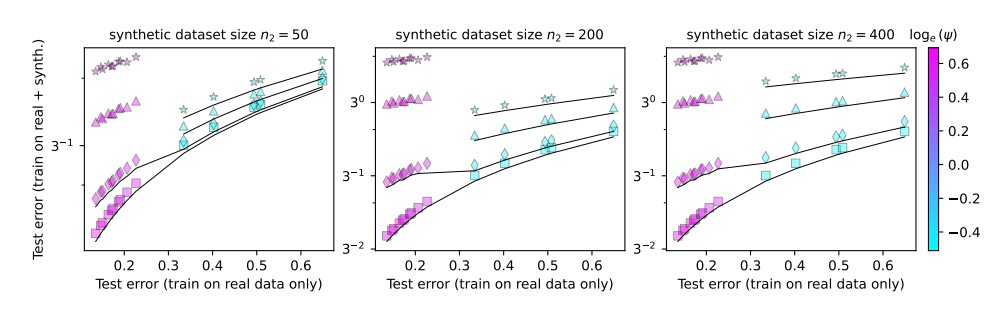
В данной статье изучается явление коллапса модели и делается попытка ответить на два ключевых вопроса:
Неизбежен ли крах модели? Можно ли решить проблему, смешав реальные и синтетические данные?
Чем больше модель, тем легче ее разбить?
Чтобы изучить эти вопросы, авторы статьи разработали серию экспериментов и использовали модель случайных проекций для моделирования процесса обучения нейронной сети. Они обнаружили, что использование даже небольшой части синтетических данных (скажем, 1%) может привести к краху модели. Что еще хуже, по мере увеличения размера модели явление коллапса модели становится более серьезным.
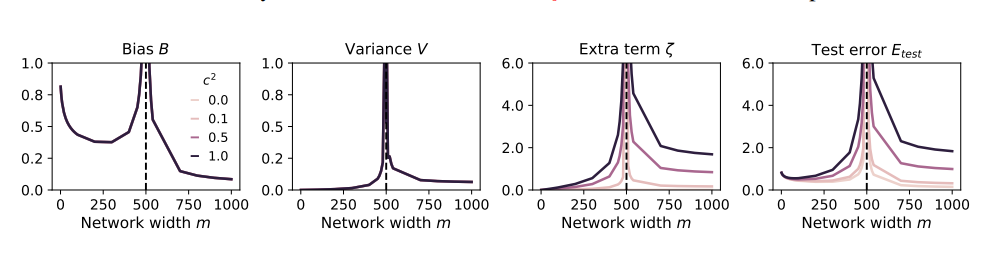
Это похоже на кулинарного блоггера, который начал пробовать всевозможные странные ингредиенты, чтобы привлечь внимание, но в итоге у него заболел желудок. Чтобы возместить потери, он мог только увеличить потребление пищи и есть все более и более странные вещи. В результате его желудок становился все хуже и хуже, и ему, наконец, пришлось бросить мир еды и радиовещания.
Итак, как нам избежать коллапса модели?
Авторы статьи высказали несколько предложений:
Отдавайте приоритет использованию реальных данных. Реальные данные подобны натуральной пище, богатой питательными веществами, и являются ключом к здоровому развитию моделей ИИ.
Используйте синтетические данные с осторожностью: синтетические данные подобны искусственной пище. Хотя они могут дополнять некоторые питательные вещества, вам не следует слишком полагаться на них, иначе это будет контрпродуктивно.
Контролируйте размер модели: чем больше модель, тем больше аппетит и тем легче заболеть желудок. При использовании синтетических данных контролируйте размер модели, чтобы избежать перегрузки.
Коллапс модели — это новая проблема, возникающая в процессе разработки ИИ. Она напоминает нам, что, стремясь к масштабу и эффективности модели, мы также должны уделять внимание качеству данных и работоспособности модели. Только таким образом модели ИИ смогут продолжать развиваться здоровым образом и создавать большую ценность для человеческого общества.
Документ: https://arxiv.org/pdf/2410.04840.
В целом, коллапс модели — это проблема, заслуживающая внимания при разработке ИИ. Нам необходимо с осторожностью относиться к синтетическим данным, обращать внимание на качество реальных данных и контролировать масштаб модели, чтобы избежать явления «ИИ». слишком много ем». Я надеюсь, что этот анализ поможет каждому лучше понять крах модели и внести вклад в здоровое развитие ИИ.