Редактор Downcodes познакомит вас с последними результатами исследований Швейцарского федерального технологического института в Лозанне (EPFL)! В этом исследовании проводится углубленное сравнение двух основных методов адаптивного обучения для больших языковых моделей (LLM): контекстное обучение (ICL) и точная настройка инструкций (IFT), а также используется тест MT-Bench для оценки способности модели следовать инструкции. Результаты исследования показывают, что оба метода имеют свои преимущества в разных сценариях, что дает ценную информацию для выбора методов обучения LLM.
В недавнем исследовании Федеральной политехнической школы Лозанны (EPFL) в Швейцарии сравнивались два основных метода адаптивного обучения для больших языковых моделей (LLM): контекстное обучение (ICL) и точная настройка инструкций (IFT). Исследователи использовали тест MT-Bench для оценки способности модели следовать инструкциям и обнаружили, что оба метода работают лучше или хуже при определенных обстоятельствах.
Исследования показали, что когда количество доступных обучающих выборок невелико (например, не более 50), эффекты ICL и IFT очень близки. Это говорит о том, что ICL может быть альтернативой IFT, когда данные ограничены.
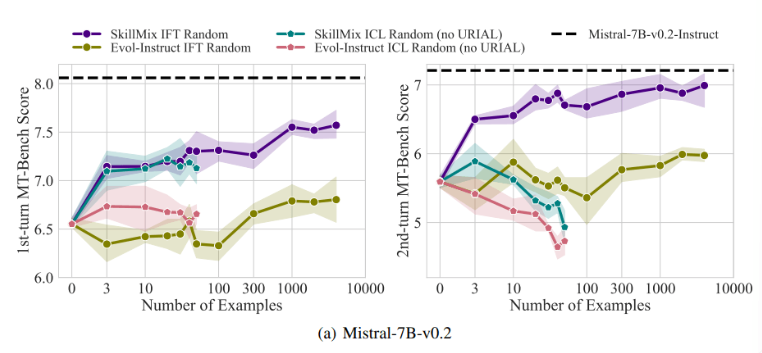
Однако по мере увеличения сложности задачи, например, в сценариях многоходового диалога, преимущества IFT становятся очевидными. Исследователи полагают, что модель ICL склонна к переподгонке под стиль одной выборки, что приводит к снижению производительности при обработке сложных разговоров или даже к худшему результату, чем у базовой модели.
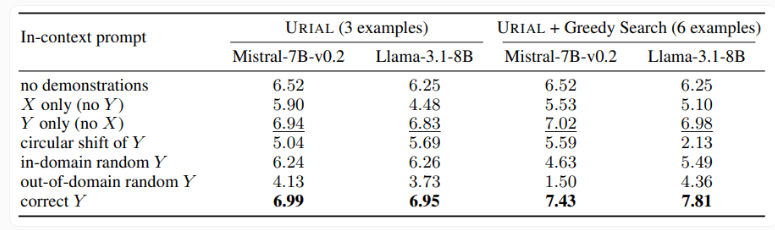
В исследовании также был изучен метод URIAL, который использует только три образца и инструкции для следования правилам при обучении модели базового языка. Хотя URIAL достиг определенных результатов, все еще существует разрыв по сравнению с моделью, обученной IFT. Исследователи EPFL улучшили производительность URIAL, улучшив стратегию отбора выборки, приблизив ее к моделям точной настройки. Это подчеркивает важность высококачественных обучающих данных для ICL, IFT и базового обучения моделей.
Кроме того, исследование также показало, что параметры декодирования оказывают существенное влияние на производительность модели. Эти параметры определяют, как модель генерирует текст, и имеют решающее значение как для базового LLM, так и для моделей, обученных с помощью URIAL.
Исследователи отмечают, что даже базовая модель может в определенной степени следовать инструкциям при подходящих параметрах декодирования.
Значение этого исследования заключается в том, что оно показывает, что контекстное обучение может быстро и эффективно настраивать языковые модели, особенно когда обучающие выборки ограничены. Но для сложных задач, таких как многоходовые разговоры, точная настройка команд все же является лучшим выбором.
По мере увеличения размера набора данных производительность IFT будет продолжать улучшаться, а производительность ICL стабилизируется после достижения определенного количества выборок. Исследователи подчеркивают, что выбор между ICL и IFT зависит от множества факторов, таких как доступные ресурсы, объем данных и требования конкретного приложения. Какой бы метод вы ни выбрали, решающее значение имеют высококачественные данные обучения.
В целом, это исследование EPFL дает новое понимание выбора методов обучения для больших языковых моделей и указывает путь для будущих направлений исследований. Выбор ICL или IFT требует взвешивания плюсов и минусов с учетом конкретной ситуации, и ключом всегда являются высококачественные данные. Мы надеемся, что это исследование поможет каждому лучше понять и применять большие языковые модели.