Редактор Downcodes узнал, что ученые из Меты, Калифорнийского университета в Беркли и Нью-Йоркского университета совместно разработали новую технологию под названием «Оптимизация предпочтений мышления» (TPO), направленную на повышение производительности больших языковых моделей (LLM). Эта технология улучшает «мыслительные» способности ИИ, позволяя модели генерировать серию мыслительных шагов перед ответом на вопрос, а также использует модель оценки для оптимизации качества окончательного ответа, что позволяет ей лучше справляться с различными задачами. В отличие от традиционной технологии «цепного мышления», TPO имеет более широкий спектр применения, особенно демонстрируя значительные преимущества в творческом письме, рассуждениях на основе здравого смысла и т. д.
Недавно ученые из Меты, Калифорнийского университета, Беркли и Нью-Йоркского университета совместно разработали новую технологию под названием «Оптимизация предпочтений мышления» (TPO). Цель этой технологии — повысить производительность больших языковых моделей (LLM) при выполнении различных задач, позволяя ИИ более тщательно обдумывать свои ответы перед ответом.
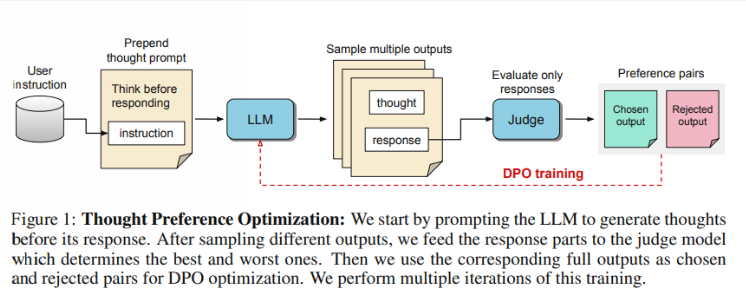
Исследователи говорят, что мышление должно иметь широкую полезность. Например, при выполнении творческих писательских задач ИИ может использовать внутренние мыслительные процессы для планирования общей структуры и развития персонажа. Этот метод существенно отличается от предыдущей технологии подсказок «Цепочка мыслей» (ЦП). Последний в основном используется в математических и логических задачах, тогда как ТПО имеет более широкий спектр применения. Исследователи упомянули новую модель o1 OpenAI и полагают, что процесс мышления также полезен для более широкого круга задач.
Итак, как работает TPO? Во-первых, модель генерирует серию мыслительных шагов, прежде чем ответить на вопрос. Затем он создает несколько выходных данных, которые затем оцениваются моделью оценки только по окончательному ответу, а не по самим шагам мышления. Наконец, модель обучается посредством оптимизации предпочтений этих результатов оценки. Исследователи надеются, что улучшения качества ответов можно добиться за счет улучшения мыслительного процесса, благодаря чему модель сможет получить более эффективные возможности рассуждения при неявном обучении.
При тестировании модель Llama38B, использующая TPO, показала лучшие результаты при выполнении общих инструкций, следующих за тестом, чем версия без явного вывода. В тестах AlpacaEval и Arena-Hard процент выигрышей TPO достиг 52,5% и 37,3% соответственно. Еще более интересно то, что TPO также добивается прогресса в областях, которые обычно не требуют четкого мышления, таких как здравый смысл, маркетинг и здравоохранение.
Однако исследовательская группа отметила, что текущая установка не подходит для математических задач, поскольку TPO фактически справляется с этими задачами хуже, чем базовая модель. Это говорит о том, что для узкоспециализированных задач может потребоваться другой подход. Будущие исследования могут быть сосредоточены на таких аспектах, как контроль длины мыслительных процессов и влияние мышления на более крупные модели.
Выделять:
Исследовательская группа запустила «Оптимизацию предпочтений мышления» (TPO), целью которой является улучшение мыслительных способностей ИИ при выполнении задач.
? TPO использует модели оценки для оптимизации качества ответов, позволяя модели генерировать мыслительные шаги перед ответом.
Тесты показали, что ОСРТ хорошо справляются с такими областями, как общие знания и маркетинг, но плохо справляются с математическими задачами.
В целом, технология TPO открывает новое направление для совершенствования больших языковых моделей, и ее потенциал в улучшении возможностей мышления ИИ стоит с нетерпением ждать. Однако эта технология также имеет ограничения, и будущие исследования требуют дальнейшего совершенствования и расширения сферы ее применения. Редактор Downcodes продолжит обращать внимание на последние разработки в этой области и предлагать читателям еще больше интересных отчетов.