Редактор Downcodes приносит вам большие новости! В сфере искусственного интеллекта появился новый участник — Zyphra официально выпустила свою небольшую языковую модель Zamba2-7B! Эта модель с 7 миллиардами параметров достигла прорыва в производительности, особенно с точки зрения эффективности и адаптируемости, продемонстрировав впечатляющие преимущества. Он не только подходит для высокопроизводительных вычислительных сред, но, что более важно, Zamba2-7B также может работать на графических процессорах потребительского уровня, что позволяет большему количеству пользователей легко ощутить очарование передовых технологий искусственного интеллекта. В этой статье мы углубимся в инновации Zamba2-7B и их влияние на область обработки естественного языка.
Недавно Zyphra официально выпустила Zamba2-7B, небольшую языковую модель с беспрецедентной производительностью, с количеством параметров, достигающим 7B.
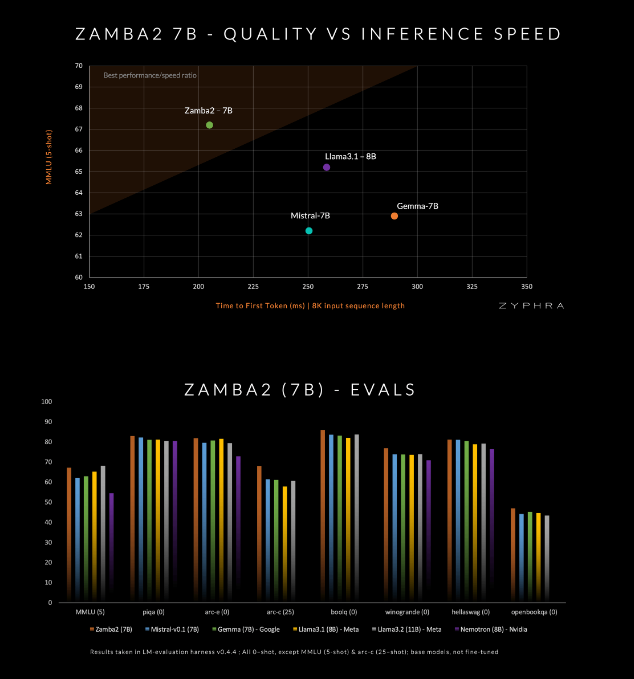
Эта модель претендует на то, чтобы превосходить нынешних конкурентов по качеству и скорости, включая Mistral-7B, Gemma-7B от Google и Llama3-8B от Meta.
Zamba2-7B разработан для удовлетворения потребностей сред, которые требуют мощных возможностей языковой обработки, но ограничены аппаратными условиями, такими как обработка на устройстве или использование графических процессоров потребительского уровня. Повышая эффективность без ущерба для качества, Zyphra надеется дать возможность более широкому кругу пользователей, будь то предприятия или отдельные разработчики, насладиться удобством передового искусственного интеллекта.
Zamba2-7B внесла множество инноваций в свою архитектуру для повышения эффективности и возможностей модели. В отличие от модели Zamba1 предыдущего поколения, Zamba2-7B использует два блока общего внимания. Эта конструкция может лучше обрабатывать зависимости между потоком информации и последовательностями.
Блок Mamba2 образует ядро всей архитектуры, что делает использование параметров модели выше, чем у традиционных моделей преобразователей. Кроме того, Zyphra также использует проекцию адаптации низкого ранга (LoRA) на общих блоках MLP, что еще больше улучшает адаптивность каждого уровня, сохраняя при этом компактность модели. Благодаря этим нововведениям время первого ответа Zamba2-7B сократилось на 25%, а количество обрабатываемых токенов в секунду увеличилось на 20%.
Эффективность и адаптируемость Zamba2-7B были проверены тщательными испытаниями. Модель предварительно обучена на огромном наборе данных, содержащем три триллиона токенов, которые представляют собой высококачественные и тщательно проверенные открытые данные.
Кроме того, Zyphra также представляет этап предварительного обучения, который быстро снижает скорость обучения для более эффективной обработки токенов высокого качества. Эта стратегия позволяет Zamba2-7B хорошо работать в тестах, превосходя конкурентов по скорости и качеству вывода, и подходит для таких задач, как понимание и генерация естественного языка, не требуя огромных вычислительных ресурсов, необходимых для традиционных высококачественных моделей.
amba2-7B представляет собой значительное достижение в области небольших языковых моделей, сохраняя высокое качество и производительность, уделяя при этом особое внимание доступности. Благодаря инновационному архитектурному дизайну и эффективной технологии обучения Zyphra успешно создала модель, которая не только проста в использовании, но и может удовлетворить различные потребности в обработке естественного языка. Релиз Zamba2-7B с открытым исходным кодом приглашает исследователей, разработчиков и предприятия изучить его потенциал и, как ожидается, будет способствовать развитию передовой обработки естественного языка в более широком сообществе.
Вход в проект: https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Выпуск Zamba2-7B с открытым исходным кодом вдохнул новую жизнь в область обработки естественного языка и предоставил разработчикам больше возможностей. Мы надеемся, что Zamba2-7B будет более широко использоваться в будущем и будет способствовать дальнейшему развитию технологий искусственного интеллекта!