Редактор Downcodes узнал, что Alibaba Damo Academy и Китайский университет Жэньминь совместно открыли исходный код модели обработки документов под названием mPLUG-DocOwl1.5. Модель может понимать содержимое документа без распознавания OCR и хорошо работает в многочисленных тестах производительности. Ее суть заключается в методе «обучения унифицированной структуры», который улучшает структурное понимание изображений форматированного текста в мультимодальной модели большого языка (MLLM). . Модель опубликовала код, модели и наборы данных на GitHub, предоставляя ценные ресурсы для исследований в смежных областях.
Академия Alibaba Damo и Китайский университет Жэньминь недавно совместно открыли исходный код модели обработки документов под названием mPLUG-DocOwl1.5. Эта модель ориентирована на понимание содержимого документа без распознавания OCR и добилась результатов в нескольких тестах производительности визуального понимания документов.
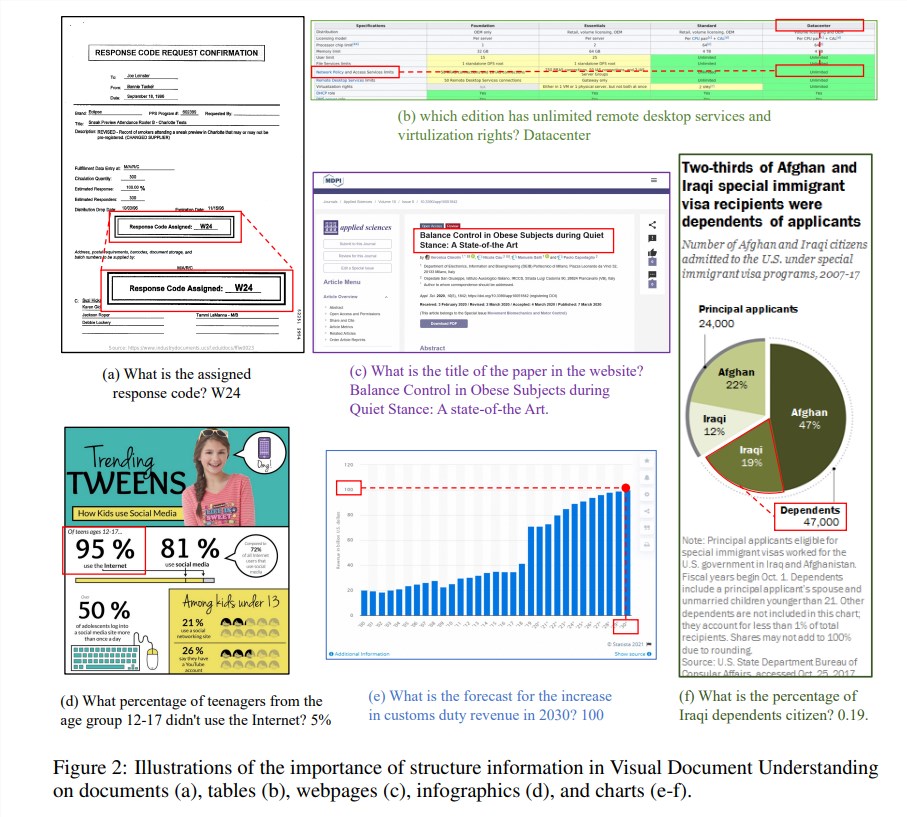
Структурная информация имеет решающее значение для понимания семантики текстовых изображений, таких как документы, таблицы и диаграммы. Хотя существующие мультимодальные модели большого языка (MLLM) обладают возможностями распознавания текста, им не хватает способности понимать общую структуру изображений документов с форматированным текстом. Чтобы решить эту проблему, mPLUG-DocOwl1.5 подчеркивает важность структурной информации для понимания визуального документа и предлагает «обучение унифицированной структуры» для повышения производительности MLLM.
«Обучение единой структуры» модели охватывает 5 областей: документы, веб-страницы, таблицы, диаграммы и естественные изображения, включая задачи синтаксического анализа с учетом структуры и задачи многоуровневого позиционирования текста. Чтобы лучше кодировать структурную информацию, исследователи разработали простой и эффективный модуль преобразования визуального изображения в текст H-Reducer, который не только сохраняет информацию о макете, но и уменьшает длину визуальных элементов путем объединения соседних по горизонтали фрагментов изображения посредством свертки. большие языковые модели для более эффективного понимания изображений с высоким разрешением.
Кроме того, для поддержки структурного обучения исследовательская группа создала DocStruct4M, комплексный обучающий набор, содержащий 4 миллиона образцов на основе общедоступных наборов данных, который содержит текстовые последовательности с учетом структуры и пары ограничивающих рамок текста с различной степенью детализации. Чтобы еще больше стимулировать возможности MLLM по рассуждению в области документов, они также создали набор данных для точной настройки рассуждений DocReason25K, содержащий 25 000 высококачественных образцов.
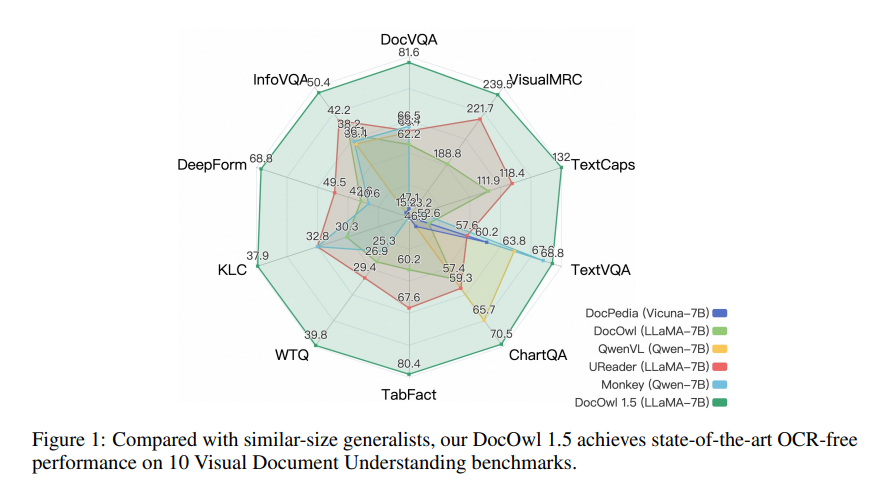
mPLUG-DocOwl1.5 использует двухэтапную структуру обучения, которая сначала выполняет обучение единой структуры, а затем выполняет многозадачную точную настройку в нескольких последующих задачах. Благодаря этому методу обучения mPLUG-DocOwl1.5 достиг высочайшего уровня производительности в 10 тестах на понимание визуальных документов, улучшив производительность SOTA 7B LLM более чем на 10 процентных пунктов в 5 тестах.
В настоящее время код, модель и набор данных mPLUG-DocOwl1.5 публично опубликованы на GitHub.
Адрес проекта: https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Адрес статьи: https://arxiv.org/pdf/2403.12895.
Открытый исходный код mPLUG-DocOwl1.5 открывает новые возможности для исследований и применения в области визуального понимания документов. Его эффективная работа и удобные методы доступа заслуживают внимания и использования разработчиков. Ожидается, что в будущем эту модель можно будет использовать в более практических сценариях.